HT1121 网页爬虫工具 Photon 的简单使用
Posted 信安之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HT1121 网页爬虫工具 Photon 的简单使用相关的知识,希望对你有一定的参考价值。
通过网络爬虫获取目标相关域名资产信息,其根源主要是企业为了方便客户访问不同产品而在网站上提供跳转链接,通过访问网站的内容,然后抓取其中的 URL,再根据 URL 来获取其内容,再一次获取其中的 URL,不断发散下去。
https://github.com/s0md3v/Photon
Python 运行环境要求版本大于等于 3.2,下载安装方式:
git clone https://github.com/s0md3v/Photon && cd Photon && pip3.8 install -r requirements.txt
首次运行该程序如图:
python3.8 photon.py
查看帮助文档,还是有不少功能,先试用最基本的爬虫功能,参数如下:
python3.8 photon.py -u https://www.xazlsec.com -t 100 -l 3 -r [a-zA-Z0-9-]+\.xazlsec\.com
-t 指定线程数,-l 指定爬取深度,-u 指定开始 URL,-r指定匹配关键信息的正则
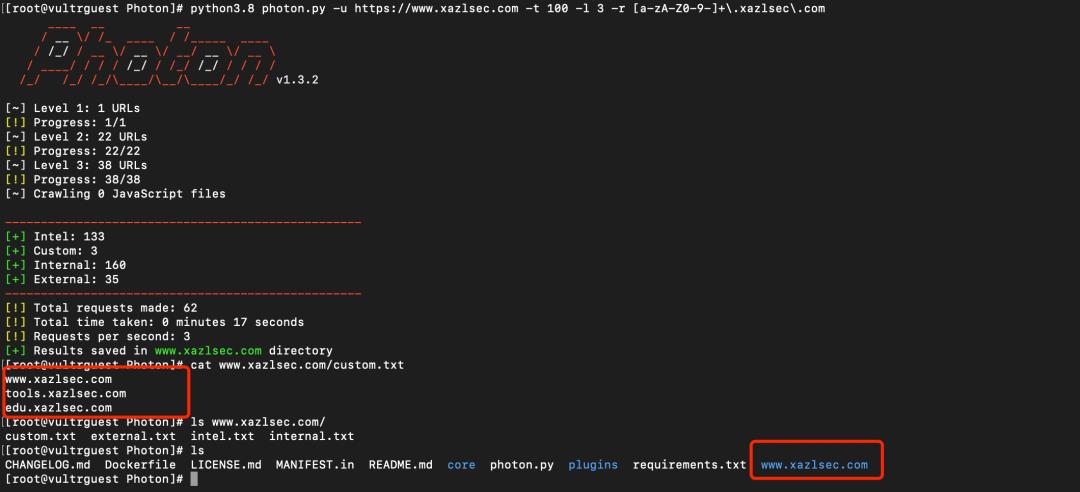
程序跑完之后会将所有结果保存至目标域名的目录下,custom.txt 中是我们指定的正则匹配出的内容去重后的结果,还有其他内容,比如:外链、内链、文件URL等。
除了爬虫功能,还有几个插件,wayback 可以搜索 https://archive.org/ 上与目标相关的链接,dns可以从 https://dnsdumpster.com 搜索目标相关域名信息,并保存其 DNS 映射关系图。
最后测试一下 dns 这个插件功能,命令如下:
python3.8 photon.py -u https://www.xazlsec.com -t 100 -l 1 --dns
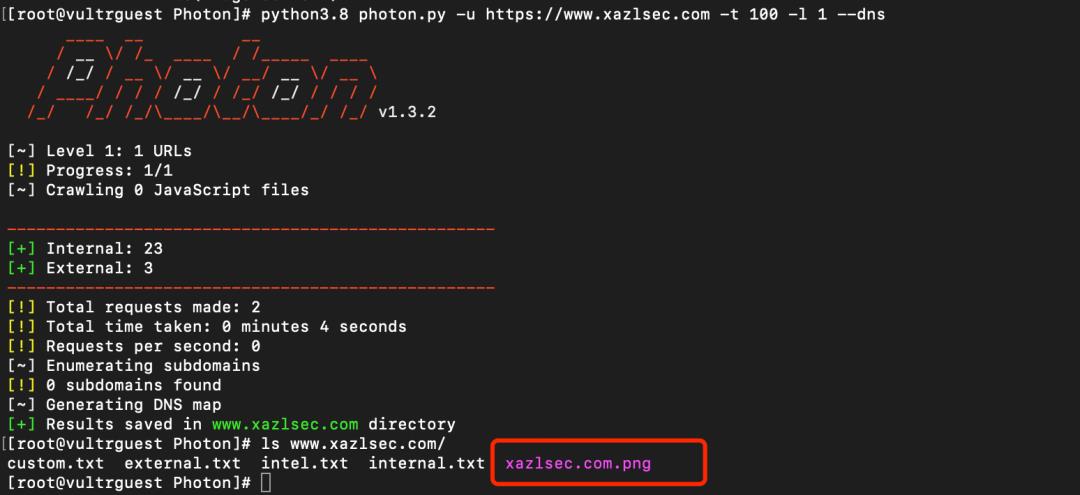
查看图像:
这个工具的使用分享就到这,这类工具开源的也不少,自己开发也不是问题,直接使用的话,比较适合新手,没有编码基础,将工具使用能力发挥到极致同样可以解决问题,除了这种基础的爬虫之外,有些网站使用了微服务架构,前端使用 js 框架自动请求 json 接口获取数据进行展示,使用这种基础的静态爬虫是无法获取到数据的,那么就需要使用一些动态爬虫,利用无头浏览器请求页面,获取网站数据。
网页爬虫的原理不难,难的是与完整的反爬虫策略的对抗,比如频率限制、请求次数限制,由于反爬虫统计信息需要一个关键指纹,比如 User-Agent、IP、Token 等,通过不断变换指纹信息可以达到绕过反爬虫的目的,比如随机 UA、代理 IP、随机 Token 等方式。
如果你有更好用的开源爬虫工具,请留言交流!
以上是关于HT1121 网页爬虫工具 Photon 的简单使用的主要内容,如果未能解决你的问题,请参考以下文章