python:网络爬虫的学习笔记
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python:网络爬虫的学习笔记相关的知识,希望对你有一定的参考价值。
如果要爬取的内容嵌在网页源代码中的话,直接下载网页源代码再利用正则表达式来寻找就ok了。下面是个简单的例子:
1 import urllib.request 2 3 html = urllib.request.urlopen(‘http://www.massey.ac.nz/massey/learning/programme-course/programme.cfm?prog_id=93536‘) 4 html = html.read().decode(‘utf-8‘)
注意,decode方法有时候可能会报错,例如
1 html = urllib.request.urlopen(‘http://china.nba.com/‘) 2 3 html = html.read().decode(‘utf-8‘) 4 Traceback (most recent call last): 5 6 File "<ipython-input-6-fc582e316612>", line 1, in <module> 7 html = html.read().decode(‘utf-8‘) 8 9 UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xd6 in position 85: invalid continuation byte
具体原因不知道,可以用decode的一个参数,如下
1 html = html.read().decode(‘utf-8‘,‘replace‘) 2 3 html = urllib.request.urlopen(‘http://china.nba.com/‘) 4 html = html.read().decode(‘utf-8‘,‘replace‘) 5 6 html 7 Out[9]: ‘<!DOCTYPE html>\\r\\n<html>\\r\\n<head lang="en">\\r\\n <meta charset="UTF-8">\\r\\n <title>NBA?й???????</title>\\r\\n <meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1">\\r\\n <meta name="description" content="NBA?й???????">\\r\\n <meta name="keywords"
replace表示遇到不能转码的字符就将其替换成问号还是什么的。。。这也算是一个折中的方法吧。我们继续回到正题。假如说我们想爬取上面提到的网页的课程名称
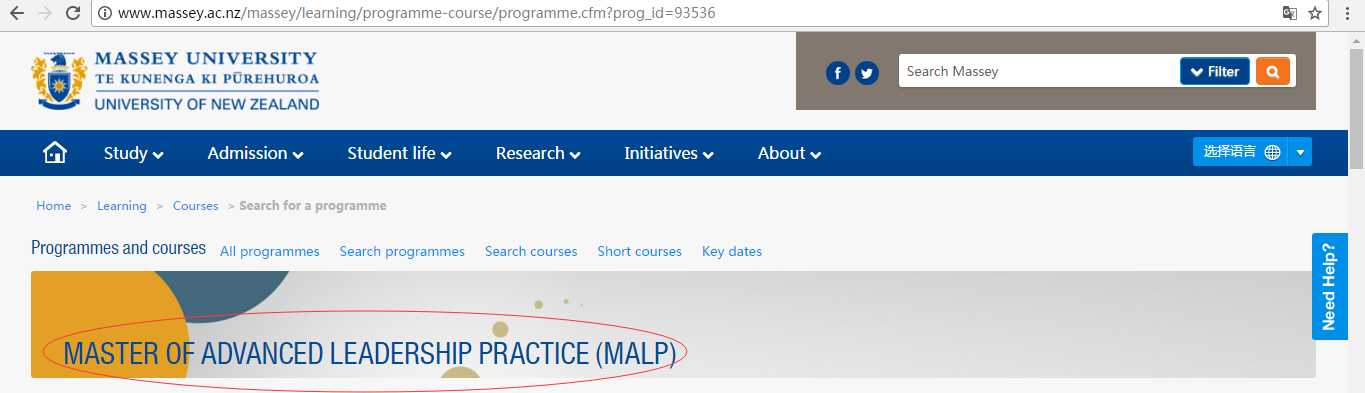
查看网页源代码。我用的谷歌浏览器,右键单击页面,再选择‘查看网页源代码’

再在这个页面上ctrl+F,查找你要爬取的字符:
这个就刚才截图所对应的代码(想看懂源代码还得学习一下html语言啊 http://www.w3school.com.cn/html/index.asp 这个网址挺不错的)
接下来就是用正则表达式把这个字符串扣下来了:
1 re.findall(‘<h1>.*?</h1>‘,html) 2 Out[35]: [‘<h1>Master of Advanced Leadership Practice (<span>MALP</span>)</h1>‘]
剩下的就是对字符串的切割了:
1 course = re.findall(‘<h1>.*?</h1>‘,html) 2 course = str(course[0]) 3 course = course.replace(‘<h1>‘,‘‘) 4 course = course.replace(‘(<span>MALP</span>)</h1>‘,‘‘)
结果:
1 course = re.findall(‘<h1>.*?</h1>‘,html) 2 3 course = str(course[0]) 4 5 course = course.replace(‘<h1>‘,‘‘) 6 7 course = course.replace(‘ (<span>MALP</span>)</h1>‘,‘‘) 8 9 course 10 Out[40]: ‘Master of Advanced Leadership Practice‘
把它写成一个函数:
1 def get_course(url): 2 html = urllib.request.urlopen(url) 3 html = html.read().decode(‘utf-8‘) 4 course = re.findall(‘<h1>.*?</h1>‘,html) 5 course = str(course[0]) 6 course = course.replace(‘<h1>‘,‘‘) 7 course = course.replace(‘ (<span>MALP</span>)</h1>‘,‘‘) 8 return course
这样输入该学校的其他课程的网址,同样也能把那个课程的名称扣下来(语文不好,请见谅)
1 get_course(‘http://www.massey.ac.nz/massey/learning/programme-course/programme.cfm?prog_id=93059‘) 2 Out[48]: ‘Master of Counselling Studies (<span>MCounsStuds</span>)</h1>‘
这就很尴尬了,原因是第二个replace函数,pattern是错误的,看来还得用正则改一下
1 def get_course(url): 2 html = urllib.request.urlopen(url) 3 html = html.read().decode(‘utf-8‘) 4 course = re.findall(‘<h1>.*?</h1>‘,html) 5 course = str(course[0]) 6 course = course.replace(‘<h1>‘,‘‘) 7 repl = str(re.findall(‘ \\(<span>.*?</span>\\)</h1>‘,course)[0]) 8 course = course.replace(repl,‘‘) 9 return course
再试试
1 get_course(‘http://www.massey.ac.nz/massey/learning/programme-course/programme.cfm?prog_id=93059‘) 2 Out[69]: ‘Master of Counselling Studies‘
搞定!
其实可以用BeautifulSoup直接解析源代码,使得查找定位更快。下一篇在说吧
这其实是我在广州第一份工作要干的活,核对网址是否存在,是否还是原来的课程。那个主管要人工核对。。。1000多个网址,他说他就是自己人工核对的,哈哈,我可不愿意干这活。当时也尝试用R语言去爬取课程名,试了很久。。。比较麻烦吧,后来学了python。现在要核对的话估计十分钟就能搞定1000多个网址了吧。就想装个b,大家可以无视
以上是关于python:网络爬虫的学习笔记的主要内容,如果未能解决你的问题,请参考以下文章