Python学习笔记——与爬虫相关的网络知识
Posted gengyi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python学习笔记——与爬虫相关的网络知识相关的知识,希望对你有一定的参考价值。
1 关于URL
URL(Uniform / Universal Resource Locator):统一资源定位符,用于完整地描述Internet上网页和其他资源的地址的一种标识方法
URL是爬虫的入口,——非常重要
基本格式:
scheme://host[:port# ]/path/.../[?query-string][#anchor]
scheme:协议(例如:http、https、ftp)
host:服务器的IP地址或域名
port#:服务器端口(协议默认端口80,可缺省)
path:访问资源的路径
query-string:发送给http服务器的数据
anchor:锚(转跳到网页的指定锚点位置)
示例:
http://www.baidu.com
http://item.jd.com/11963485.html#product-detail
ftp://192.168.1.118:8081/index
2 HTTP协议、HTTPS协议
2.1 HTTP协议
HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收HTML页面的方法。HTTP协议是一个应用层的协议,无连接(每次连接只处理一个请求),无状态(每次连接,传输都是独立的)
2.2 HTTPS协议
HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)协议简单讲是HTTP的安全版,在HTTP下加入SSL层。HTTPS = HTTP+SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全
注:
HTTP的端口号为80;HTTPS的端口号为443;
3 HTTP Request请求
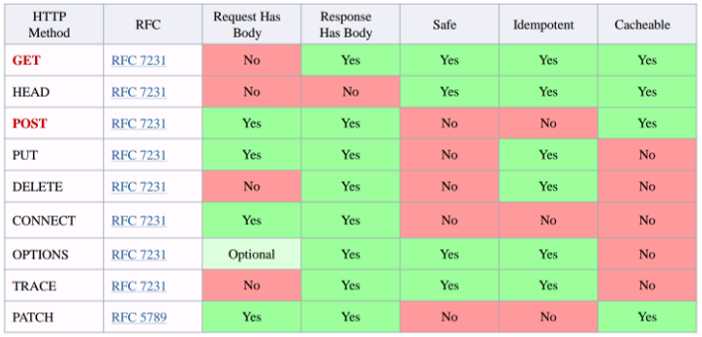
HTTP请求常用的两种方法:
(1)Get:“获取”,是为了从服务器上获取信息,传输给服务器的数据的过程不够安全,数据大小有限制;
(2)Post:“发送”,向服务器传递数据,传输数据的过程是安全的,大小理论上没有限制;
HTTP其他请求方法:
4 User-Agent 用户代理
http header的User-Agent(简称UA)译为用户代理,是头域的组成部分,是一个特殊字符串头,是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。通过这个标识,用户所访问的网站可以显示不同的排版从而为用户提供更好的体验或者进行信息统计;例如用手机访问谷歌和电脑访问是不一样的,这些是谷歌根据访问者的UA来判断的。
UA可以进行伪装。也即可以用于伪装爬虫程序
浏览器的UA字串的标准格式:浏览器标识(操作系统标识;加密等级标识;浏览器语言)渲染引擎标识版本信息。但各个浏览器有所不同。
备注:出于兼容及推广等目的,很多浏览器的标识相同,因此浏览器标识并不能说明浏览器的真实版本,真实版本信息在UA字串尾部可以找到。
User-Agent:Mozilla/5.0 (Windows NT 10.0; …) Gecko/20100101 Firefox/59.0
可以通过软件 Fiddler 、wireshark等实现网络抓包
关于抓包工具的详细阐述网络抓包wireshark
5 HTTP Response响应的状态码
2、状态码
根据响应结果的类型,大致分为以下几类:
2.1 1XX(信息类)
该类型状态码表示接收到请求并且继续处理。
- 100,客户端必须继续发出请求。
- 101,客户端要求服务器根据请求转换HTTP协议版本。
2.2 2XX(响应成功)
该类型状态码表示动作被成功接收、理解和接受。
- 200,表明该请求被成功地完成,所请求的资源发送到客户端。
- 201,提示知道新文件的URL。
- 202,接受并处理,但处理未完成。
- 203,返回信息不确定或不完整。
- 204,收到请求,但返回信息为空。
- 205,服务器完成了请求,用户必须复位当前已经浏览过的文件。
- 206,服务器已经完成了部分用户的GET请求。
2.3 3XX(重定向类)
该类型状态码表示为了完成指定的动作,必须接受进一步处理。
- 300,请求的资源可在多处获得。
- 301,本网页被永久性转移到另一个URL。
- 302,请求的网页被重定向到新的地址。
- 303,建议用户访问其他URL或访问方式。
- 304,自从上次请求后,请求的网页未修改过。
- 305,请求的资源必须从服务器指定的地址获得。
- 306,前一版本HTTP中使用的代码,现已不再使用。
- 307,声明请求的资源临时性删除。
2.4 4XX(客户端错误类)
该类型状态码表示请求包含错误语法或不能正确执行。
- 400,客户端请求有语法错误。
- 401,请求未经授权。
- 402,保留有效ChargeTo头响应。
- 403,禁止访问,服务器收到请求,但拒绝提供服务。
- 404,可连接服务器,但服务器无法取得所请求的网页,请求资源不存在。
- 405,用户在Request-Line字段定义的方法不被允许。
- 406,根据用户发送的Accept,请求资源不可访问。
- 407,类似401,用户必须首先在代理服务器上取得授权。
- 408,客户端没有在用户指定的时间内完成请求。
- 409,对当前资源状态,请求不能完成。
- 410,服务器上不再有此资源。
- 411,服务器拒绝用户定义的Content-Length属性请求。
- 412,一个或多个请求头字段在当前请求中错误。
- 413,请求的资源大于服务器允许的大小。
- 414,请求的资源URL长于服务器允许的长度。
- 415,请求资源不支持请求项目格式。
- 416,请求中包含Range请求头字段,在当前请求资源范围内没有range指示值。
- 417,服务器不满足请求Expect头字段指定的期望值。
2.5 5XX(服务器错误类)
该类型状态码表示服务器或网关错误。
- 500,服务器错误。
- 501,服务器不支持请求的功能。
- 502,网关错误。
- 503,无法获得服务。
- 504,网关超时。
- 505,不支持的http版本。
3、响应头
是对响应的一种限定,包含很多属性。常用的属性有:
- Location,实现请求重定向。
- Server,服务器的基本信息。
- Content-Encoding,服务器发送数据时使用的压缩格式。
- Content-Language,发送的数据所用的语言。
- Content-Type,所发送的数据的类型。
- Content-Length,发送数据的大小。
- Set-Cookie,把cookie发送到客户端。
- Last-Modified,指示资源的最后修改日期和时间。
以上是关于Python学习笔记——与爬虫相关的网络知识的主要内容,如果未能解决你的问题,请参考以下文章