Python——网络爬虫,一个简单的通用代码框架
Posted kekefu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python——网络爬虫,一个简单的通用代码框架相关的知识,希望对你有一定的参考价值。
一、代码
"""
通用代码框架:可使网页爬取变得更稳定更有效
下面是一个爬取百度网页的例子,
正常情况下是返回
"""
import requests
def get_html_Text():
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
# 若状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
return r.text
except:
return \'产生异常!\'
if __name__ == \'__main__\':
url = "http://www.baidu.com"
print(get_HTML_Text()
二、结果分析
正常情况:其实去掉三个www中的一个也会正常

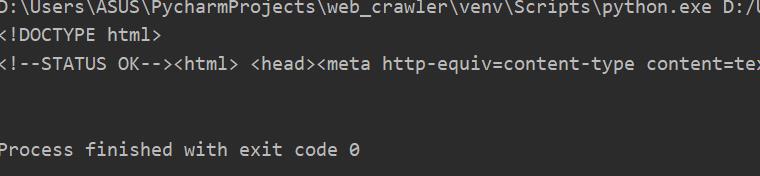
异常情况1:
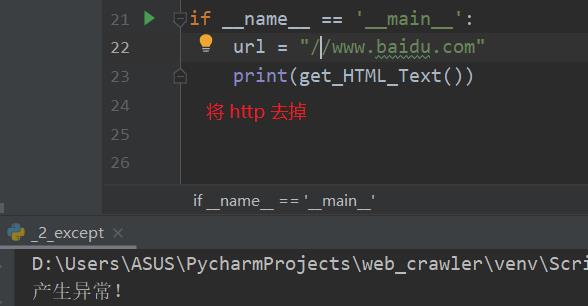
异常情况2:
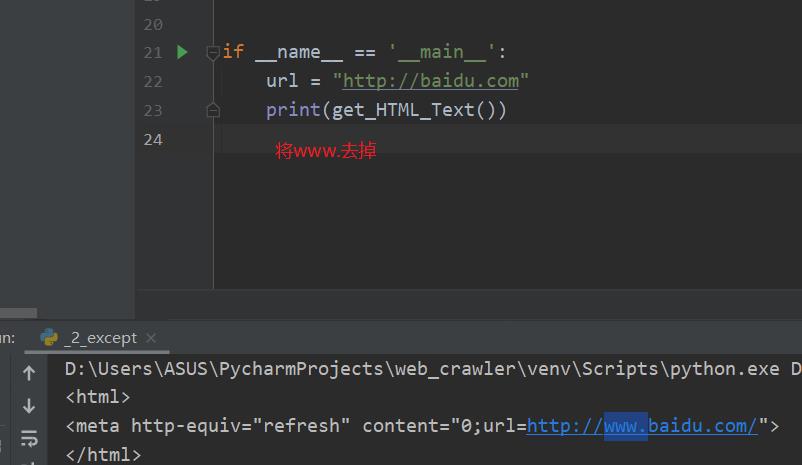
异常情况3:
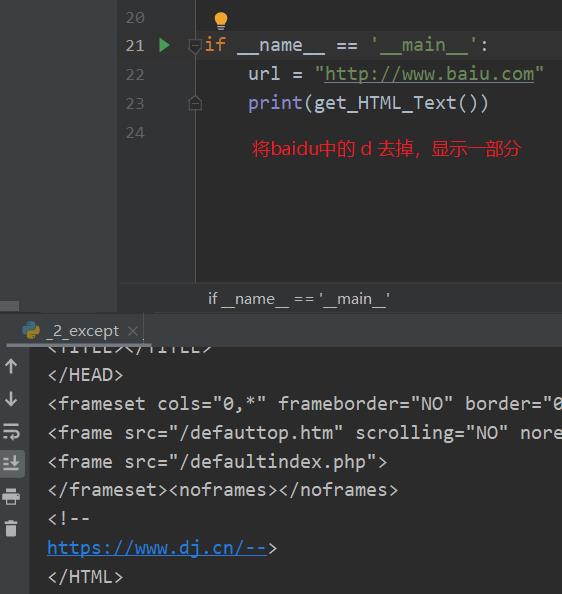
三、总结
异常情况的原因多样,通用代码框架并不能包含全部异常,代码写正确才是王道
以上是关于Python——网络爬虫,一个简单的通用代码框架的主要内容,如果未能解决你的问题,请参考以下文章