新版白话空间统计(41):常用聚类算法分类之划分法与专业聚类算法包Pyclustering
Posted 虾神说D
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新版白话空间统计(41):常用聚类算法分类之划分法与专业聚类算法包Pyclustering相关的知识,希望对你有一定的参考价值。
前文再续,书接上一回。
聚类算法相当的多,但是分类却比较好理解,如下所示。
上图是常见的聚类算法分类,序号的意义是从常用到不常用进行排序,最常见的是基于划分的聚类算法,而最冷僻的是基于混合的聚类算法。(该内容参考中南大学邓敏老师的相关论文和著作)。
如果要把所有算法都秀一遍过去,估计得讲上十几二十章的,所以我这里在每个类别里面,挑选一个或者几个最典型的给大家做个介绍,如果还有想了解更多内容的,请查阅相关资料和论文,如果希望做得更深入的,还需要自己编程来实现一下。

下面言归正传:
排名第一的是基于划分的算法,从名字上来看,就比较好理解了,这种算法对于数据进行的处理,言简意赅的就是:

下面我们通过聚类里面的hello world,来讲讲这种算法:
一般书上要讲聚类,99%都是从k-means开始讲的,其做为当之无愧的聚类hello world,非常容易入门,网上的资料实在太多了,我都不好意思在这个上面浪费时间,所以为了表示系统性和连贯性,这里贴几张图出来表示我讲过:(量子学习法:转发了,就等于学会了)
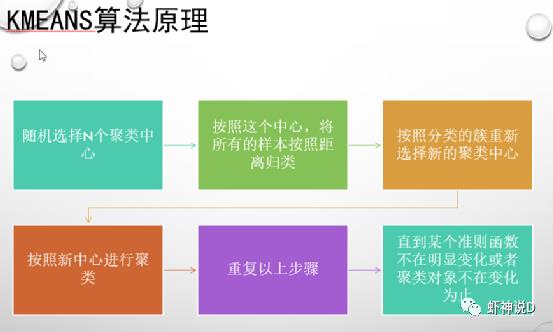
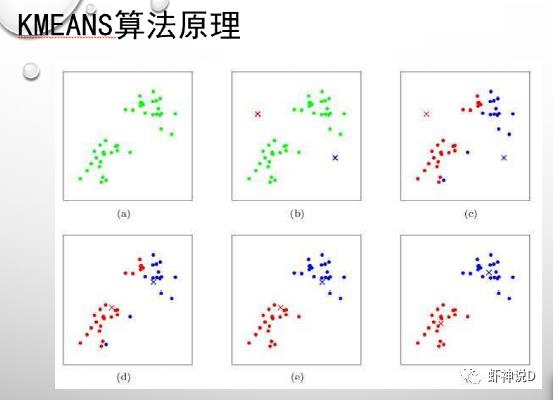
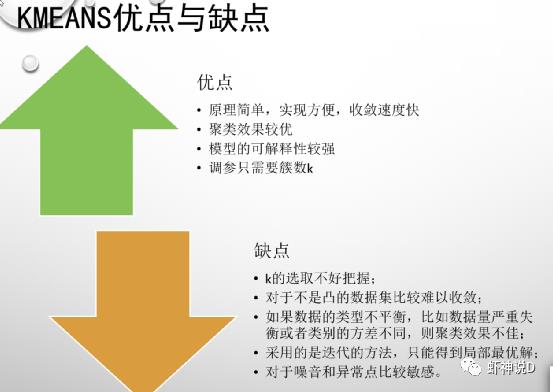
总结一下:
1、要用k-means,首先需要确定你要将这些数据分成几类,这个类的数量就是你未来需要调整的唯一参数,原理见前篇文章中的拓展排队案例:
2、k-means的算法原理,属于划分法,就是不断的把样本划分到相关的类别里面去之后,再去计算合理不合理,是不是有更合理的划法,如果有,就重新划分,一直迭代,所以性能比较惨。
3、原理特简单、方法特容易(实现)、结果特容易解释、用起来特省事(四特XX韵请联系我给广告费)——所以特多人用(我就特别喜欢用来k-means来做示例)。
比如我以前写的一个小案例:
(自从机器学习流行起来之后,写示例容易太多了……sklearn包简直就是神器,就算你完全不懂,也能很轻松的撸出一个分析结果来,不过有志于做深度研究的同学,有可能的话,还是亲手去写一写这个实现过程,以便加深印象,不过鉴于白话空间统计的原则,所以手撸算法原理这种,就不做要求了。)
最后,做为云时代的同学,一定要学会量子学习法:你转发了,就等于你学会了……

下面是每天一个小技巧时间:
其他的基于划分的聚类算法,原理上也都差不多,只是进行一些算法上面的优化,以提高性能和精度,不过sklearn仅集成了k-means算法,如果你需要研究跟多的聚类,可以用比较专业的pyclustering包:
这个包是专用的聚类包,集成了三四十种聚类算法,包括了我们能够听说过的各种常见的聚类算法以及一些与神经网络有关的算法,不过对于虾神来说,这个包最有特色的地方,是提供C++/Python双实现的算法:
为了提升效率,默认使用C++来实现核心算法。
安装的时候,发现你机器上没有C++编译环境的话,转为Python实现。
这样,你如果追求效率,可以使用C++来编译;而如果是追求简单适用,则用Python就行。
下面我分别用几种基于划分的算法,来做个简单演示,看看pyclustering怎么用:
导入包部分,不解释:
首先我们来看看用于测试的聚类数据:
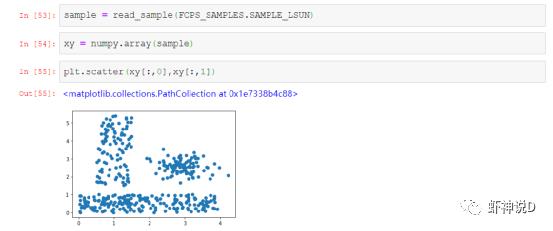
这个大佬比较有意思,所有的示例数据都用的list,而非Python习惯的numpy结构(导致我要切片的时候,还需要手动转成numpy的array结构:

不过鉴于他有两个版本:C++/Python,整成numpy有些麻烦,也就情有可原了……
下面是kmeans算法的启动:这位大佬的算法提供了足够细的算法粒度,比如允许(强制要求)指定kmeans的起算聚类中心点坐标,所以我这里用两种方法来示例,还可以做一个对比测试:
首先第一个,是kmeans默认的随机选择聚类中心点算法:
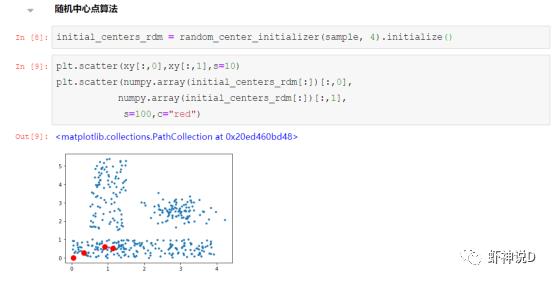
然后是kmeans++算法:
kmeans++算法,这个算法对于kmeans的初始化聚类中心点的位置进行优化选择,可以有效的提升kmeans的执行效率。
算法描述如下:先随机第一个中心点,然后在所有样本中离第一个点最远的地方选第二个点,然后迭代到选出所有初始化中心点。
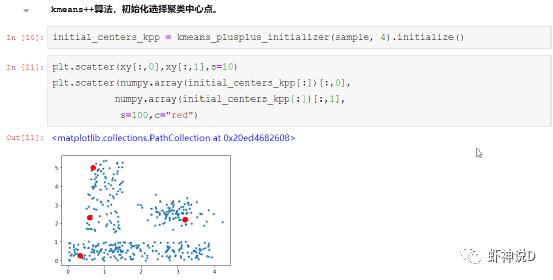
相对于纯粹随机再进入聚类算法迭代,kmeans++算法性能会好很多。但是kmeans因为本身先天劣势,所以在大数据量的情况下,算法的效率堪忧。
下面我们来对比一下:
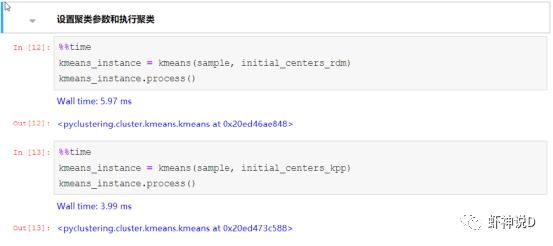
通过对比结果可以看出来,同样的数据,仅仅是选择的起算点位置不同,效率竟然能够提升三分之一以上……
获取一下最终的结果:
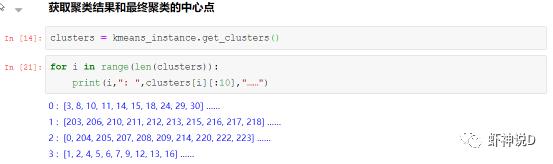
这是最终的聚类结果的中心点:
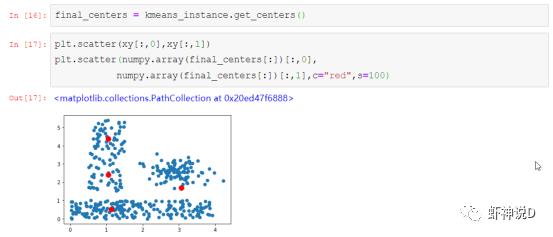
这这个获取方法,就可以看出,作者大佬是一个纯粹的OO码农……所有的代码编写风格都是基于面向对象的方式:

在OO编程风格里面:
首先要实例化对象(new一下),顺便还要在构造函数里面传入各种初始化变量。
然后用实例化的对象调用里面成员函数。
计算完成之后,还要用对象的成员变量来获取计算结果。
……
这一点也不Python……

最后获取计算结果,作者还很贴心的封装了可视化方法:
总体来说, 这个包灰常强大,但是又不是特别复杂,所以大家还有兴趣的话,还可以试试其他的算法。
当然,后面我在演示Demo的时候,会在sklearn和pyclustering中选择一种来进行实现(什么?你问我为什么不自己写代码来实现?)
未完待续,请听下回。
最后,因为我用docx导入生成的文档,所以部分代码图片不清晰,需要代码的同学,可以去虾神代码仓库中获取:
https://gitee.com/godxia/PythonDemo
028聚类演示
以上是关于新版白话空间统计(41):常用聚类算法分类之划分法与专业聚类算法包Pyclustering的主要内容,如果未能解决你的问题,请参考以下文章