荐读!微博大规模分布式 AIOps 系统探索与实践
Posted 日志帮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了荐读!微博大规模分布式 AIOps 系统探索与实践相关的知识,希望对你有一定的参考价值。
【写前面】
关于日志帮
日志管理工具爱好者交流平台,分享日志管理相关知识,普及日志管理理念。发布日志管理领域的技术趋势,评测分享日志管理领域的开源及商业化产品。
作者介绍
彭冬,微博广告基础架构团队负责人。朱伟,微博广告SRE团队技术负责人。刘俊,微博平台部监控技术负责人。王莉,在微博广告团队中致力于用数据分析和机器学习模型优化广告业务策略,洞悉商业价值。陆松林,微博广告数据仓库负责人。车亚强,微博广告大数据开发工程师。
智能运维(AIOps)时代开启,我们开始了解智能运维之余,逐渐发现智能运维也面临着诸多问题。本文我们将带你深入了解智能运维的定义与发展现状、探索智能运维所面临的难题,并针对每一类问题给出经过实践证明的解决方案和思路。
一、AIOps的定义与发展现状
随着业务的发展、服务器规模的扩大,以及云化(公有云和混合云)、虚拟化的逐步落实,运维工作就扩展到了容量管理、弹性(自动化)扩缩容、安全管理,以及(引入各种容器、开源框架带来的复杂度提高而导致的)故障分析和定位等范围。
听上去每一类工作都不简单。不过,好在这些领域都有成熟的解决方案、开源软件和系统,运维工作的重点就是如何应用好这些工具来解决问题。
传统的运维工作经过不断发展(服务器规模的不断扩大),大致经历了人工、工具和自动化、平台化和智能运维(AIOps)几个阶段。这里的AIOps不是指Artificial Intelligence for IT Operations,而是指Algorithmic IT Operations(基于Gartner的定义标准)。
基于算法的IT运维,能利用数据和算法提高运维的自动化程度和效率,比如将其用于告警收敛和合并、Root分析、关联分析、容量评估、自动扩缩容等运维工作中。
在Monitoring(监控)、Service Desk(服务台)、Automation(自动化)之上,利用大数据和机器学习持续优化,用机器智能扩展人类的能力极限,这就是智能运维的实质含义。
智能运维具体的落地方式,各团队也都在摸索中,较早见效的是在异常检测、故障分析和定位(有赖于业务系统标准化的推进)等方面的应用。智能运维平台逻辑架构如图所示:
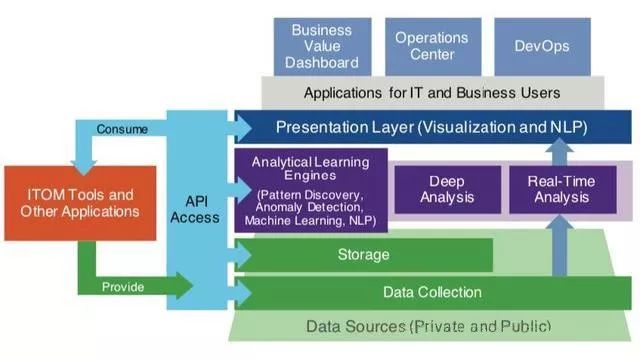
智能运维平台逻辑架构图
智能运维绝不是一个跳跃发展的过程,而是一个长期演进的系统,其根基还是运维自动化、监控、数据收集、分析和处理等具体的工程。人们很容易忽略智能运维在工程上的投入,认为只要有算法就可以了,其实工程能力和算法能力在这里同样重要。
二、几处问题的解决方案与思路
前面我们介绍了智能运维的定义和发展现状,但是智能运维需要解决的问题还有很多:海量数据存储、分析、处理,多维度、多数据源,信息过载,复杂业务模型下的故障定位等,这些难题是否会随着智能运维的深入应用而得到一定程度的解决呢?我们接下来将逐步展开这些问题,并针对每一类问题给出经过实践证明的解决方案和思路,同时说明为什么要这么做,以及在工程和算法上会遇到的问题。
运维人员必须随时掌握服务器的运行状况,除常规的服务器配置、资源占用情况等信息外,业务在运行时会产生大量的日志、异常、告警、状态报告等,我们统称为“事件”。通常每台服务器每个时刻都会产生大量这样的“事件”,在有数万台服务器的场合下,每天产生的“事件”数量是数亿级的,存储量可能是TB级别的。
在过去,我们通常采用的方法是将日志保留在本地,当发现问题时,会登录出问题的服务器查看日志、排查故障,通过sar、dmesg等工具查看历史状态;监控Agent或者脚本也会将部分状态数据汇报到类似于Zabbix这样的监控软件中,集中进行监控和告警。
当服务器规模越来越大时,如何统一、自动化处理这些“事件”的需求就越来越强烈,毕竟登录服务器查看日志这种方式效率很低,而成熟的监控软件(比如Zabbix、Zenoss等)只能收集和处理众多“事件”当中的一部分,当服务器数量多了以后,其扩展能力、二次开发能力也非常有限。在具体实践中,当监控指标超过百万级别时,就很少再使用这种单一的解决方案了,而是组合不同的工具和软件,分类解决问题。
在通用设计方法中,有“大工具、小系统,小工具、大系统”的说法,这也符合UNIX的设计哲学,每个工具只做好一件事,一堆小工具组合起来可以完成很复杂的工作。如果使用的是一些大工具或者系统,表面上看功能很多,但是当你想处理更复杂的业务时,就会发现每一个功能都不够用,而且还很难扩展,它能做多“大”事取决于它的设计,而不是你的能力。
一个由典型的小工具组成的大系统,任何一个部分都可以被取代,你完全可以用自己更熟悉的工具来做,而且对工具或者组件的替换,对整体没有太大影响。
一提到海量数据的存储、分析和处理,大家就会想到各种各样的大数据平台。是的,大数据平台确实是用来处理海量数据的,但反过来不见得成立,对海量数据的分析和处理,并不总是或者只依赖大数据平台。
“分类”这个词听上去朴实无华,然而处理复杂问题最基本的方法就是分类,甚至“分类方法”也是机器学习非常重要的组成部分。“海量数据处理”这是一个宏大的命题,听上去让人一头雾水,但当你对“事件”或者需要处理的问题分类后,每一部分看上去就是一个可以解决的问题了。
我们会在《智能运维》一书中详细介绍如何对海量“事件”进行分类和处理:
实时数据和非实时数据;
格式化数据和非格式化数据;
需要索引的数据和只需要运算的数据;
全量数据和抽样数据;
可视化数据和告警数据。
每一个分类都对应一种或多种数据处理、分析和存储方式。也可以说,当你对数据、需求完成分类后,基本的框架也就定了下来,剩下的工作就是集成这些工具。
下图是一个多维度模型示例:
多维度模型示例
真实世界的情况是(至少按弦理论学家所说的是),除我们可以感知的3个“延展维”外,还有6个“蜷缩维”,它们的尺寸在普朗克长度的数量级,因此我们无法感知到。
当然,运维数据中的“多维度”,还没有复杂到这样难以理解。
在相对复杂的业务场景下,一个“事件”除包含我们常用的“时间”(何时发生)、“地点”(哪个服务器/组件)、“内容”(包括错误码、状态值等)外,还应当包含地区、机房、服务池、业务线、服务、接口等,这就是多维度数据。
很多时候,数据分析人员可能要使用各种维度、组合各种指标来生成报告、Dashboard、告警规则等,所以是否支持多维度的数据存储和查询分析,是衡量一个系统是否具有灵活性的重要指标。
对多维度数据的处理,很多时候是一个协议/模型设计问题,甚至都不会牵扯具体的分析和处理框架。设计良好的协议和存储模型,能够兼顾简洁性和多维度。
不同的设计理念会对应不同的处理模型,没有优劣之分,只有哪个更合适的区别。
多数据源或者说异构数据源已经很普遍了,毕竟在复杂场景下并不总是只产生一种类型的数据,也不是所有数据都要用统一的方式处理和存储。
在具体的实践中,通常会混合使用多种存储介质和计算模型:
监控数据:
时序数据库(RRD、Whisper、TSDB);
告警事件:Redis;
分析报表:mysql;
日志检索:
ElasticSearch、Hadoop/Hive。
这里列出的只是一部分。
如何从异构的多数据源中获取数据,还要考虑当其中某个数据源失效、服务延迟时,能否不影响整个系统的稳定性。这考量的不仅仅是各种数据格式/API的适配能力,而且在多依赖系统中快速失败和SLA也是要涉及的点。
多数据源还有一个关键问题就是如何做到数据和展现分离。如果展现和数据的契合度太高,那么随便一点变更都会导致前端界面展现部分的更改,带来的工作量可能会非常大,很多烂尾的系统都有这个因素存在的可能性。
DDoS(分布式拒绝服务)攻击,指借助于客户/服务器技术,将多台计算机联合起来作为攻击平台,对一个或多个目标发动攻击。
其特点是所有请求都是合法的,但请求量特别大,很快会消耗光计算资源和带宽,下图展示了一个DDos攻击示例:
DDoS攻击示例
当我们的大脑在短时间内接收到大量的信息,达到了无法及时处理的程度时,实际上就处于“拒绝服务”的状态,尤其是当重大故障发生,各种信息、蜂拥而至的警报同时到达时。
典型的信息过载的场景就是“告警”应用,管理员几乎给所有需要的地方都加上了告警,以为这样即可高枕无忧了。然而,接触过告警的人都知道,邮件、短信、手机推送、不同声音和颜色提醒等各种来源的信息可以轻松挤满你的空间,很多人一天要收上万条告警短信,手机都无法正常使用,更别谈关注故障了。
怎样从成千上万条信息中发现有用的,过滤掉重复的、抖动性的信息,或者从中找出问题根源,从来都不是一件容易的事情,所以业界流传着“监控容易做,告警很难报”的说法。
还有一个场景就是监控。当指标较少、只有数十张Dashboard时,尚且可以让服务台24小时关注;但是当指标达到百万、千万,Dashboar达到数万张时(你没看错,是数万张图,得益于Grafana/Graphite的灵活性,Dashboard可以用程序自动产生,无须运维工程师手工配置),就已经无法用人力来解决Dashboard的巡检了。
历史的发展总是螺旋上升的,早期我们监控的指标少,对系统的了解不够全面,于是加大力度提高覆盖度,等实现了全面覆盖,又发现信息太多了,人工无法处理,又要想办法降噪、聚合、抽象,少→多→少这一过程看似简单,其实经过了多次迭代和长时间的演化。
本书中我们还将继续了解这类问题在实践中的解决方法:
数据的聚合;
降低维度:聚类和分类;
标准化和归一化。
有些方法属于工程方法,有些方法属于人工智能或机器学习的范畴。
业务模型(或系统部署结构)复杂带来的最直接影响就是定位故障很困难,发现根源问题成本较高,需要多部门合作,开发、运维人员相互配合分析(现在的大规模系统很难找到一个能掌控全局的人),即使这样有时得出的结论也不见得各方都认可。
在开发层面,应对复杂业务的一般思路是采用SOA、微服务化等;但从运维的角度讲,完成微服务化并没有降低业务的复杂度(当然结构肯定变清晰了)。
在这里,又不得不强调工程能力的重要性。在复杂、异构和各种技术栈混杂的业务系统中,如果想定位故障和发现问题,在各个系统中就必须有一个可追踪、共性的东西。然而,在现实中若想用某个“体系”来一统天下,则基本不可能,因为各种非技术因素可能会让这种努力一直停留在规划阶段,尤其是大公司,部门之间的鸿沟是技术人员无法跨越的。
所以,下面给出的几种简单方法和技术,既能在异构系统中建立某种关联,为智能化提供一定的支持,又不要求开发人员改变技术栈或开发框架:
日志标准化:日志包含所约定的内容、格式,能标识自己的业务线、服务层级等;
全链路追踪:TraceID或者RequestID应该能从发起方透传到后端,标识唯一请求;
SLA规范化:采用统一的SLA约定,比如都用“响应时间”来约定性能指标,用“慢速比”来衡量系统健康度。
当这些工程(自动化、标准化)的水平达到一定高度后,我们才有望向智能化方向发展。
故障定位又称为告警关联(Alarm Correlation)、问题确定(Problem Determination)或根源故障分析(Root Cause Analysis),是指通过分析观测到的征兆(Symptom),找出产生这些征兆的真正原因。
在实践中通常用于故障定位的机器学习算法有关联规则和决策树。
还有很多方法,但笔者也在探索中,所以无法推荐一个“最佳”方法。究竟什么算法更适合,只能取决于实践中的效果了。
需要注意的是,并不是用了人工智能或机器学习,故障定位的效果就一定很好,这取决于很多因素,比如特征工程、算法模型、参数调整、数据清洗等,需要不断地调整和学习。还是这句话:智能化的效果不仅仅取决于算法,工程能力也很重要,而且好的数据胜过好的算法。
以上就是我们对智能运维(AIOps)的一些认识和探索。更多内容,大家可以阅读后续内容增加了解。
回复:ELK ,可获取相关文章;
回复:面试题,可获取多家企业面试题。
日志帮
日志管理工具爱好者交流平台
更多日志分析文章
长按二维码,让你时刻掌握行业动态
↓↓↓ 点击"阅读原文" 【查看往期内容】
以上是关于荐读!微博大规模分布式 AIOps 系统探索与实践的主要内容,如果未能解决你的问题,请参考以下文章