AIOps 在 360 的落地实践
Posted DevOps技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AIOps 在 360 的落地实践相关的知识,希望对你有一定的参考价值。
随着运维工作从规模和复杂度多方面的爆炸式增长,传统的运维手段已经无法满足如今系统运维管理的需求。AI技术日趋成熟,智能运维(AIOps)应运而生,给运维行业带来了很多的变革和机会。如何将大数据和机器学习的方法引入运维的各个领域?如何快速落地AIOps?本文作者在应用实践的基础上,系统的总结了AIOps的落地方案。下来就跟随作者一同探索吧。
9月22日,在北京360公司总部举办了【360互联网技术训练营第18期——AIOps落地实践探索】。本次会议共有四个议题,分别由两位内部讲师及两位外部讲师分享,第一个分享
AIOps在360的落地实践——你也可以快速落地AIOps介绍了360的智能运维大框架和每个组件的替换建议等,旨在希望能让一些还没落地或者正准备落地的小公司也能开展aiops,另一位内部讲师的分享议题是
360基于StackStorm的AI运维平台故障自愈实践,主要是从一些常用的具体场景切入,期间加入预测、异常检测、关联分析等模型,然后针对检测结果做一些判断和自愈。
本次分享的第二个议题是由来自宜信的肖云朋讲师分享的
基于知识图谱构建下一代智能 CMDB,知识图谱也有很多公司研究,在AIOps领域算是算法的补充,因为算法的本质还是通过大数据来分析和生成运维规则,而有些规则,在一些固定的场景,我们完全可以通过人工经验来直接生成,或者通过现有的cmd调用关系直接生成。比如A肯定会导致B发生,那就没必要再用大数据来找A与B的关系。如果把AIOps比成运维大脑的话,知识图谱算是根据你的运维经验,直接告诉大脑的一些固定知识,直接给你3岁智商,不需要你从0开始,什么都得学。一些运维经验直接无法生成规则的,可以交由大数据AI分析,慢慢替你学习找规律。
在360内部,尽管有成熟的cmdb hulk和odin等系统,有每天一线运维的经验积累,但这些都暂时没有通过知识图谱的形式把他生成经验库,这也是360内部接下来需要加强的地方。
本次分享的第三个议题是来自日志易,有着丰富运维经验的杜卫普分享的
基于日志大数据的智能运维与安全实践,作为一个三方Tob公司,如果要接入一家公司的运维数据做智能分析,一般要集成agent,用户考虑到服务端的安全性,会不太配合,所以agent自采集和agent抓包等,都比较难,一般都是从日志入手,所以日志易的切入点还是在大规模的三方日志,从最开始的elk到现在的自研等。然后AI的部分应该是体现在日志的一些关键词nlp分析,和生成的时序异常检测等。
了解了其他公司的一些AIOps切入点,接下来看看360自己的AIOps落地方案,从18年3月左右做智能运维落地和探索,我们也总结出了一套符合当前360现状的落地思路。
整体来说,随着公司的不断发展,不少业务进入了平台期,同时也涌现出了非常多的运维常见问题,例如:资源长期空闲,但没有及时回收;报警越来越多,但充满了误报漏报;报警杂多,但报警项之间没有关联等等,对于运维人员都是极大的挑战和折磨。
为了更好地解放运维,360针对性的选择了三个通用的高频运维场景,然后
借以AI分析在这些场景内做了分析和预测。例如,在资源回收场景,使用了分类和时序预测模型,在报警误报漏报,使用了时序异常检测,用更准的动态阈值来代替一刀切的阈值。在报警关联方面,使用了报警收敛和关联分析、根因分析等模型,给出了topN的可能原因,辅助运维做决策。
接下来简单的串讲一下。我们提到了我们的
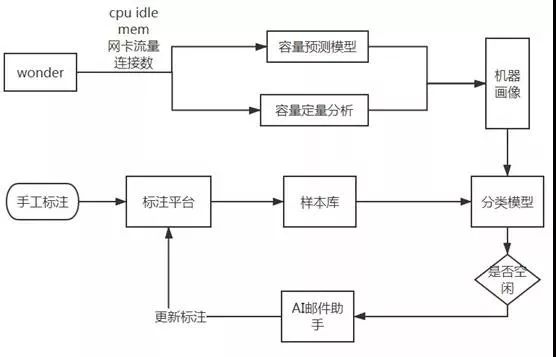
运维大数据 -> AI中心 -> 报警自愈 -> 运维大屏。其实这个思路有一个拟人的对应关系,运维大数据即我们的监控系统类比我们的眼睛,AI中心类比大脑,自愈类比手脚,运维大屏类比脸面。这样才是一个立体的架构。我们得看到问题存在的地方,发现问题,然后去AI分析问题,最后去执行自愈动作,解决问题,整体肯定是串联的。当然背后的工作做的再好,也得有一张好看的脸面,让别人能看到你的美,所以运维大屏作为我们的一个展示,也是非常必要的。接下来我们不看内涵先看脸。
这个图其实算是一个大聚合,这里面展示了有左边栏资源回收的成本数据,右边的效率提升数据,最下面的运维大数据,中间的骨干网络链路数据。其中骨干网的链路数据随着滚动条的拖动,可以实时生成预测数据。最顶端还有实时的push通道,如果有一些大规模报警过来,经过判断和分析后,确定是AI数据了,会实时的在大屏上显示影响范围,当然这一块屏还是数据维度的展示居多,脑洞大开一下,以后是否可以加上交互,比如装上摄像头,谁看大屏了,看了几次,看了多久,都可以统计,然后加上手势,可以切屏,局部放大等,甚至一些更酷炫的交互展示等。总之,展示是一个可玩性非常高的领域,即使我们是搞运维的,也希望大家不要局限思维,敢想敢玩,就能有新花样。
当然这么复杂的展示都是因为公司奇舞团的大力支持,一般情况下,一些开源的3d可视化框架也能做的很不错,例如echarts等,大家可以自行发掘。
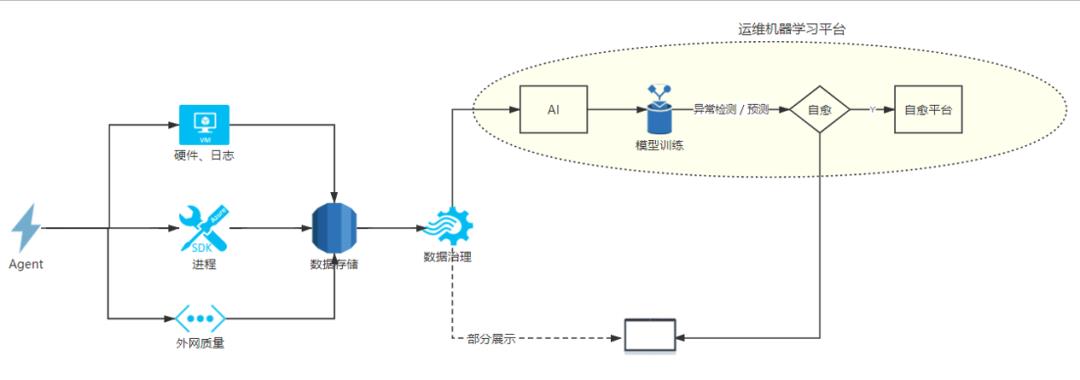
接下来看看可视化背后的体系架构,整体我们的体系就是agent采集,我们这里agent都是自研改造,根据需求可以采集任何我们想要的数据。比如这里的硬件、日志、进程、外网质量等数据,然后按需存到对应的方案中,然后统一集中治理,接着针对固定的时序数据,固定的场景去做AI分析,最后如果该场景需要自愈,可以触发命令系统执行自愈动作,最后聚合部分数据,做一个集中的大屏展示。
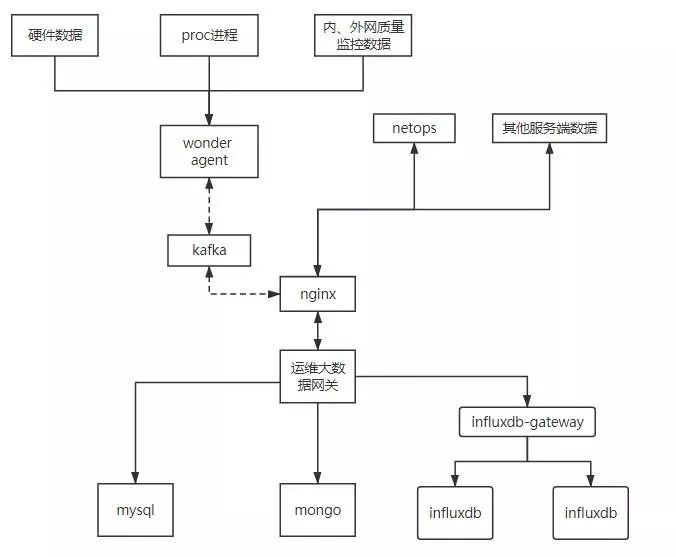
这里我们整体的数据采集有agent自采,和三方数据。例如syslog通过kafka写入es,硬件接口上报,写到mongo,进程采集,接口上报,最后写入到ha的infludb里面。整体我们的资源数是20台8核16G的机器,我们的整体架构比较简单,就是采集,接口上报网关,网关算是一个比较重的组件,里面的数据处理和报警发送等都没单独拆出来,这么做其实是从运维和发布的角度考虑,整体来说还是单体应用和微服务的优劣区别,这里就不展开对比了,感兴趣的可以参考我以前写过的微服务拆分的文章。
我们本身是追求扛得住,易维护,代码复杂度低的原则。不会为了微服务而微服务。比如我们agent和网关的交互,没有使用rpc等,都是用的短链接,因为rpc在连接池维护,和连接状态管理方面有很多的注意的东西,但本质上解决的就是减少带宽传输,减少建连耗时等,但这些在我们的架构中不是很关注。在网关前面挡一层nginx也是为了方便日志分析。这样业务代码里就不需要加载一些框架和太多方便日志处理的代码。整体就是一个无状态的web服务,非常容易扩容和维护。
我们这里由时序预测,时序异常检测,报警关联分析三个模型组成。时序预测用在了资源回收场景,时序异常检测用在了vip外网质量监控场景,关联分析用在了io报警关联等场景。其实当前AI落地aiops,算法本身的准确度是一个方面,同时算法的场景选择也是非常重要的,一个算法落地的好与坏,与场景的选择,数据的工整性有着直接的关系。
这里以时序的异常检测为例子,500个vip,200个cdn ips,10万链路ping, 10万报警阈值。
现在为了检测这10万链路的异常点,我们有两种办法,固定阈值一刀切,固定阈值500ms,这样肯定会有部分的漏报和误报,比如500ms以内的异常波动,这种固定阈值就检测不出来,产生漏报。同时比如,新疆到北京可能链路一直都不好,一直都510ms,但这个属于正常值,所以整条链路都成了误报。
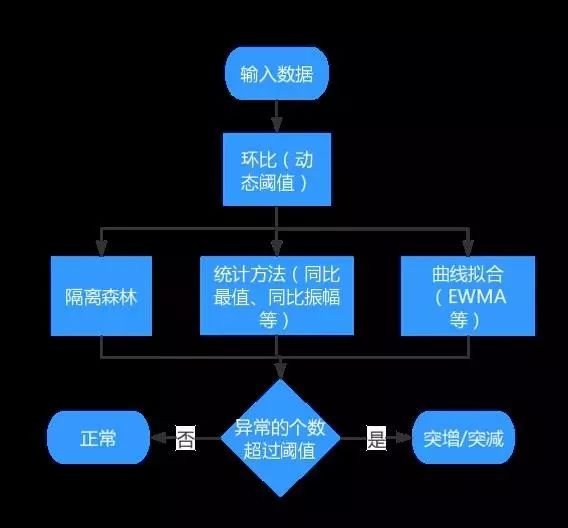
所以我们最好是为10万链路,每个链路生成一个合适的报警阈值,我们不可能人工为10万链路定阈值,所以需要通过异常检测模型,来帮我们检测出每个链路的异常点,相当于每个链路有自己的动态阈值。
10万的链路,我们首先通过聚类分成200左右的类,每一个类一个模型,聚类如果算法不好调优,我们可以通过人工经验,来通过源cdn机房来分类。
我们的异常检测模型,除了孤立森林,和曲线拟合EWMA+3σ等,还有几个统计模型。这样给不同的模型加以权重,最后通过各个模型的投票来决定这个数据点是否异常。因为大部分情况下,孤立森林应该是权重最大,最准的,其他的模型只是为了在孤立森林判断不异常的时候,再去多次确认一下。三个臭皮匠顶一个诸葛亮。
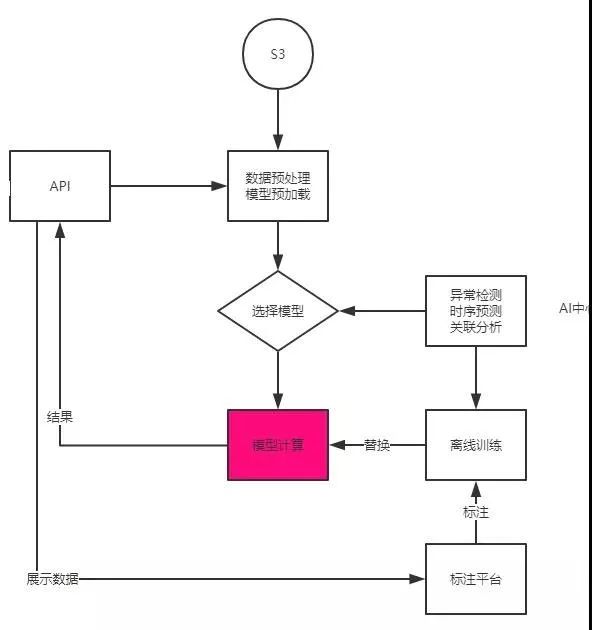
这里整体的流程就是,当一个外网质量数据点过来,AI中心会去redis队列,sub当前该point 2个小时内的同类数据,每分钟10万条数据,每个数据经过7个模型的串联判断,7个模型中的统计模型需要预加载数据,需要实时加载模型,然后模型本身处理数据也需要时间,所以要在一分钟内处理10万条数据,每个数据处理时间1分钟以内必须返回,不然影响报警的实时性。
单机内要缩短每个统计数据的加载时间(10s左右),这个我们通过在报警数据处理层自己做滑动窗口来实现,AI中心只接收数据,不做数据处理。
模型实时加载,本身耗时10s左右,我们通过提前热加载到内存,使用在线非实时模型,AI中心通过后端的离线训练,每个6个小时,替换一次在线模型。前面两步总共节约了20s,然后本身模型处理速度基本上100ms左右没法减少。单机goroutine并发200,至此单机基本上一分钟能处理12000条数据,接着我们扩容AI中心,做成10台高性能模型处理集群。然后将10万的请求打散,每个机器抗1万多的模型处理量。为了控制带宽,我们的请求和AI中心的异常点返回,都是批量执行,所以AI中心我们有一个map-reduce机制。最后将10万数据的异常状态1分钟内分批次返回。
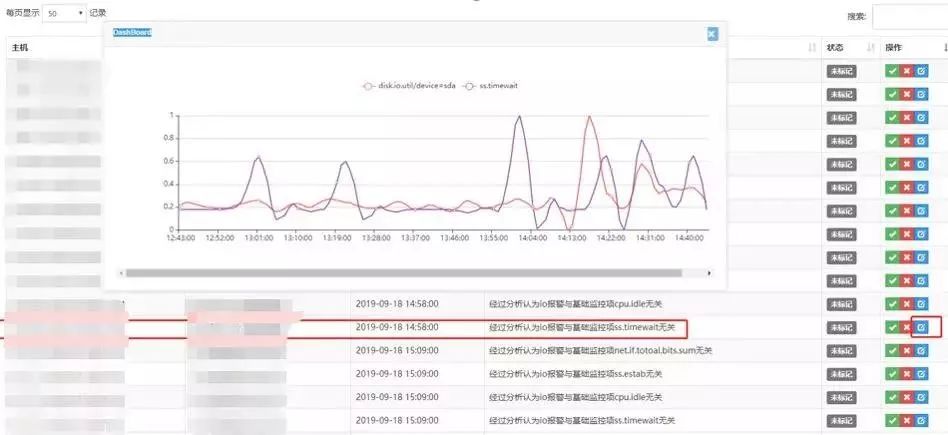
最后我们这些异常检测的数据,还会通过标注平台来人工标注,来反馈到我们的算法模型,算是人工校准一下模型。
时序模型预测用在资源回收的场景中,流程图如下,核心的地方在于分类的标注打标签和预测模型的准确度下。具体这里就不展开了。
关联分析这个模型,用在了io报警的关联分析上,我们通过关联分析模型来先判断多个时序数据之间是否有关联,然后通过异常检测发现的异常点先后顺序,来简单判断是否有前后根因。这里也不展开了。
我们知道数据通过模型最后出来结果,但是这个结果需要不断反馈准确度,才能不断的进化,这里的标注平台就是起的这个作用。我们针对三个模型的相对于的场景,左边栏会显示模型输出的数据,比如异常模型输出的异常点,右边输出该指标的当前值,运维或者业务等模型使用者,可以选择Y或者N,然后反馈会反推给模型数据库,根据这些反馈,离线模型再不断地更新和训练。
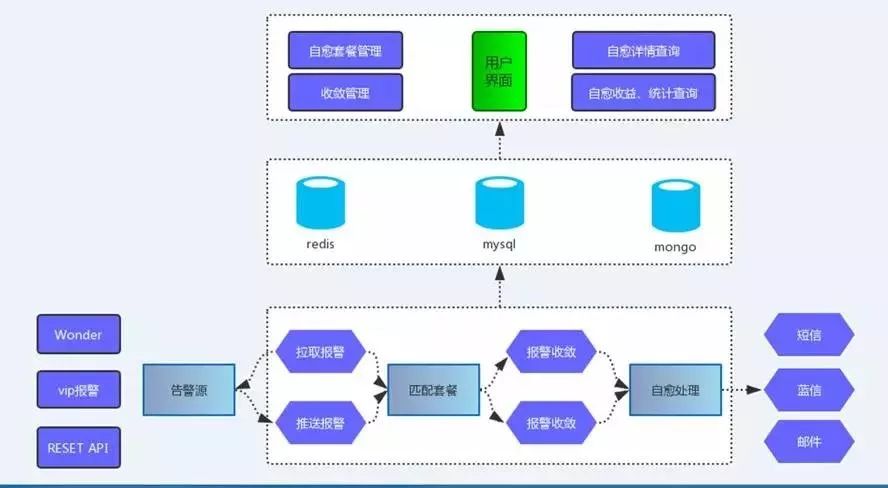
当前我们的自愈更多的是基于一些高频场景,例如机器down机,故障报修,进程重启。底层当前是基于stackstorm改造的,将日常的自愈场景抽象出来各种action原子操作,最后通过这些action原子操作组成workflow工作流,这样以后如果接入新的场景,业务就可以在界面上选择通用action,自行编排,最后组成适合自己的工作流。当然stackstorm本身也有一些弊端,比如框架比较重,依赖yaml等文本,接入成本相对较高,这些都可以在以后的使用过程中不断替换和优化。
以上的运维大数据 -> AI中心 -> 标注平台 -> 报警自愈 -> 运维大屏就是我们当前内部的一个整体AIOps框架,当然在对内打磨的同时,我们也希望能将每个组件通用化,与公司解耦合,以后是否可以Tob帮助更多的团队落地aiops。如果大家有任何AIOps落地心得也欢迎后台留言讨论。
- END -
年轻时偷的懒,迟早是要还的。点亮
以上是关于AIOps 在 360 的落地实践的主要内容,如果未能解决你的问题,请参考以下文章