异常事件分诊在维护云服务的服务水平中至关重要,错误的分诊能增加10倍的诊断异常时间。由于现在的数据中心的应用和依赖复杂度都非常高,正确的分诊异常事件是一个很大的挑战,本推文将介绍微软在智能运维领域的前沿工作Scout,Scout利用机器学习,将有监督模型和无监督模型结合起来,解决了异常事件的分诊问题。该工作是由微软与哈佛大学,宾夕法尼亚大学和普林斯顿大学共同完成,文章《Scouts: Improving the Diagnosis Process Through Domain-customized Incident Routing》于2020年发表在计算机网络领域顶级会议SIGCOMM。目前Scout作为一个异常事件分诊的提示器已经部署到了生产环境。
介绍
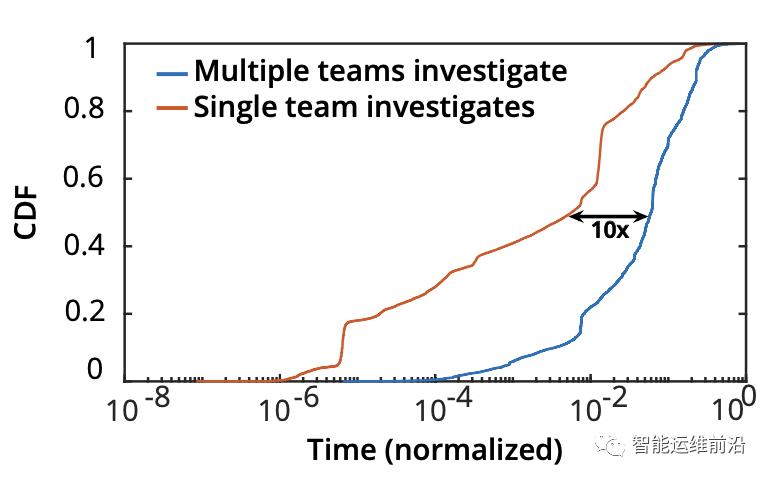
对于云服务提供商而言,异常事件分诊是一件非常复杂以至于很难自动的将异常事件直接分配给某个团队的工程师去做,这也是维护可用性和服务水平的关键瓶颈。错误的事件分诊,可能会让诊断根因的时间增加10倍,研究人员通过对以往数据的分析,发现了一个有趣的事实,就是多个团队一起来解决问题反而比单个团队更慢,如图1所示,横坐标是标准化过后的时间,纵坐标是累积分布概率(Cumulative Probability Distribution, CDF),可以看到,单个团队全程比多个团队快,甚至快很多。以0.01个标准化后的时间来看,单个团队在这个时间内,可以解决近60%的任务,而多个团队在相同时间内仅能解决20%。
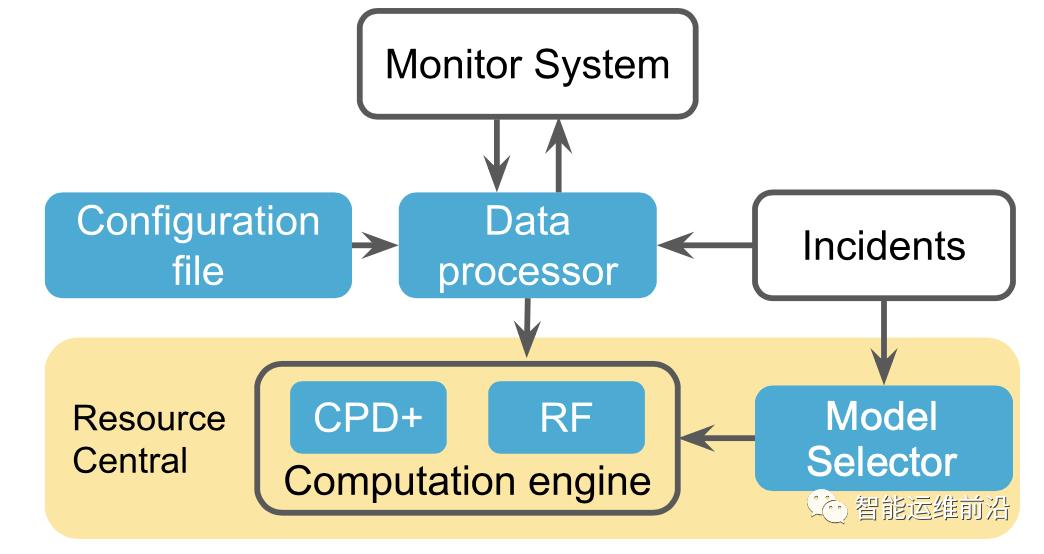
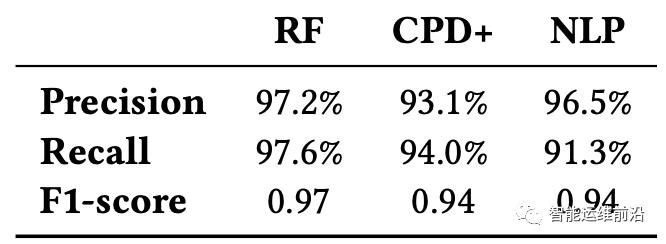
前面提到过,出现频率非常低的事件,很难获得足量的与之对应的训练数据来训练,但一般来说,有监督模型比无监督模型分类效果更好,因此,研究人员决定对频繁发生的异常事件,使用有监督模型,罕见的事件,使用无监督模型。有监督模型,Scout选择的是随机森林作为有监督模型,CPD(Modified Change Point Detection)的改进版作为无监督模型。