微软推荐的经典案例:Batch scoring of Spark models
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微软推荐的经典案例:Batch scoring of Spark models相关的知识,希望对你有一定的参考价值。
参考技术A 微软的Azure的逆袭让微软的市值在2018年的第四季度取代Apple 重新成为了全球老大!王者归来!Satya用cloud first赢回了华尔街的芳心,继任CEO至今,微软股票翻了四倍!当然也是Azure将Satya推上了神坛!Azure的推荐案例里,Azure Databricks无处不在。【请不要问我Databricks是什么!】今夜,分享一个AI架构: Batch scoring of Spark models on Azure Databricks
这种场景很普遍。重资产的工业企业需要减少生产成本和提升运转时间,那么就需要减少非预期的机械事故。那么,可以通过从机器收集到的IoT数据,来创建一个机器学习模型预测机械维护。这样在事故发生之前,可以做维护和修理,让设备可以更长时间的运转【赚钱】!整个流程都在用Databricks/Spark!
- 数据采集:Ingest the data from the external data store onto an Azure Databricks data store.
- 建模:Train a machine learning model by transforming the data into a training data set, then building a Spark MLlib model. MLlib consists of most common machine learning algorithms and utilities optimized to take advantage of Spark data scalability capabilities.
- 预测:Apply the trained model to predict (classify) component failures by transforming the data into a scoring data set. Score the data with the Spark MLLib model.
- 存结果:Store results on the Databricks data store for post-processing consumption.
Github里面有jupyter/iPython notebooks,直接点开,改改就能跑了! 【这位作者是多么喜欢砖厂的红砖啊!满屏幕的砖啊,向经典的坦克大战致敬!】
机器学习案例丨基于广泛和深入的推荐 - 餐厅评级预测
点击上方蓝字
关注我们
(本文阅读时间:18分钟)
Microsoft Azure Machine Learning Studio 是微软强大的机器学习平台,在设计器中,微软内置了15个场景案例,但网上似乎没有对这15个案例深度刨析的分析资料,所以我就计划写一个系列来完成。
既然是深度刨析,就不再是简单的介绍操作,而是深入每一个细节,宁愿过度详细扩展,也不简单扫过。
这次我们刨析的案例是:基于广泛和深入的推荐 - 餐厅评级预测。
微软MVP实验室研究员


王豫翔,Leo
微软圈内人称王公子。微软10年+MVP,大龄程序员。目前核心工作是使用微软AI技术设计可以落地的解决方案,也就是写PPT。虽然热爱代码,但只有午夜时分才是自由敲代码的时间。喜欢微软技术,不喜欢无脑照抄。

预备知识

▍Wide & Deep 模型
2016年,Google 提出了一种兼具模型记忆性和模型泛化性的神经网络——wide & deep for recommender systems。这篇文章是推荐系统中的经典,被应用于 Google Play 中的应用推荐。文章的主要贡献就是提出了兼顾模型记忆性和泛化性的通用模型结构。
记忆性简单的说就是根据用户之前的行为,推荐类似的信息。这种模式计算简单,统计频率的计算量相对较小,但是缺陷也很明显,就是用户的信息茧房越来越封闭,除非用户主动的了解了新类型的信息,否则不太会推荐给用户新类型资讯。
泛化性是指延申用户的行为,推荐其兴趣点有关的信息。但显然这种模式虽然好,但计算肯定复杂了。
Google 将这两个模型结合起来,得到了 wide&deep 模型,其中 wide 部分就是简单的线性模型,deep 部分就是深度学习模型,它同时具有“记忆能力”和“泛化能力”。
▍数据集
该数据集是 Restaurant & consumer data Data Set 的部分。
原生数据:
http://archive.ics.uci.edu/ml/datasets/Restaurant+%26+consumer+data
原始数据分三类共9份文件:
| 分类 | 文件 |
| Restaurants | chefmozaccepts.csv |
| chefmozcuisine.csv | |
| chefmozhours4.csv | |
| chefmozparking.csv | |
| geoplaces2.csv | |
| Consumers | usercuisine.csv |
| userpayment.csv | |
| userprofile.csv | |
| User-Item-Rating | rating_final.csv |
经过对比和分析后,本次案例用了以下三个文件
rating_final.csv | 采纳 | ||
列名 | 含义 | 值描述 | |
userID | |||
placeID | |||
rating | 总体评价 | 0,1,2 | |
food_rating | 食物评价 | 0,1,2 | 否 |
service_rating | 服务评价 | 0,1,2 | 否 |
userprofile.csv | |||
userID | |||
Latitude | 经度 | ||
longitude | 维度 | ||
Smoker | 吸烟 | ||
drink_leve | 饮酒 | 酗酒, 社交饮酒者, 休闲饮酒者 | |
dress_preference | 着装偏好 | 非正式,正式,没有偏好, 优雅 | |
ambience | 氛围 | 家庭,朋友, 孤独 | |
transport | 交通 | 步行, 公共, 车主 | |
marital status | 婚姻状态 | 单身, 已婚, 丧偶 | |
hijos | 子女 | 独立, 孩子, 依赖 | |
birth_year | |||
interest | 兴趣 | 多样性,技术,无,复古,环保 | |
personality | 性格 | 节俭保护者, 猎人炫耀, 勤奋工作者, 墨守成规者 | |
religion | 宗教 | 天主教, 基督教, 摩门教, 犹太人 | |
activity | 学生, 专业, 失业, 工人阶级 | ||
color | 黑色, 红色, 蓝色, 绿色, 紫色, 橙色, 黄色, 白色 | ||
weight | 体重 | ||
budget | 预算 | 中,低,高 | |
height | 身高 | ||
geoplaces2.csv | |||
placeID | |||
latitude | |||
longitude | |||
the_geom_meter | 地理空间 | ||
name | 名字 | ||
address | 地址 | ||
city | 城市 | ||
state | 州 | ||
country | 国家 | ||
zip | 邮编 | ||
Alcohol | 含酒精饮料 | 不含酒精,葡萄酒,啤酒,酒吧 | |
smoking_area | 吸烟区 | 无,仅吧台,允许,部分,不允许 | |
dress_code | 着装要求 | 非正式,休闲, 正式 | |
Accessibility | |||
price | 价格 | 中,低, 高 | |
url | 网址 | ||
Rambience | 氛围 | ||
franchise | 特许经营权 | 是,否 | |
area | 区域 | 开放, 关闭 | |
other_services | 其他服务 | 无,互联网,品种 | |
▍Vowpal Wabbit 数据格式
Vowpal Wabbit,简称 VW,是一个功能强大的开源,在线(online)和外存学习(out-of-core machine learning)系统,由微软研究院的John Langford及其同事创建。Azure ML 通过 Train VW 和 Score VW 模块对 VW 提供本机支持。可以使用它来训练大于 10 GB 的数据集,这通常是 Azure ML 中学习算法允许的上限。它支持许多学习算法,包括 OLS 回归(OLS regression),矩阵分解(matrix factorization),单层神经网络(single layer neural network),隐狄利克雷分配模型(Latent Dirichlet Allocation),上下文赌博机(Contextual Bandits)等。
VW 的输入数据每行表示一个样本,每个样本的格式必须如下
label | feature1:value1 feature2:value2 ...
简单的说,每一条样本的第一个是标签(Label),后面是特征(Feature)。也就是每一条样本都是有标签样本(labeled)。
▍Parquet 列式存储格式
Parquet 是 Hadoop 生态圈中主流的列式存储格式,最早是由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 孵化器里毕业成为 Apache 顶级项目。
有这样一句话流传:如果说 HDFS 是大数据时代文件系统的事实标准,Parquet 就是大数据时代存储格式的事实标准。Parquet 列式存储格式的压缩比很高,所以 IO 操作更小。
Parquet 是与语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与 Parquet 适配的查询引擎包括 Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL 等,计算框架包括 MapReduce, Spark, Cascading, Crunch, Scalding, Kite 等,数据模型包括 Avro, Thrift, Protocol Buffer, POJOs 等。所以 Parquet 就是一个数据存储,提供引擎快速查询数据的格式。
▍优化器
优化的目标是希望找到一组模型参数,使模型在所有训练数据上的平均损失最小。
优化器 | 能力 | 优点 |
SGD | 用单个训练样本的损失来近似平均损失,即每次随机采样一个样本来估计当前梯度,对模型参数进行一次更新 | 训练速度快,内存开销小 |
AdaGrad(Adaptive Gradient Algorithm) | 自适应地确定参数的学习速度,对更新频率低的参数做较大的更新,对更新频率高的参数做较小的更新 | 减少学习率的手动调整,更适用于稀疏数据,提高 SGD 的鲁棒性 |
AdaDelta | 针对 AdaGrad 改进,采用指数衰减平均的计算方法,用过去梯度平方的衰减平均值代替他们的求和 | 不需要提取设定学习速率,使用指数衰减平均计算,防止学习速率衰减过快 |
RMSProp | 是 Geoff Hinton 提出的一种自适应学习率方法。结合了 Momentum 的惯性原则,加上 AdaGrad 对错误方向的阻力 | 解决 AdaGrad 学习率急剧下降 |
Adam | 结合 Momentum 和 AdaGrad 的优点,还包含了偏置修正 | 为不同参数产生自适应的学习速率 |
FTRL(Follow the Regularized Leader) | 能学习出有效的且稀疏的模型 | FTRL 算法融合了 RDA 算法能产生稀疏模型的特性和 SGD 算法能产生更有效模型的特性。它在处理诸如 LR 之类的带非光滑正则化项(例如1范数,做模型复杂度控制和稀疏化)的凸优化问题上性能非常出色,国内各大互联网公司都已将该算法应用到实际产品中 |
▍激活函数(Activation Function)
在神经网络中,输入经过权值加权计算并求和之后,需要经过一个函数的作用,这个函数就是激活函数。如果在神经网络中不引入激活函数,那么在该网络中,每一层的输出都是上一层输入的线性函数,无论最终的神经网络有多少层,输出都是输入的线性组合。也就是说如果没有激活函数,那么再多层的神经网络也只能处理线性可分问题。
激活函数 | 说明 | 类型 |
ReLU(Rectified linear unit,修正线性单元) | 深度学习目前最常用的激活函数,减轻了神经网络的梯度消失问题。ReLU 函数有很多变体,如 LeakyReLU,pReLU 等。使用梯度下降(GD)法时,收敛速度更快 。只需要一个门限值,即可以得到激活值,计算速度更快。但如果输入值为负的时候,输出始终为0,也就是神经元不学习了,这种现象叫做“Dead Neuron”。 | 非饱和 |
Leaky Relu | 针对 Relu 函数中存在的 Dead Relu Problem,Leaky Relu 函数在输入为负值时,给予输入值一个很小的斜率,在解决了负输入情况下的0梯度问题的基础上,也很好的缓解了 Dead Relu 问题。但实测不稳定,所以现在用的也不多。 | 非饱和 |
sigmoid | sigmoid 将一个实值输入压缩至[0,1]的范围,也可用于二分类的输出层。以前很常用,现在用的少了。它在⼤部分时候被更简单、更容易训练的 ReLU 所取代。 | 饱和 |
tanh (Hyperbolic tangent function,双曲正切函数) | 将 一个实值输入压缩至 [-1, 1]的范围,这类函数具有平滑和渐近性,并保持单调性。 | 饱和 |
▍偏差和方差
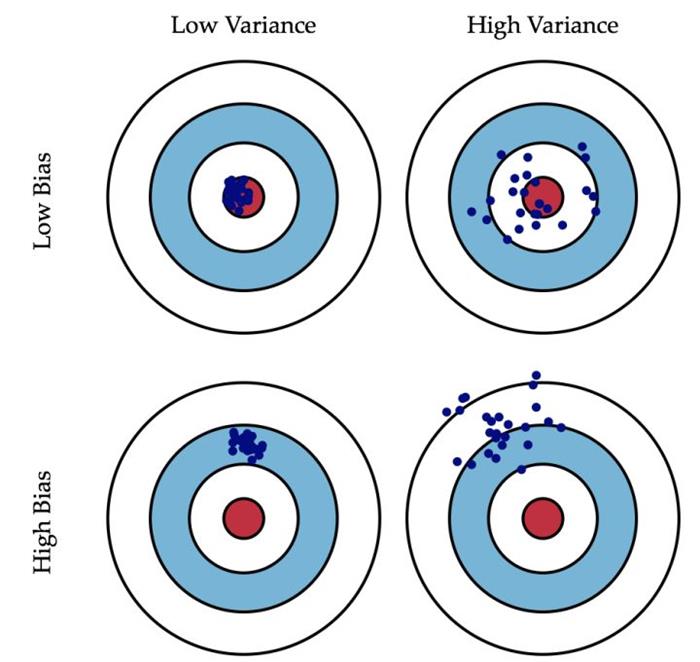
偏差:描述的是预测值的期望与真实值之间的差距。偏差越大,越偏离真实数据。
方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散。
下面这张图非常生动的描述了偏差和方差的含义:
深入分析

这套案例一共九个工作节点,但其中有两组六个节点是一样的。这个案例中不需要我们进行编码,但提供了我们关于非常经典的广告推荐训练的最佳实践,值得我们认真了解。我们逐个分析每一个节点中值得关注的细节和核心信息。
▍数据源输入节点
这一组节点有三个,分别是:Restaurant Ratings、Restaurant Customer Data、Restaurant Feature Data。这些节点的数据可以在节点属性中看到有两个核心信息。
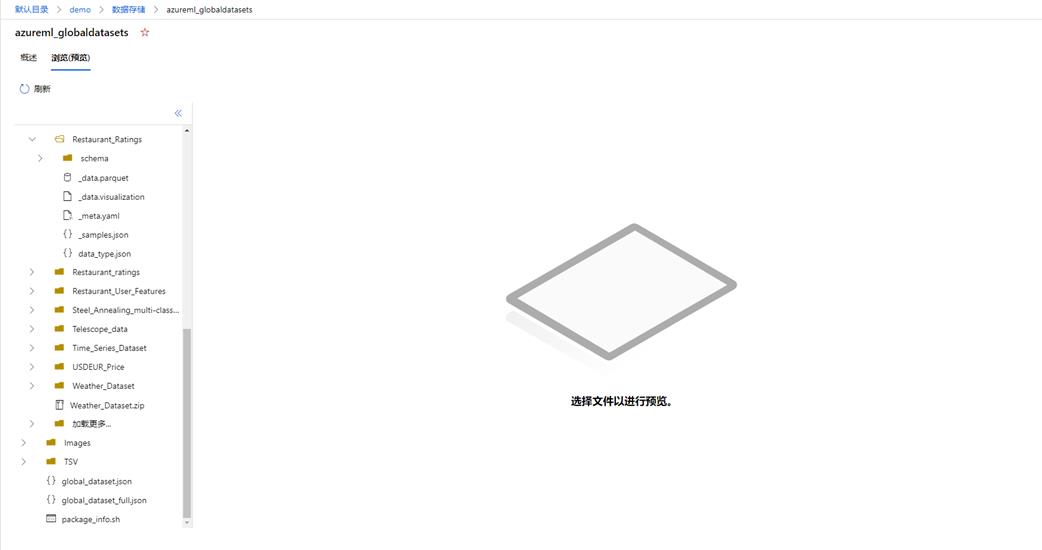
Datastore name:azureml_globaldatasets 是一个链接,点击可以跳转到数据存储的位置;
Relative path:描述在 Datastore 中当前文件的位置。
点击 azureml_globaldatasets 将跳转到 Datastore 浏览器,您可以在这个浏览器下观察到您存储的数据。大致的界面如下
以下表格可以帮助您快速对这三个节点数据有全局的了解。
节点 | 含义 | 相对路径 | 对应RCD数据 |
Restaurant Ratings | 餐厅评级 | Restaurant_Ratings | rating_final.csv |
Restaurant Customer Data | 就餐的客户特征 | Restaurant_User_Features | userprofile.csv |
Restaurant Feature Data | 餐厅特征 | Restaurant_Item_Features | geoplaces2.csv |
▍Split Data 节点
这个节点比较简单,按行将 Restaurant Ratings 数据集分为50%和50%,目的是将数据集分成两个不同的集。拆分的方式有三种:
拆分行:就是简单的讲输入的数据集拆分为两个部分。默认是对半拆分,并且是随机选定内容。
正则表达式拆分:如果我们需要把数据集按某些特征,分为符合和不符合,就可以用这个选项进行拆分。
相对表达式拆分:如果我们希望对数据集按某些范围进行拆分,比如日期范围,数据范围,就可以用这个选项。
当前案例采用了对半随机拆分行。
▍Select Columns in Dataset 节点
这个组件节点有两个,分别是 Restaurant Customer Data 和 Restaurant Feature Data 做数据处理。
Select Columns in Dataset 节点的目的是得到一个输入数据集的子集,过滤一些原始数据集的干扰列。
数据集 | 原始集合 | 子集 |
Restaurant Customer Data | userID、latitude、longitude、smoker、drink_level、dress_preference、ambience、transport、marital_status、hijos、birth_year、interest、personality、religion、activity、color、weight、budget、height | userID、latitude、longitude、interest、personality |
Restaurant Feature Data | placeID、latitude、longitude、the_geom_meter、name、address、city、state、country、zip、alcohol、smoking_area、dress_code、accessibility、price、url、Rambience、franchise、area、other_services | placeID、latitude、longitude、price |
明显可以看出 Select Columns in Dataset 节点将设计者认为不必要的特征都排除了。
▍Train Wide and Deep Recommender 节点
这个节点是本次案例的核心。Wide & Deep 推荐器需要接受三个输入:训练集、用户特征集、评价目标特征集。特别要注意,Wide & Deep 对训练集的格式是有约定的:
训练集:是一个用户-目标-评分的标准结构,也就是说,这个集合只能有三个列,并且依次是:用户标识、目标标识、对目标的评级。
用户特征集合:必须包含用户的标识符,并使用训练集第一列中提供的相同标识符。其余列可以包含任意数量的用于描述用户的特征。
目标特征数据集:必须在其第一列中包含目标标识符,并使用训练集第二列中提供的相同标识符。其余列可以包含任意数量的项目的描述性特征。
对应上面的概念,下表可以全面的了解 Wide & Deep 的输入:
输入参数 | 对应数据集 | 关键特征 |
Training_dataset_of_user_item_rating_triples | Restaurant Ratings | userID placeID rating |
User_features | Restaurant Customer Data | userID |
Item_features | Restaurant Feature Data | placeID |
配置这个组件我们需要关注的参数有:
时期(Epochs):算法应处理整个训练数据的次数。这个数字越高,训练就越充分;但是,训练会花费更多的时间,并可能导致过度拟合。
批处理大小(Batch size):训练步骤中使用的训练示例数。此超参数会影响训练速度。批处理越大,时间成本时期越短,但可能会增加收敛时间。如果批太大,不适合 GPU/CPU,可能会引发内存错误。
Wide 部分优化器(Wide part optimizer):选择一个优化器,对模型的 wide 部分应用梯度,可以从 AdaGrad 优化器开始多次测试。
Wide 优化器学习速率(Wide optimizer learning rate):输入 0.0 和 2.0 之间的数字,该数字定义 wide 部分优化器的学习速率。此超参数确定每个训练步骤的步骤大小,同时不断接近损失函数的最小值。学习速过高可能导致学习跳升超过最小值,而学习率过小可能会导致收敛问题。
交叉特征维度(Crossed feature dimension):通过输入所需的用户 ID 和项目 ID 特征来键入此维度。默认情况下,Wide & Deep 推荐器会针对用户 ID 和项目 ID 特征执行跨产品转换。将根据此数字对交叉结果进行哈希处理,以确保维持该维度。
Deep 部分优化器(Deep part optimizer):选择一个优化器,对模型的 deep 部分应用梯度。
Deep 优化器学习速率(Deep optimizer learning rate):输入介于 0.0 和 2.0 之间的数字,该数字定义 deep 部分优化器的学习速率。
用户嵌套维度(User embedding dimension):键入整数以指定用户 ID 嵌套的维度。Wide & Deep 推荐器会为 Wide 部分和 Deep 部分创建共享的用户 ID 嵌套和项目 ID 嵌套。
嵌套维度(Item embedding dimension):键入整数以指定项目 ID 嵌套的维度。
分类特征嵌套维度(Categorical features embedding dimension):输入整数以指定分类特征嵌套的维度。在 Wide & Deep 推荐器的 deep 组件中,会针对每个分类特征习得一个嵌套矢量。这些嵌套矢量具有相同的维度。
隐藏单位(Hidden units):键入 deep 组件的隐藏节点数。每个层中的节点数用逗号分隔。例如,可以通过类型“1000,500,100”指定 deep 组件有三个层,第一层到最后一层分别有1000个节点、500个节点和100个节点。
激活函数(Activation function):选择一个应用于每个层的激活函数,基本上就选 ReLU 就对了。
丢弃(Dropout):输入 0.0 和 1.0 之间的数字,以确定训练期间每个层中丢弃输出的概率。丢弃是一种可以防止神经网络过度拟合的正则化方法。关于此值的一个常见决策是从 0.5 开始,对于许多网络和任务而言,这一值似乎都接近最优值。
批标准化(Batch Normalization):选择此选项可在 deep 组件中的每个隐藏层之后使用批标准化。批标准化是应对网络训练中内部协变量偏移问题的一种技术。一般来说,它可以帮助提高网络的速度、性能和稳定性。
▍Score Wide and Deep Recommender 节点
Wide and Deep 推荐器评分有两种选择
对用户给出评级的预测:对输入的用户的特征,寻找和他相近用户对目标的评价。
给用户推荐:提供用户和项目列表作为输入。在此数据中,该模型利用其关于现有项目和用户的知识来生成可能对每个用户都具有吸引力的项目列表。可以自定义返回的建议数,并为生成建议所需的先前建议数设置阈值。
▍Evaluate Recommender 节点
我们会得到几个回归问题常用的评估指标:
MAE(Mean Absolute Error,平均绝对误差),这个指标通常用来反映预测值误差的实际情况(风险度)。
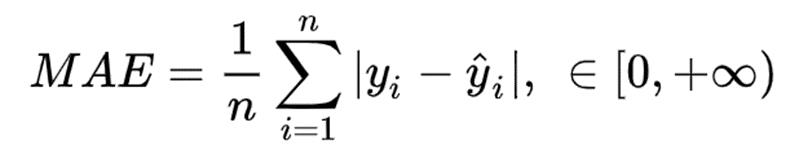
通常用于在连续变量数据上测量性能。它对异常值不是很敏感,因为它不会惩罚错误。
RMSE(Root Mean Square Error,均方根误差) 是回归模型的典型指标,常用于衡量模型预测结果的标准。
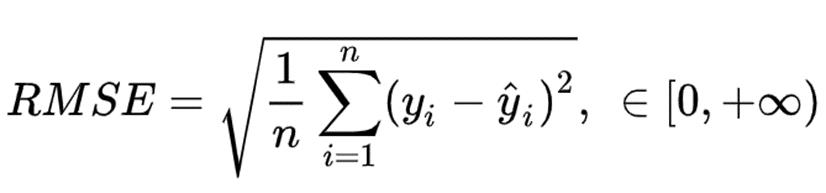
在 RMSE 中,误差在平均之前先平方,这意味着 RMSE 为更大的错误分配更高的权重。这表明当存在大错误并且它们会极大地影响模型的性能时,RMSE 更有用。RMSE 比 MSE 更广泛用于评估回归模型于其他随机模型的性能,因为它的因变量(Y轴)具有相同的单位。
R2 判别系数。对于回归类算法而言,只探索数据预测是否准确是不足够的。除了数据本身的数值大小之外,我们还希望我们的模型能够捕捉到数据的“规律”,比如数据的分布规律,单调性等等,而是否捕获了这些信息并无法使用 MSE 来衡量。R2 测量了回归直线对预测数据拟合的程度。
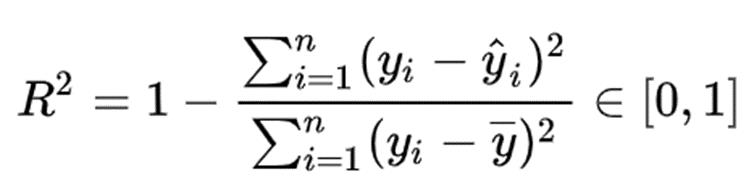
分子是真实值和预测值之差的差值,也就是我们的模型没有捕获到的信息总量,分母是真实标签所带的信息量,所以两者都衡量 1 - 我们的模型没有捕获到的信息量占真实标签中所带的信息量的比例,所以,两者都是越接近1越好。
如果结果是0,说明模型拟合效果很差;
如果结果是1,说明模型无错误。
Explained Variance(可解释变异)用方差来量化变异,故又称为可解释方差(explained variance)。
结束语

到这里,Wide & Deep based Recommendation - Restaurant Rating Prediction 案例的分析我们完成了,在这个过程中,我们详细的了解到各个节点的核心信息和相关的概念。从数据源、数据处理到模型质量报告,也同时接触到了大量的机器学习概念,本篇非常值得推荐作为 Microsoft Azure Machine Learning Studio 和机器学习的入门和深入读物。
在这之后,我将继续编写其他 Microsoft Azure Machine Learning Studio 案例。每一篇案例都可以独立阅读,因此有些概念会重复出现在每一篇中。
微软最有价值专家(MVP)

微软最有价值专家是微软公司授予第三方技术专业人士的一个全球奖项。29年来,世界各地的技术社区领导者,因其在线上和线下的技术社区中分享专业知识和经验而获得此奖项。
MVP是经过严格挑选的专家团队,他们代表着技术最精湛且最具智慧的人,是对社区投入极大的热情并乐于助人的专家。MVP致力于通过演讲、论坛问答、创建网站、撰写博客、分享视频、开源项目、组织会议等方式来帮助他人,并最大程度地帮助微软技术社区用户使用 Microsoft 技术。
更多详情请登录官方网站:
https://mvp.microsoft.com/zh-cn

了解如何使用 Azure 机器学习训练和部署模型以及管理 ML 生命周期 (MLOps)。教程、代码示例、API 参考和其他资源。


点击「阅读原文」获取相关文档~
以上是关于微软推荐的经典案例:Batch scoring of Spark models的主要内容,如果未能解决你的问题,请参考以下文章