MSRA AIOps 日志分析系统:LogCluster
Posted 智能运维前沿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MSRA AIOps 日志分析系统:LogCluster相关的知识,希望对你有一定的参考价值。
本文介绍一种基于聚类的问题识别系统——LogCluster,该系统针对于在线的大型软件系统的日志进行处理与分类,采用聚类方法,识别当前故障在之前是否发生过。如是,则直接采用成熟的止损方案。该系统由微软研究院实现并在微软的多个服务中实际部署,并发表于软件工程顶会ICSE 2016。
随着互联网发展,大型的互联网服务系统所处理的数据量、用户数量都十分的庞大。而整个系统也变得越来越复杂,尽管系统上线前都在测试环境中经过了系统而严格的测试,但在实际生产环境中仍然会发生许多不可预知的问题。而解决这些问题无法依靠传统的IDE的debug方式,在这种条件下,记录日志成为了目前的主流方式。要处理这些海量的日志,传统方式的关键字查询都会变得非常低效,运维人员急需一种更为高效便捷的问题查找和定位的工具。而本文所介绍的LogCluster系统,则正是在这一需求下产生的。
大规模的网络服务系统集群日志,总体上有着以下几点特征:
1. 每天实时产生的日志数量庞大。现代大型集群的机器数量巨大,网络结构复杂。某些全球服务的日志可达到每天超过10TB。
2. 许多网络服务都存在故障切换(failover)机制,这会导致存在大量的服务切换、启动和结束。这会导致简单的关键字查询方式在这种环境下受到严重影响。
3. 大型软件的生产环境中存在许多会周期出现的问题。例如,在服务失效时,往往会要求尽快恢复到可用状态,一些如重启服务器的方式可以快速地解决问题,但是不能找到问题根因;同时,集群机器的系统环境有差异,这也导致了在部分机器上出现的问题会在另外的机器上复现;另一方面,某些问题可能由网络故障等外部因素引发。
4. 日志多样性复杂。不同的日志类型、系统环境变化、服务版本都会导致出现的问题存在差异,相关的日志信息也会变得极为复杂。同时,不同的日志对于故障分析的重要性也不一样,有许多日志在正常和异常情况下均会出现,因此对于运维人员来说有效地区分这些日志是很必要的。
目前业界针对这些问题,也提出了许多算法来降低人工干预的程度,例如在ICSE’13上有相关的论文介绍使用执行序列的方式来检测异常等工作。但这些方式的准确度仍可以进一步提升。
本文所介绍的LogCluster系统,则是基于日志的聚类来进行问题标示和定位的。LogCluster系统通过对日志信息进行加权,将相似的日志序列聚为一类,再从分类的具体结果中学习出日志的执行序列。整个系统的步骤大致可分为两部:从测试环境中学习聚类结果和日志的执行序列;再将线上系统的实际日志与学习的结果进行比对来发现可能的异常相关日志集合。
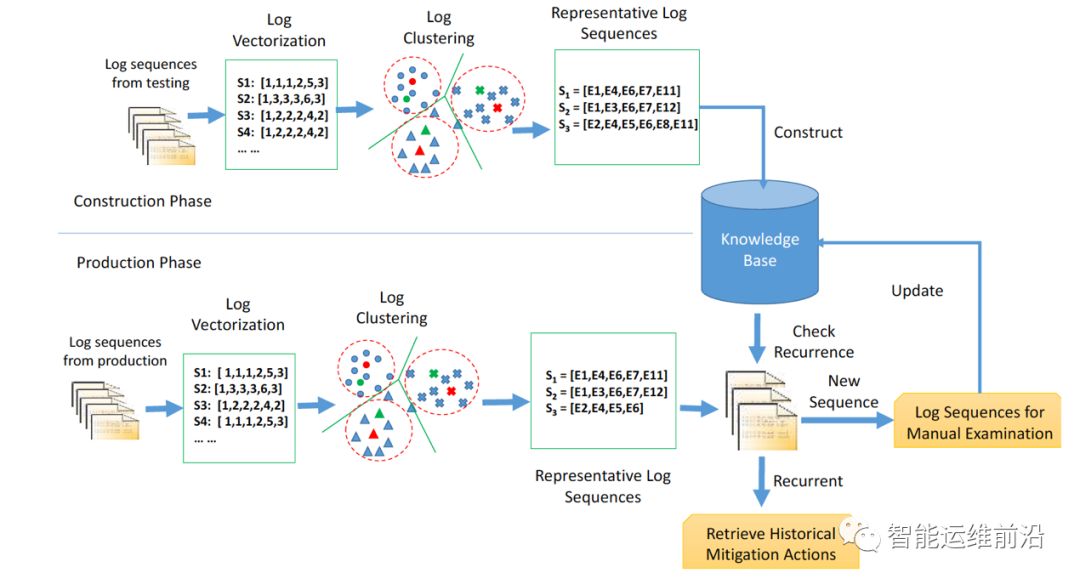
图1. LogCluster系统框架
LogCluster的系统框架如图1所示。整个系统的工作流程分为两部分:构建阶段(construction phase)和生产阶段(production phase)。
在构建阶段,使用的数据为线下环境下的日志数据。LogCluster系统将每条日志转化为对应的向量形式,对它们进行聚类。然后,再从每一类当中,选择代表性的日志序列,并将与该事件相关的解决方案一并存入到知识库当中。在生产阶段,LogCluster系统对实际生产环境的线上日志进行分析,提取日志序列并与知识库进行对比。若是已知的事件,那么则直接套用解决方案即可。若是未知的问题,再由运维人员进行人工核查。这样的流程能有效地减少人工检查的复杂度,提高工作效率。
上述的流程中,存在以下几个关键步骤,分别是:
• 日志向量化(Log Vectorization):将日志转化为向量形式并赋予相应的权重。
• 日志聚类(Log Clustering):计算不同日志之间的相似程度,并通过AHC算法(Agglomerative Hierarchical Clustering)进行聚类。
• 序列提取(Extracting Representative Log Sequence):在每一类中,提取代表性的日志序列。
• 重复比对(Checking Recurrence):对比生产环境的实际日志序列是否在知识库中已经出现。运维人员只需要人工关注那些新出现的事件。
下面分别对这些步骤的具体实现进行简单地叙述。
1. 日志向量化
LogCluster系统首先会将原始日志进行向量化。对于一条原始的日志来说,一般都包含两部分:文本格式的描述语句和关键的系统变量值(例如时间戳、类型等)。因此,将系统变量视为参数,语句视为常量字符串,可以将日志转化为抽象的日志事件(log event),下列两图分别是实际系统的日志和转化后的日志事件。
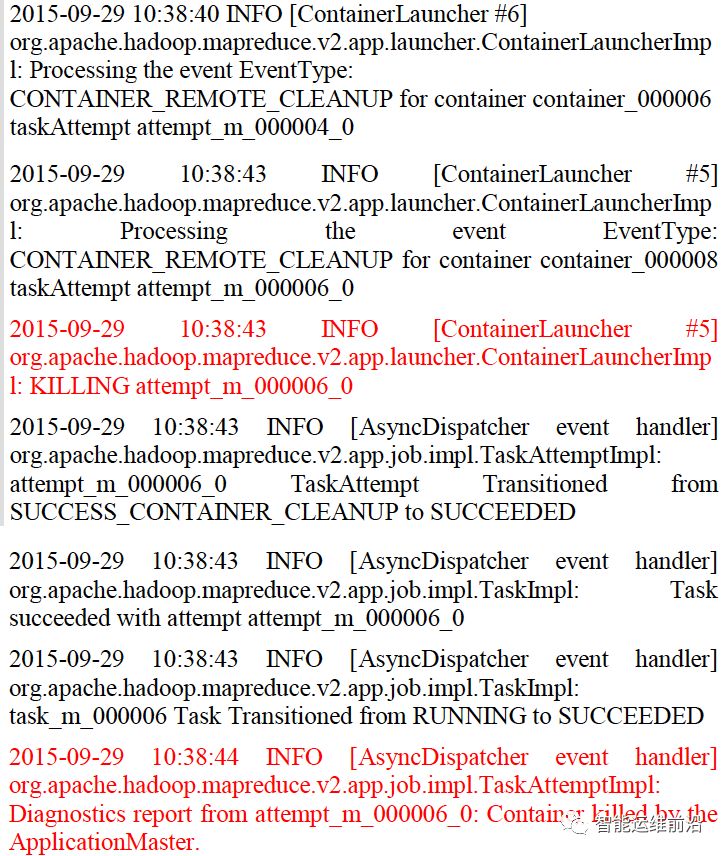
图2. 日志实例

图3. 对应的日志事件
在得到日志事件后,去除重复的日志事件,并通过相同的task ID将同一组日志加以区分,则可以得到一组日志事件的序列。一组序列中包含若干唯一的日志事件。
由于不同的日志事件对应的重要性不同,LogCluster相同还将对其进行赋权。LogCluster系统综合了两种算法,分别是文本分析中经典的IDF算法和基于对比的加权算法。具体公式分别如下:
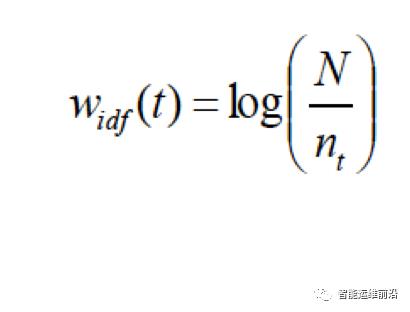
其中N代表日志序列总数,nt代表事件t出现的次数。

其中△S代表了仅在生产环境中出现的序列集合。也就是说,若一个序列仅在生产环境中出现,则赋值为1;否则(即生产环境和测试环境中都出现过),赋值为0。
最终的权值计算如下:
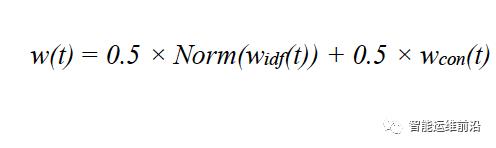
其中Norm表示标准化函数,将IDF值映射到[0,1]区间。在实际运行中使用Sigmoid函数。
最后,我们可以将日志序列转化为N维向量形式(N为日志事件的种类数),每一个元素表示一个日志事件的权值。例如,N=4的情况下,向量如下图所示。
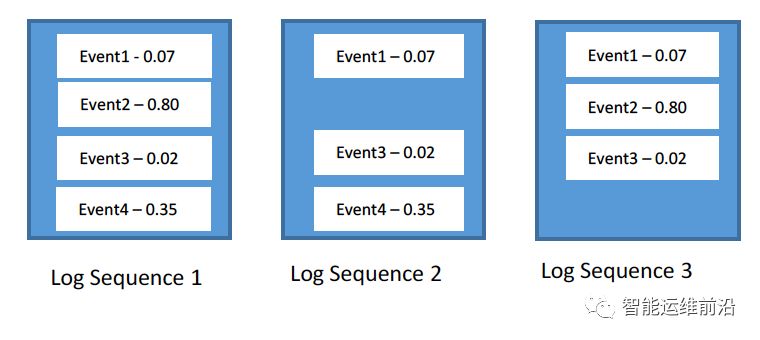
图4. 日志向量示例
以上三个向量分别为[0.07, 0.80, 0.02, 0.35],[0.07, 0.0, 0.02, 0.35]和[0.07, 0.80, 0.02, 0.0]。
2. 日志聚类
在向量化完成以后,我们可以通过如下方式来计算两个向量Si和Sj的相似度:
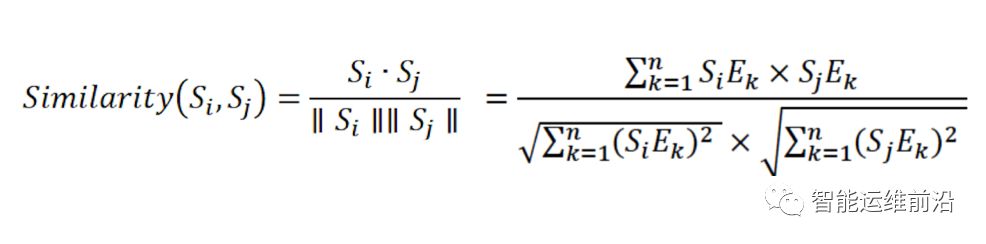
其中SiEk代表第i个向量中的第k个事件。
在AHC算法中,每次计算向量的相似程度,并将最相似的两个向量进行合并。该过程的抽象流程如下图所示。两个聚类之间的距离定义如下:两个聚类各取一个元素组成的元素对的距离的最大值。当所有聚类的距离都大于某个阈值时,该算法停止。在实际中该阈值设置为0.5。
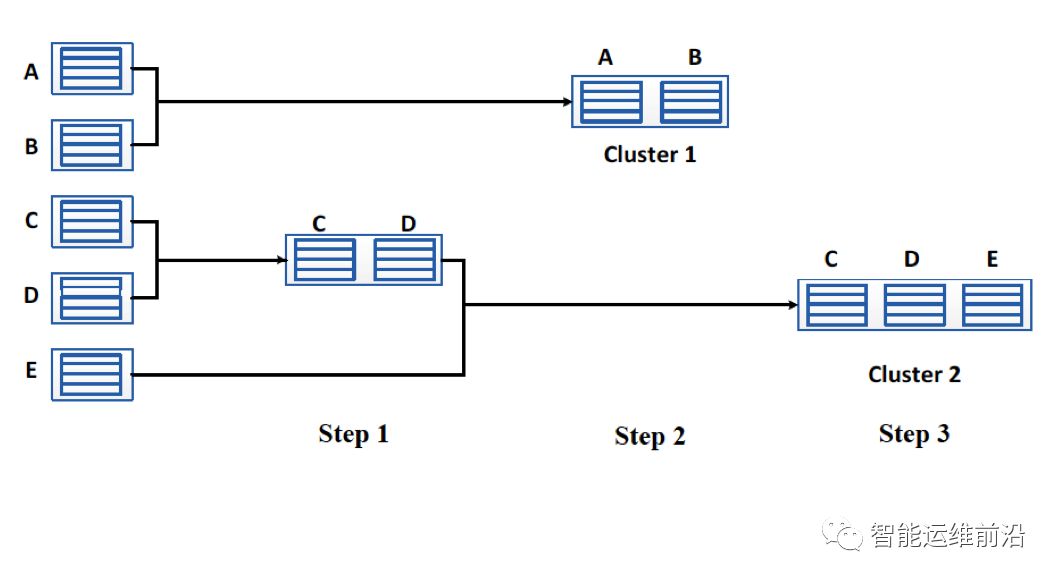
图5. AHC算法流程
3. 序列提取
在得到聚类结果之后,LogCluster系统对每一个类别选取一个代表序列。具体的选择方法如下:
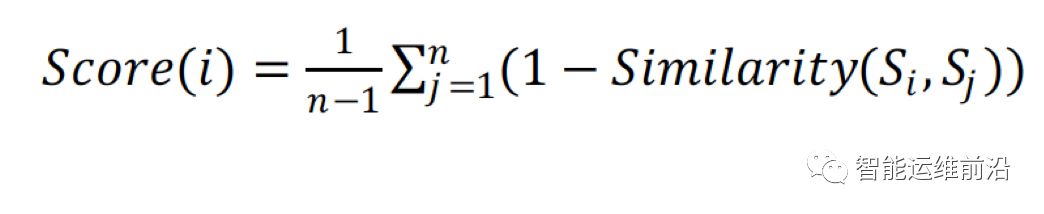
其中n表示该类别中包含的序列数量。该值反映了某一序列和其他序列的距离。最终选择score值最小的为代表序列。所有的类别对应的每一个代表序列就是运维人员进行人工核查的候选。
4. 复现比对
在线上服务系统中,有许多网络事件和故障都会复现。这些问题是已知的,并且它们的解决方案都非常完备。因此这些日志并不需要再由人工进行检查。
LogCluster系统进行查重的方式与上述的聚类算法一致,即把线上数据作为一个类别,进行聚类计算,若能和已知的知识库中的某一类聚合为一类,那么就是已知的问题。同时LogCluster系统也会将对应的解决方案报告给运维人员。相反的,若判明为一个新的类别,则需要进行人工检查。
通过这种方式,LogCluster系统能有效地减少人工检查的时间和工作量。
实验模拟真实的软件服务系统,因此应用的场景分为测试环境和生产环境。在测试环境中,实验团队不人工插入网络故障,在生产环境中,则会人工地插入不同类型的错误,包括机器宕机、网络通信故障和磁盘满等。
该系统主要与关键字查询的方法和ICSE’13的方法(W. Shang, Z. M. Jiang, H. Hemmati, B. Adams, A. E. Hassan, P. Martin, "Assisting developers of Big Data Analytics Applications when deploying on Hadoop clouds," in Proc. of the 35th International Conference on Software Engineering (ICSE 2013), pp.402-411, May 2013.)进行了对比。LogCluster系统在两个基于Hadoop的大数据应用上进行了测试,分别是WordCount(与Hadoop一同发布,MapReduce的示例程序。用于计算输入文件的词频)和PageRank(搜索引擎的网页排序程序)。除了Hadoop应用外,研究人员还从微软的其他团队获取了两个真实的网络服务系统日志作为实验数据(在下文中标记为服务X和服务Y)。这些服务的数据量都非常巨大,服务的用户数量都超过百万级别。
对于Hadoop应用,实验人员在运行过程中连续插入了三个机器宕机事件。效果如下表所示(括号内为准确率,即返回的所有日志与实际错误相关的比例):
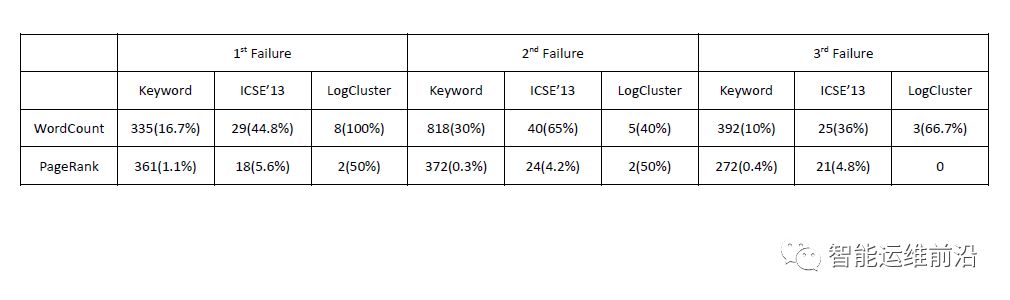
可以看出,LogCluster系统的结果大大减少了需要人工复核的日志数量。需要注意的时,由于错误类型一致,因此LogCluster系统在进行重复比对的步骤时可能会过滤掉已知的错误,因此PageRank的第三次错误返回的结果为0。
下表是不同的错误类型的实验结果:
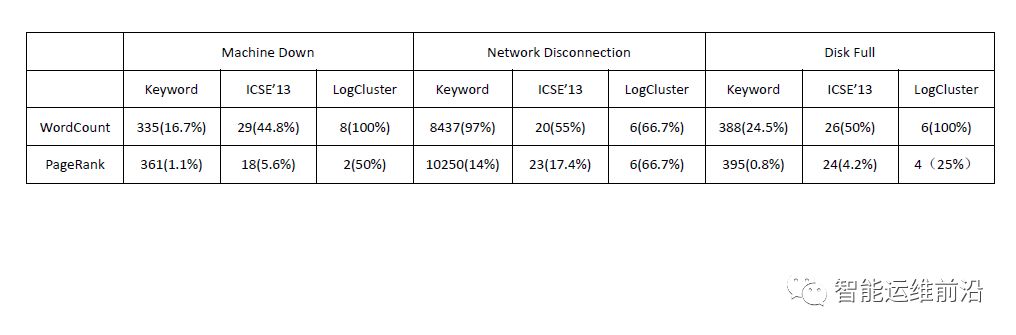
实验结果与之前类似。
在微软实际的服务系统上,该团队也进行了测试,结果如下:
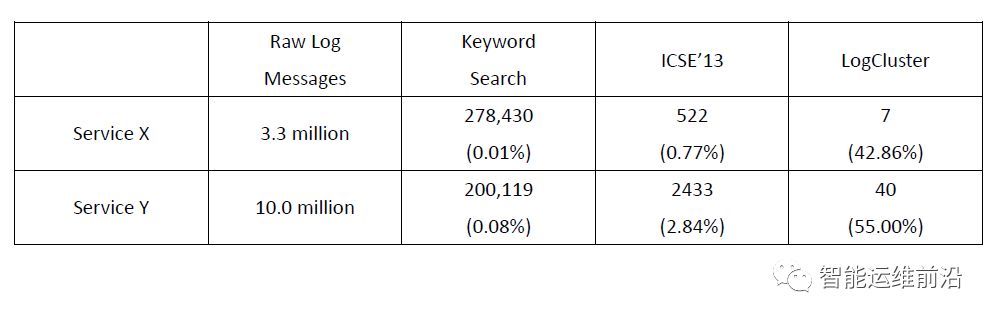
可以看出,在实验搭建的应用环境与实际的生产环境中,LogCluster系统相比已有的一些方法,其效果有显著的提升。LogCluster系统不仅能减少人工核查的工作量,同时其准确度也比之前的实现方式有大幅提高。
图6. LogCluster系统平均准确率与其他方法的对比
在实验中,研究人员也发现了LogCluster系统的一些局限性。在不同的平台上,LogCluster系统的性能会有所差异。同时,在实验中LogCluster系统也假定了测试环境内的日志均为正常,这与实际情况也有一定出入。另外,LogCluster系统也并未考虑日志序列的元素排列(例如,E1、E2、E3和E1、E3、E2视为同样的序列),这导致LogCluster系统不能检测某些性能故障。
自2013年起,LogCluster系统就被应用于微软的多个软件服务系统当中。由于保密性的原因,在文中各项服务均使用字母进行代替。
在某全球部署的网络服务A当中,LogCluster系统被用作日志分析系统的一部分。在此之前,服务A使用的方法为主动监测(Active Monitoring,或称Synthetic Monitoring)。这种方法会预先定义并模拟用户操作,再把这些人造操作的结果与预期进行对比。这种方法只能发现已知的问题类型,在使用了LogCluster系统后,运维人员得以发现更多的问题类型。与此同时,恢复故障的时间也得到了大幅缩减。例如在2014年7月,该服务的某项组件发生了故障导致服务访问不稳定。LogCluster系统发现该日志序列对应的情况在历史上出现过,并迅速给出了已知的解决方案。这使得运维人员能快速地恢复线上事故。
在某故障根因分析产品G当中,LogCluster系统的聚类算法帮助产品对原始日志进行聚类。同时,该产品的团队也根据自己的专业领域知识,对每一类进行了评分和排序。在实际故障发生时,相关联的日志能够迅速地被定位,并根据它们的优先级进行人工排查。这一流程提高了异常的分析效率。
除上述的例子之外,LogCluster系统还被广泛应用在其他的服务系统当中,帮助运维人员发现异常、定位故障原因、查找解决方案。由于篇幅所限,这里我们不再展开。
在这些实际应用中,系统所面临的用户数量、日志数据量都非常巨大。而在实践当中LogCluster系统均能高效地完成自己的工作,有效地提升了人工效率,证明了该系统的价值。
本文介绍一种基于聚类的问题识别系统——LogCluster,该系统对软件日志进行处理与分类,有效提升了运维人员处理软件服务事故的效率。该系统被部署于微软的多个服务,有着显著的实际成果。
以上是关于MSRA AIOps 日志分析系统:LogCluster的主要内容,如果未能解决你的问题,请参考以下文章