如何用R语言做中文分词
Posted R语言数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用R语言做中文分词相关的知识,希望对你有一定的参考价值。
大家好,好久不更新,惭愧惭愧。
今天我们要介绍的是R语言的一个包,jiebaR。jiebaR顾名思义,是用来做分词的。中文文本处理的一大难点就是分词,jiebaR很好地为我们解决了这个问题。
好,那么我们就开整。我们需要的工具一共有两个:
1. RStudio
2. 毛主席的《实践论》txt文本
以下是代码:
#安装jiebaR
install.packages("jiebaR")
#载入jiebaR
library(jiebaR)
#读入《实践论》的txt文件,《实践论》的文本被赋给了变量article
article <- scan('实践论.txt', what = character(), encoding = "UTF-8")
#我们看一下article是什么样子的
article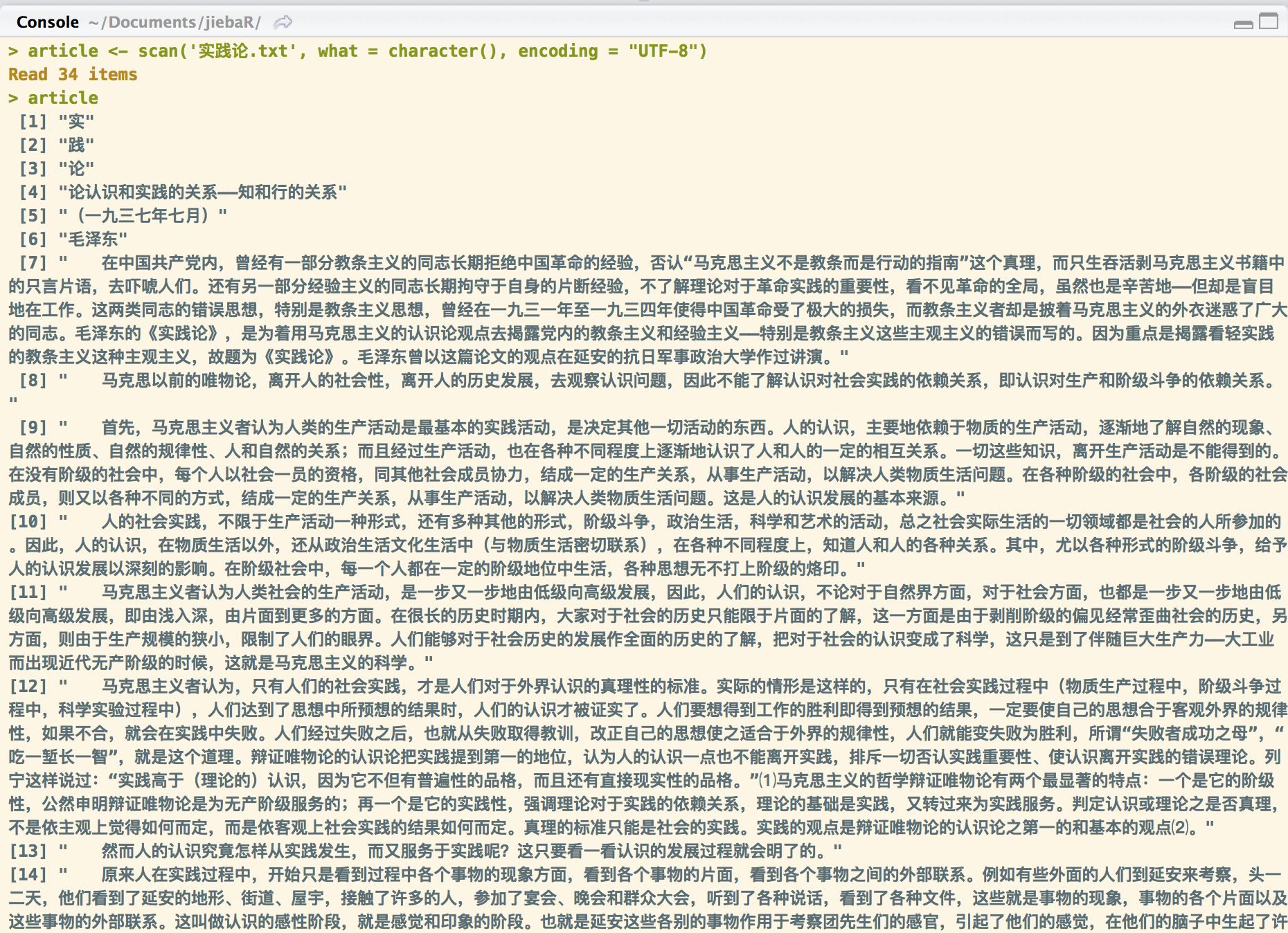
可以看到目前的《实践论》是没有经过分词的。
下面我们来分词,只需两行代码足矣~
#新建一个分词器
myseq <- worker()
#用分词器myseq对变量article(也即是实践论文本)进行分词,记得一定用中括号
myseg[article]经过上面两行代码,我们就完成了分词,我们看看分词以后的结果,
意不意外,惊不惊喜。
当然,以上只是jiebaR最最基本的功能,详细的使用指南大家可以看它的github主页,http://qinwenfeng.com/jiebaR/。
其中变化最多的就是分词器worker()了,对他进行不同的初始化,就会得到不同的分词器。比如下面,我们可以用worker()提取《实践论》中的关键词。
#新建关键词分词器,topn表示需要提取的关键词个数,这里就是20个
myseg <- worker("keywords", topn = 20)
#将文本合成一大段,粘贴在一起
article <- paste(article, collapse = '')
#用新的分词器去提取关键词
myseg[article]结果如下图所示,
排名第一的是“认识”,没错,实践论就是一种认识世界的方法论。第二个关键词就是“实践”,恰中文章的标题和中心。后面的词就不多说了,大家应该不会陌生。
以上只是中文文本挖掘的第一步,jiebaR还有很多酷炫的功能,我们之后再八。
以上是关于如何用R语言做中文分词的主要内容,如果未能解决你的问题,请参考以下文章