R语言文本挖掘—文本分词
Posted 菜鸟数据岛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言文本挖掘—文本分词相关的知识,希望对你有一定的参考价值。
书接上回,啪!啪!啪!
昨天我们讲了如何安装Java环境,安装了的小伙伴一定是备受折磨吧,哈哈哈!

我们输入两个短语:菜鸟数据岛,生活不止眼前的苟且。利用Rwordseg包里的segmentCN()函数做分词,运行之后我们得到的是下面这个运行结果,
>segmentCN(c("菜鸟数据岛", "生活不止眼前的苟且"))

感觉分词的效果很差,菜鸟,数据岛,苟且,都被强行拆散,这里我们就要进行加词和删词了,
>insertWords("数据岛")
>insertWords("菜鸟")
>insertWords("苟且")
加词之后我们再运行一下

明显的得到的分词效果更好些,还可以用deleteWords()函数来减少词库中的词。

>fenci <-readLines("D:/菜鸟/词频文件.txt",encoding="UTF-8")
这里要注意的是检查文件是否读出乱码,如果是有乱码的话就是文件的格式不匹配。
>length(fenci)#查看一下fenci的长度,是不是和我们的原始文件一致
>fenciTemp <- gsub("[0-90123456789 <>~]","",fenci)
#fenciTemp<-gsub(pattern="[a-zA-Z]+","",cipin))
#去掉一些数字和标点,有必要的话,可以去除掉英文,但是我们这个案例显然不能去掉
>fenciTemp <- segmentCN(fenciTemp)

这个分词是不是很糟糕啊,哈哈哈,没办法,谁让我懒呢,在这里我们其实是需要提前做一下词库的,或者可以上搜狗输入法官网下载别人做好的词库。

这里举个例子:
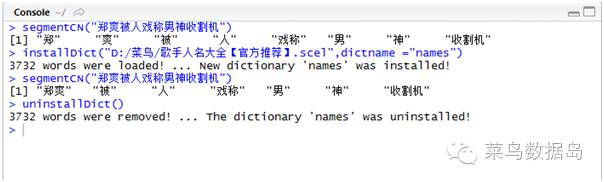
>segmentCN("郑爽被人戏称男神收割机")
第一次运行的时候能明显看出来“郑爽”这个人名被分开了,于是我就到搜狗输入法的网站下载了“歌手名人大全【官方推荐】“词库,下载后使用命令:
>installDict("D:/菜鸟/歌手人名大全【官方推荐】.scel", dictname="names") #加载词典
在运行之后可以看到“郑爽”就被分词到了一起,当然我们还可以使用命令:
>uninstallDict() #删除词典
首先你需要一个中文停词表,这个停词表也是需要不断修正的,听着就是很繁琐的工作。

然后我们需要编写函数,重新进行分词,去掉停词,在R中有的时候你是需要自己编写函数的,这个就需要你很扎实的统计学和线性代数的基础知识。

最后我们来比较一下,去停词之前和之后的区别

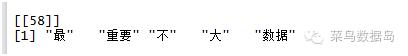
去掉停词的目的是,让分析更简单和精准
运行之后我们会得到一个按照词频从大到小的顺序排列的词云图
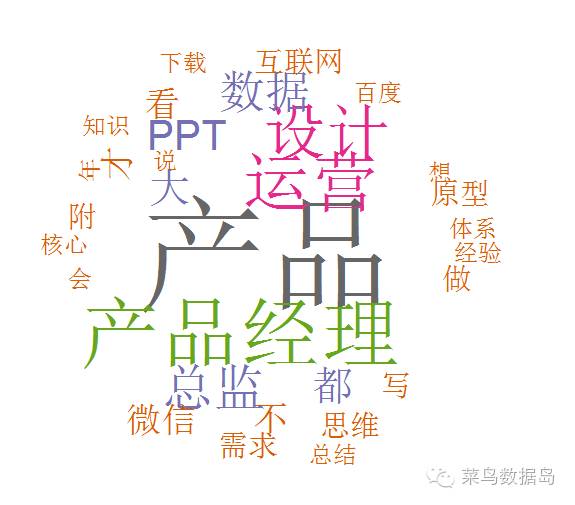
不是很好看,哈哈,不过如果你的文本词汇很多的话,是非常好的可以找出关键词的方法,在舆情分析中经常被用到。这里再给大家介绍一个傻瓜式的词云图制作的在线工具http://www.tagxedo.com/,在线就可以完成很棒的词云图啦,而且非常简单。这里我们就很容易看出来,这个文本的关键词是产品、产品经理、设计、运营、数据、总监、PPT依次从多到少。
以上是关于R语言文本挖掘—文本分词的主要内容,如果未能解决你的问题,请参考以下文章