基于LSTM-CRF的中文分词法
Posted 上海交通大学计算机科学与工程系
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于LSTM-CRF的中文分词法相关的知识,希望对你有一定的参考价值。
基于LSTM-CRF的中文分词法
曹诚
上海交通大学计算机科学与工程系,上海,200030
摘要:神经网络已被广泛应用到自然语言处理任务中。本文提出了一种基于长短期记忆神经网络(LSTM)改进的长短期记忆条件随机场(LSTM-CRF)模型,将其用于中文微博语料的分词标注工作。该方法结合LSTM能够利用上下文信息和CRF层考虑前后标签依赖关系的特性,并将字符表示成嵌入向量进行分词实验,结果表明:LSTM-CRF模型比LSTM和CRF模型具有更好的分词性能。
关键词:中文分词,神经网络,条件随机场
Chinese word Segmentation based on LSTM-CRF
Cao Cheng
Dept. of Computer Science & Engineering, Shanghai Jiao TongUniversity, Shanghai, 200030
Abstract: Neural network has been widely used in natural languageprocessing. In this paper, a long and short term memory condition Random Field(LSTM-CRF) model based on long and short term memory neural network (LSTM) isproposed, which is used for word segmentation of Chinese Weibo corpus. Thismethod combines LSTM with context information and CRF layer to consider theproperty of label dependency before and after, and the characters arerepresented as embedded vectors for word segmentation experiment. The resultsshow that the word segmentation performance of the LSTM model is better thanthat of LSTM and CRF models.
Keywords: Chinese participle, Neural network, Conditional random field
1 引言
在自然语言处理领域,人类可以通过自身的经验和知识理解语句的意思,计算机则不同,它需要对语句进行分词,通过理解分词的意思结合特征权值,对语料作出判断。所以,计算机进行中文文本挖掘处理的第一步通常是中文分词工作,其处理结果的好坏同时影响着之后工作的完成结果。与英文分词不同,中文语料中没有显式的分隔符将语句分割成词语。中文分词方法大致分为规则匹配、机器学习以及深度神经网络结构这三大类。
基于规则匹配方法通过遍历扫描语料,匹配寻找字符串中和分词词典相同的子字符串。这类分词还会加入一些多规则过滤的方法来提高分词效率,比如“正、反向最大匹配方法”、“长词优先提取方法”等分词方法。这类算法分词速度快,实现起来较简单;缺点是由于全部依赖分词词典,词语涵盖率相对有限,对歧义和未录入的词汇处理效果不佳,需要通过大规模扩充词典解决。
基于机器学习方法是以人工标注好的分词词性和统计特征为基础,训练建立分类模型,即计算机对标注好的语料进行观测和学习,估算并训练模型参数。将测试语料集经模型标注,取分词标注概率最大的结果为最终结果。通常情况下,采用机器学习的分词方案能很好地处理规则匹配方法的不足,效果普遍较好。然而此方法需要人工对大量数据进行标注,工程量大,分析速度也较慢。
目前较为常用的分词方法是将基于规则匹配与机器学习相结合的方法。文献[1]将词典信息融入统计模型,实现了在处理中文分词及标注过程。文献[2]将规则挖掘计算和传统的词性标注模型相结合,引入了规则优先级的词性标注算法对标注结果进行优化,很好的处理了未登陆词的问题。文献[3]基于词典通过CRFs模型对语料进行迭代分词。
基于深度神经网络结构的分词方法,能够从原始数据中自主学习,从而找到更深层次,更加抽象的特征。由于这些特征不是人为设定,这样使它规避了传统统计模型分词方法的局限所在,因此能够在自然语言处理任务中获得更好的表现。文献[4]利用神经网络提取特征,在英文语句标注方面获得了不错的效果。文献[5]按照文献[4]中提出的想法,将神经网络运用到中文分词任务上,并且用感知器算法替换了原本神经网络的训练算法,加速了整个训练过程。文献[6]在设置窗口用于获得上下文向量的基础上,增加了标签的嵌入转换层,以此加大上下文特征之间的关联,所取得的效果与传统方法效果相当。
本文利用LSTM模型能够保存上下文信息的优势,同时也利用了CRF层从句子层面考虑前后标注之间的影响,而不是只对神经网络层的输出进行简单的动态规划处理。应用基于长短时记忆模型的LSTM-CRF模型到中文分词任务中。
2 模型建立
2.1 LSTM
LSTM(LSTM,Long Short-Term Memory)是一种特殊的循环神经网络,具有能够学习的长期依赖的能力,比如在文本处理中能够利用很宽范围的上下文信息来判断下一个词的概率。Hochreiter和Schmidhuber[7]于1997年提出了它,随后,人们在此工作的基础上进行了很多完善和推广。
作为一种循环神经网络(RNN,Recurrent Neural Network)的改进模型,RNN虽然可以处理序列问题,但是具有严重的梯度消失问题,具体表现为越往后的节点对于前面的节点感知能力越低。因此为了解决梯度消失问题,研究者提出了长短时记忆神经网络。LSTM非常适合对序列数据进行处理,它通过“门机制”来记忆前面节点的信息,以此解决了梯度消失问题[8]。在LSTM中,每一个节点的结构相对传统的RNN更加复杂,其内部结构如图1所示,结构如图2所示。
图1-LSTM内部结构

图2-LSTM结构
从图1中可以看出,LSTM记忆单元中细胞状态的保存与更新由输入门,忘记门和输出门决定。其中输入门控制将新的信息中哪些部分保存到细胞状态中,忘记门决定历史细胞状态的保留信息,输出门控制全部更新后的细胞状态哪些部分被输出。LSTM单元具体工作流程用以下公式表示:
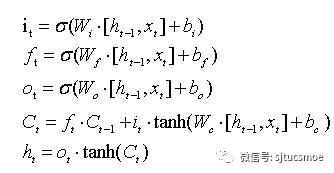
公式1-LSTM单元具体公式
其中,it,ft,ot,Ct分别表示t时刻输入门,忘记门,输出门和细胞状态的输出,xt和ht表示t时刻时的输入向量和隐藏层向量。σ表示sigmoid激活函数,W和b分别表示权重矩阵和偏置向量,它们的下标代表它们所属归类,如Wi和bi表示它们属于输入门结构中的权值矩阵和偏置向量。
LSTM神经网络通过LSTM记忆单元来保存前面的上下文信息,解决了RNN算法出现的长距离依赖问题,其结构图如图2所示。其中输入层为X,即语料库中每个字构造成的特征向量。输入层与输出层之间有隐藏层,Cell表示每一个LSTM记忆单元。输出层为y,即每个字对应的标注。
2.2 CRF模型
该算法最初由John Lefferty等人提出。作为一种无向图上的指数概率模型,结合并改进了隐式马尔可夫和最大熵模型用来对特征进行全局归一化处理,即计算需标注序列的全局概率。
条件随机场[9]的定义:假设有一个无向图,Y是基于无向图中节点的变量Yn组成的序列。在给定X的条件下,如果所有变量Yn都满足马尔科夫属性,即P(Yn|X , Ym, m~n)=P(Yn|X , Ym , m≠n),那么(X , Y)就构成一个随机场,其中,m≠n表示除n外的所有结点m,m~n表示m、n是相邻的两条边。换句话说,对于点n来说,只有跟它相邻的点才会对它产生影响。注意,定义中的X、Y并不要求具有相同结构。
对于给出的输入语句,条件随机场模型能计算出输出结果的条件概率。用X={X1,X2,X3...Xn}表示要标注的语句序列,Y={Y1,Y2,Y3...Yn}表示与X对应的已标注的结果序列。对于集合( X,Y),随机条件场由局部特征向量f和对应的条件权重参数集合λ确定,权重向量决定语句中不同词对应的权重。与特征对应的条件权重参数集合λ={λ1,λ2,λ3...λn}。条件随机场的全局特征向量的表示为:
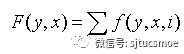
公式2-条件随机场全局特征向量的表示
F(y, x)表示,当i的任务是遍历标注全局集合的每个参数时,将i遍历到各参数时的特征加权而成的特征向量。于是,CRFs定义的条件概率分布为:

公式3-条件概率分布
P(Y,X)即所有可能的标注结果序列Y的概率之和。
2.3 LSTM-CRF模型
LSTM-CRF模型是将LSTM网络和CRF模型结合起来,即在LSTM网络的隐藏层后加一层CRF线性层。该模型通过LSTM层保存了上下文的特征,并且经由CRF层有效地考虑了句子前后的标签信息。
标注之间的状态转移矩阵,也就是CRF层的输入参数,是通过引入状态转移矩阵 A,然后设定矩阵 P 为LSTM网络的输出。其中 Ai,j表示时序上从第i个状态转移到第j个状态的概率,Pi,j表示输入观察序列中第i个词为第j个标注的概率。则观察序列X对应的标注序列y=(y1,y2,...,yn) 的预测输出为:
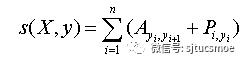
公式4-预测输出
3 实验结果
3.1 实验环境
本实验由于硬件条件有限,在研究深度神经网络时,没有采用GPU方式高效优化矩阵运算,而是采用CPU方式实现。表1为本实验的硬件和软件环境。
表1 环境配置表
CPU |
Intel(R) Core(TM) i7-6560U 2.20GHz 2.21GHz |
内存 |
8.0GB |
操作环境 |
Windows 10 64 bit |
编程工具及运行环境 |
Pycharm5 & Python 2.7 |
深度学习工具 |
NLP-Caffe |
3.2 数据集
本文使用从微博中抓取下来的1000条网友发布的日常生活类微博作为实验数据,这些微博与传统新闻文本不同,普遍具有语法不完整、标点符号运用不规范、网络用语多等特点,给分词工作带来一定难度。样本由两个人员分别独立标注完成,使用交叉验证的方法保证标注数据的可靠性。
为了构建特征向量,采用gensim工具,将训练语料中字符随机初始化,转化为向量,词语由相对应字符的向量组合而成。嵌入向量的维度选择50,100,150;嵌入层Dropout删除率设定为20%,40%。
3.3 实验标准
本文主要使用三个评价标准:正确率(Precision),召回率(Recall)和 F值(F-measure)。计算公式分别如下:

公式5-评价标准计算公式
3.4.1 实验结果
图3-LSTM分词
通过表3-1的测试结果,第三组数据的F-measure最高,所以可以设定之后的分词实验均是在嵌入维度为100,Dropout百分比为20%的条件下进行。
图4-LSTM、CRFs以及LSTM-CRF分词效果比较
3.4.2 实验分析
图3-2为LSTM-CRF模型与单纯基于机器学习和单纯基于深度学习在分词方面的对比。可以看出LSTM的分词正确率高,但是其召回率低,分类器不够稳定;CRFs的稳定性较高,但是其准确率不是很理想。相比之下,LSTM-CRF的正确率和召回率好于其它两项,分类器稳定性和准确率表现较好。其主要原因如下:
1. CRFs可以充分利用相邻标签之间的依赖关系来预测当前的标签,得到全局的最优解。如微博“上海申花和上海上港的德比之战太精彩了。上海上港虽然实力略胜一筹,但上海申花顽强的拼搏精神和犀利的反击,给我留下了深刻的印象。”其中“上海申花”、“上海上港”是足球队的名称。LSTM分词结果为“上海/申花”、“上海/上港”;LSTM-CRFs能结合所在的上下文语境,采用当前位置的前后n(n≥1)个位置上的字串确定特征模板,通过特征模板和标注语料训练模型。
2. 在一些长度较短的微博中,LSTM层能有效弥补CRF在处理简单标记问题上的不足,降低因数据量的规模和质量对模型训练效果的影响。如“上海人民调显示”,LSTM-CRF分词结果为“上海人/民调/显示”。
为了让实验指标具有参照性,本文运用目前较为常用的分词系统ICTCLAS2016分析训练集数据,标注准确率为96.4%。可见,本文方法略逊于高效分词系统。其主要原因如下:
1. 本文提出的系统具有一定的泛化能力,可以对训练数据中没有出现过的术语进行识别。但如果测试数据没有经过很好的标记的话,则会对分词的结果造成一定的影响。尤其对于一些专业术语,例如,“浮油松香”、“脂松香”等词语在参考结果中作为术语不进行拆分,本文提出的方法却对其进行了切分。
2. 在汉语分词相关任务中,由于训练语料规模和字表大小有限。对一些网络用语“无尿点”、“无语”、“正能量”无法进行有效识别。
3. 本方法不能使用未来的输入特征。由于LSTM是单向、单层次的运行模式,所以在特征挖掘过程中会有所疏漏,不能挖掘深层特征。
4 总结
本文的工作是在LSTM深度神经网络的基础上建立LSTM-CRF分词模型进行中文分词。对比LSTM模型和CRF模型,LSTM-CRF结合了能够保存上下文信息以及考虑前后标注的优势,达到了不错的分词性能。下一步工作考虑增加不同方向并行层和深度神经网络模型层数,更深一步提取特征向量,并针对中文语法特征优化向量嵌入模式。
参考文献
[1]. 邓知龙.基于感知器算法的高效中文分词与词性标注系统设计与实现[D].计算机科学与技术,哈尔滨工业大学:2013-6.
[2]. 李成栋.基于规则的汉语兼类词标注方法研究[D].计算机软件与理论,西南交通大学:2014-5.
[3]. 孙静,李军辉,周国栋.基于条件随机场的无监督中文词性标注[J].计算机应用与软件,2011,28(4):21-46.
[4]. Collobert R,Weston J,Bottou L. Natural languageprocessing(almost)from scratch[J]. Journal of Machine Learning Research,2011,12(1):2493-2537.
[5]. Zheng X,Chen H,Xu T. Deep learning for Chinese wordsegmentation and POS tagging[C].Conference on Empirical Methods in Natural Language Processing,2013:647-657.
[6]. Pei W,Ge T,Chang B. Max-margin tensor neuralnetwork for Chinese word segmentation[C]. Meeting of the Association for Computational Linguistics,2014:293-303.
[7]. Hochreiter S, Schmidhuber J.Long Short TermMemory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[8]. 张子睿,基于BI-LSTM-CRF模型的中文分词法[J],长春理工大学学报,2017(8),40(4): 87-92.
[9]. Bermingham,Smeaton,Classifying sentiment in microblogs:is brevity an advantage[C]//Proceedings of the 19th ACM internationalconference on Information and knowledge management,ACM,2010: 1833-1836.
作者邮箱:1026863114@qq.com
收稿时间:2018-07
发稿时间:2018-11
版权归上海交通大学计算机科学与工程系所有,如有转载请注明出处。
以上是关于基于LSTM-CRF的中文分词法的主要内容,如果未能解决你的问题,请参考以下文章