规则分词法|自然语言
Posted 桃陉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了规则分词法|自然语言相关的知识,希望对你有一定的参考价值。
写在前面
对于中文来说我们需要使用一些手段对其进行分词,再不同的语境可能会有不同划分方法。目前有基于规则分词、基于统计分词、基于理解分词等等。下面我们介绍的是基于规则分词的内容。分别为正向最大匹配法、逆向最大匹配法、双向最大匹配法。它们的基本思想很类似,所以只着重介绍正向最大分词法。
1.正向最大匹配法
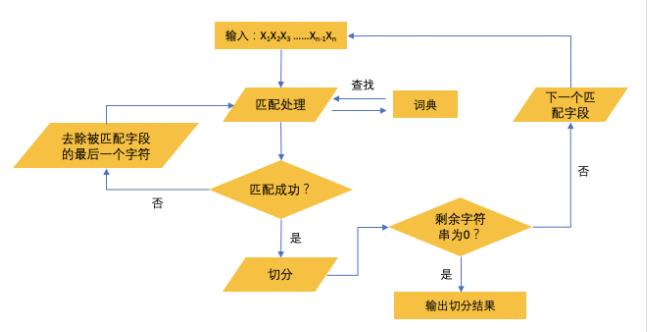
流程
∙ \\bullet ∙ 记录机器词典中最长词条的字符数为m。
∙ \\bullet ∙ 从左到右取待切分语句的m个字符作为匹配字段。
∙
\\bullet
∙ 查找词典进行匹配,匹配成功则将匹配字段作为一个词切出来;匹配失败则将匹配字段的最后一个字符去掉,重新匹配剩余字段,重复以上操作知道切分出所有的词为止。
代码
def cutA(sentence, dictA):
# sentence:要分词的句子
#dictA:机器词典
result = [] #存放分好的词
sentenceLen = len(sentence) #待分词字段长度
n = 0
maxDictA = max([len(word) for word in dictA]) #取词典中最长词条的字符长度
while sentenceLen>0:
maxCutLen = min(maxDictA,sentenceLen) #如果当前字段长度小于词典最长字段长度时,取当前字段长度进行划分
sub_sen = sentence[0:maxCutLen]
while maxCutLen>0:
if sub_sen in dictA:
result.append(sub_sen)
break
elif len(sub_sen)==1:
#长度为1说明词典中并无此词,则直接放入result中
result.append(sub_sen)
break
else:
#否则,删去最后一个字,重新操作
maxCutLen-=1
sub_sen = sub_sen[0:maxCutLen]
#更新当前未匹配字段及其长度
sentence = sentence[maxCutLen:]
sentenceLen -=maxCutLen
print(result) # 输出分词结果
2.逆向最大匹配法
流程
∙ \\bullet ∙ 基本思想完全相同,只是从后往前进行操作。
代码
def cutB(sentence,dictB):
result = []
sentenceLen = len(sentence)
maxDictB = max([len(word) for word in dictB])
while sentenceLen>0:
maxCutLen = min(sentenceLen,maxDictB)
sub_sen = sentence[-maxCutLen:]
while maxCutLen>0:
if sub_sen in dictB:
result.append(sub_sen)
break
elif len(sub_sen)==1:
result.append(sub_sen)
break
else:
maxCutLen-=1
sub_sen = sub_sen[-maxCutLen:]
sentence = sentence[0:-maxCutLen]
sentenceLen -= maxCutLen
print(result[::-1],end="")
3.双向最大匹配法
双向最大匹配法是基于正向最大匹配法和逆向最大匹配法之间的比较,选取词切数较小的作为结果。
流程
∙ \\bullet ∙ 比较正向最大匹配和逆向最大匹配结果;
∙ \\bullet ∙ 如果分词数量结果不同,那么取分词数量较少的那个;
∙ \\bullet ∙ 在分词数量结果相同的情况下,如果分词结果相同,则可以返回任何一个;如果分词结果不同,则返回单字数比较少的那个。
代码
class BiMM():
def __init__(self):
self.window_size = 3 # 字典中最长词数
def MMseg(self, text, dict): # 正向最大匹配算法
result = []
index = 0
text_length = len(text)
while text_length > index:
for size in range(self.window_size + index, index, -1):
piece = text[index:size]
if piece in dict:
index = size - 1
break
index += 1
result.append(piece)
return result
def RMMseg(self, text, dict): # 逆向最大匹配算法
result = []
index = len(text)
while index > 0:
for size in range(index - self.window_size, index):
piece = text[size:index]
if piece in dict:
index = size + 1
break
index = index - 1
result.append(piece)
result.reverse()
return result
#r1和r2分别为正向最大匹配法和逆向最大匹配法的切割列表
def main(self, text, r1, r2):
if len(r1) > len(r2):
print(r2,end="")
elif len(r1) < len(r2):
print(r1,end="")
else:
num1 = len(list(filter(lambda s: isinstance(s, str) and len(s) == 1, r1))) # filter()用于过滤,提取列表中长度为1的字符
num2 = len(list(filter(lambda s: isinstance(s, str) and len(s) == 1, r2)))
if num1 == num2:
print(r1,end="")
elif num1 > num2:
print(r2,end="")
else:
print(r1,end="")
以上是关于规则分词法|自然语言的主要内容,如果未能解决你的问题,请参考以下文章