大数据7|Hive数据仓库
Posted 悠闲是蓝蓝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据7|Hive数据仓库相关的知识,希望对你有一定的参考价值。


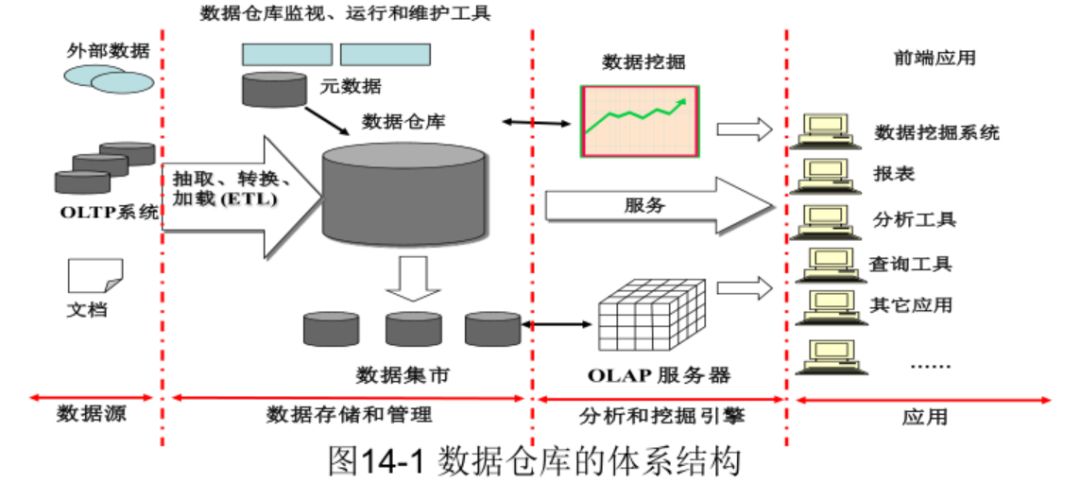
数据仓库Data Warehouse
数据仓库:
面向主题Subject Oriented
集成integrated
相对稳定non-volatile
反映历史变化Time Variant
用于:
管理决策(企业)OLTP多维数据分析
特点
相对稳定
只读
基本保留全部历史数据
传统数据仓库无法满足
快速增长的海量数据存储需求
处理不同类型数据
计算能力不足
Hive简介
hive
facebook开发
贡献给了apache
因为基于oracle的数据仓库无法满足
hive数据仓库工具
构建在hadoop顶层
支持大规模数据存储,分析,拓展性好
可视为用户编程接口--提供编程语言
本身不存储,处理数据
hive借鉴sql语言设计新的查询语言hiveQL
编写HiveQL可运行MapReduce任务
容易把原构建在关系数据库上的数据仓库应用程序移植到Hadoop
很直观的数据分析工具
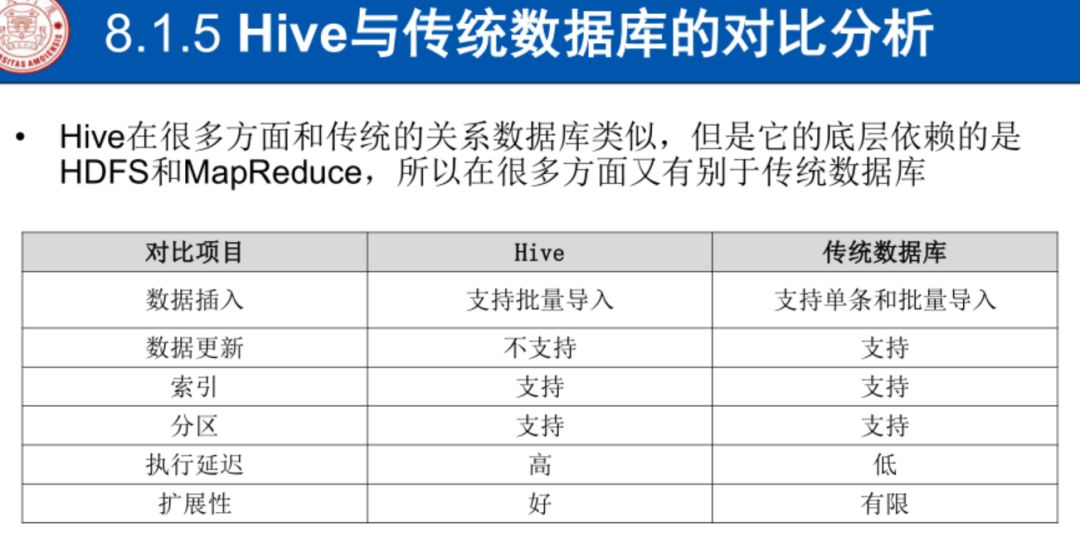
hive显著特点1-采用批处理处理
HiveQL语句转成MapReduce任务运行
存储的是静态数据,数据变化不频繁
特点2-有对数据提取,转化,加载ETL工具
满足数据仓库各类应用场景
与hbase互补,满足实时交互
缺点
只支持批量导入
不支持更新(只读)因为hdfs
分钟级响应海量数据
依赖hadoop,有其对应缺点

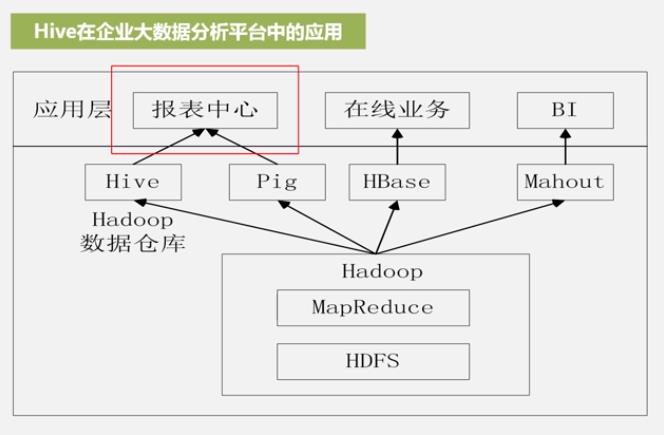
hbase交互性,实时性
mahout部署了数据挖掘,机器学习算法。
HBase架构
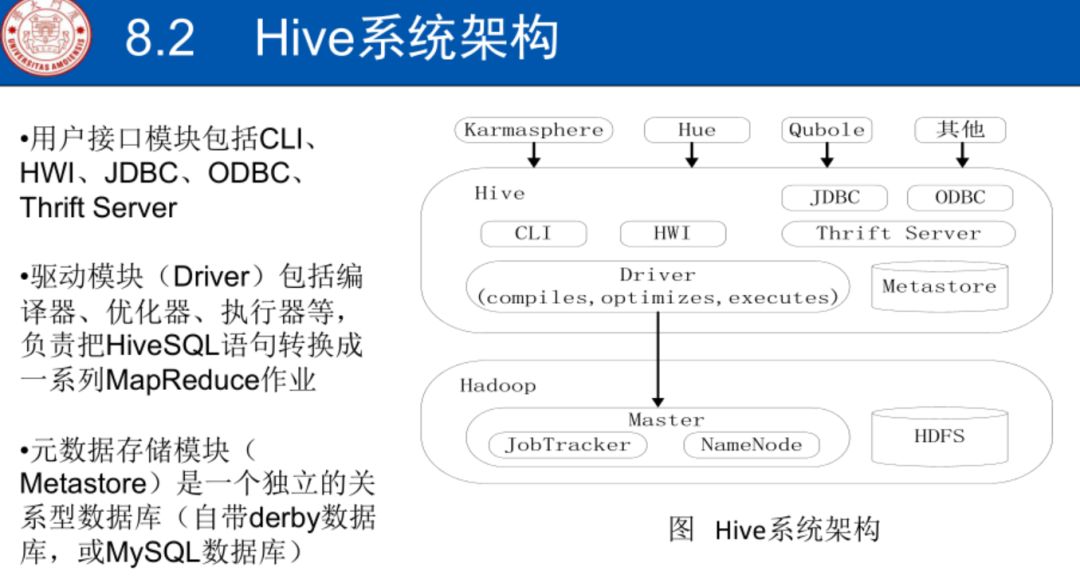
3个核心模块
对外访问接口
驱动模块
元数据存储模块
Qubole
直接作为服务提供给用户
不需要再企业部署数据仓库,可直接用亚马逊AWS云平台远程属于数据仓库
整个数据仓库集群管理让亚马逊来

在实际应用中,Hive也暴露出不稳定的问题
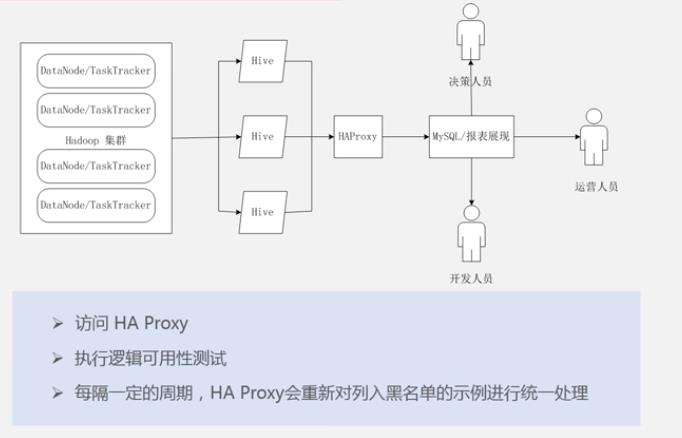
解决方案:Hive HA(High Availability)
高可用性hive解决方案
Hive实例被纳入到一个资源池中,并由HAProxy提供一个统一的对外接口
对编程人员透明
Hive工作原理
hive本身不做具体数据处理和存储
把sql转给MapReduce作业
过程
编写map处理逻辑
a输入关系数据库表
通过map对数据转换
用户向Hive输入命令,Hive需要与Hadoop交互工作来完成该操作:
驱动模块接收该命令或查询编译器
对该命令解析编译
优化器对该命令进行优化计算
通过执行器执行
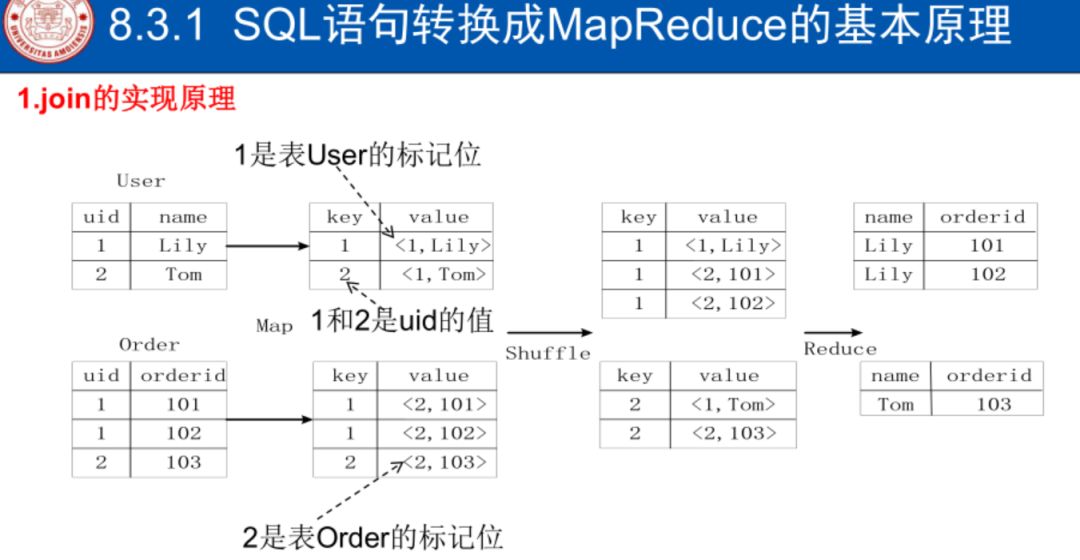
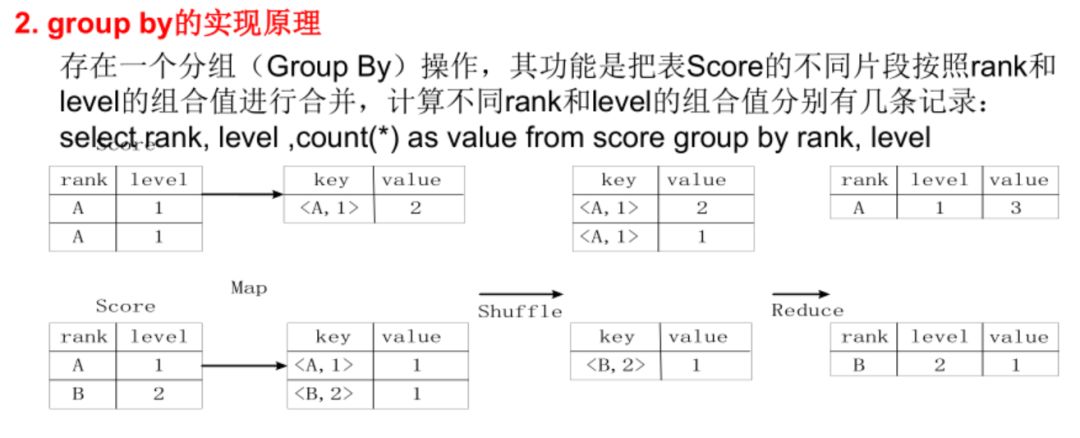
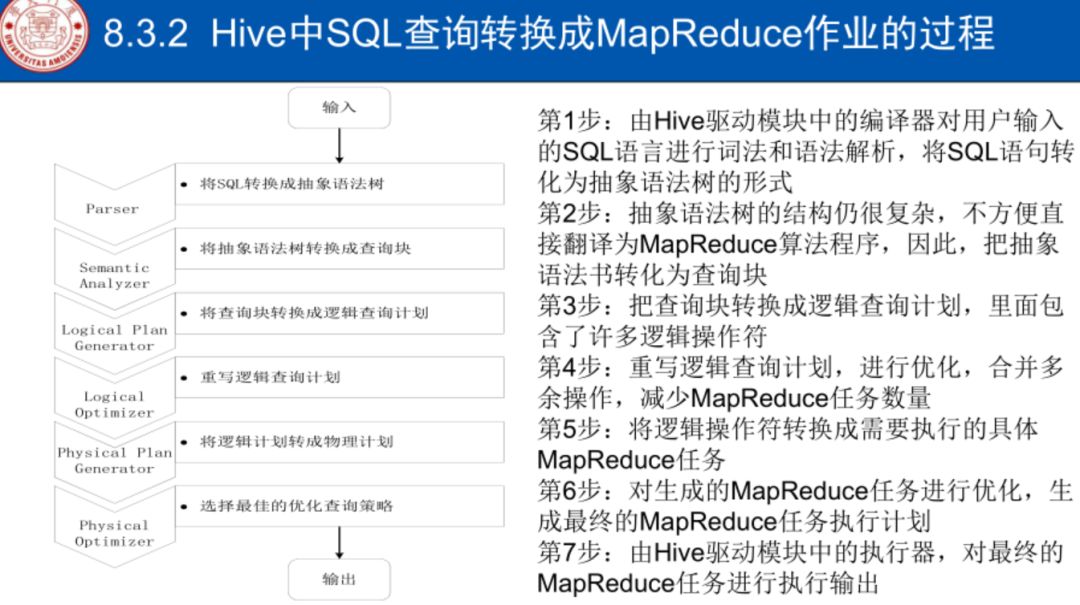
驱动模块:sql抽象为树
树→查询块
逻辑查询
优化,合并,减少MapReduce数量
执行器执行

网关机主要是远程操作和管理节点上的JobTracker通信来执行任务
XML文件驱动模块

Impala

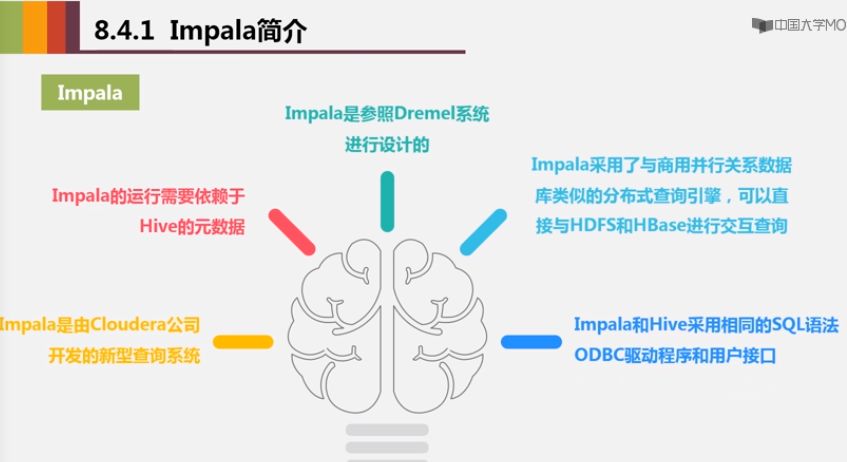
Cloudera公司开发
提供SQL语义,能查询存储在Hadoop的HDFS和HBase上的PB级大数据,在性能上比Hive高出3~30倍
运行需要依赖于Hive的元数据
可以直接与HDFS和HBase进行交互查询【不需要转化为MapReduce任务】
和Hive采用相同的SQL语法、ODBC驱动程序和用户接口

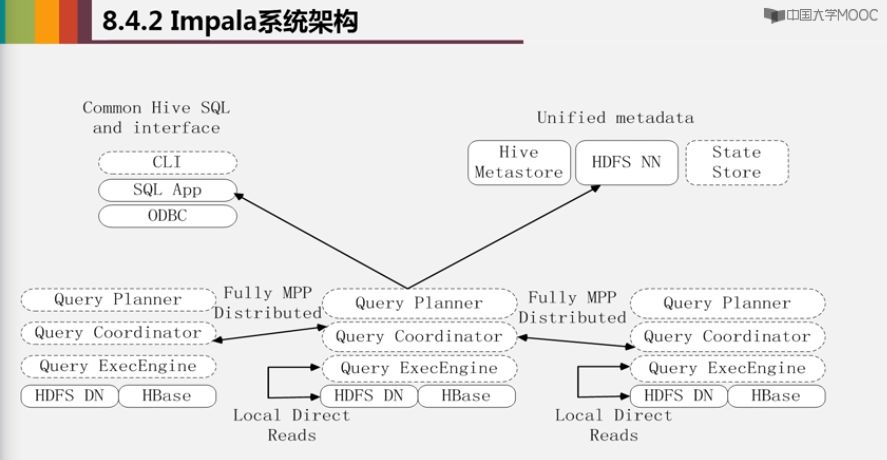
和Hive、HDFS、HBase等统一部署在一个Hadoop平台上的
虚线是Impala,实线是hadoop其他组件
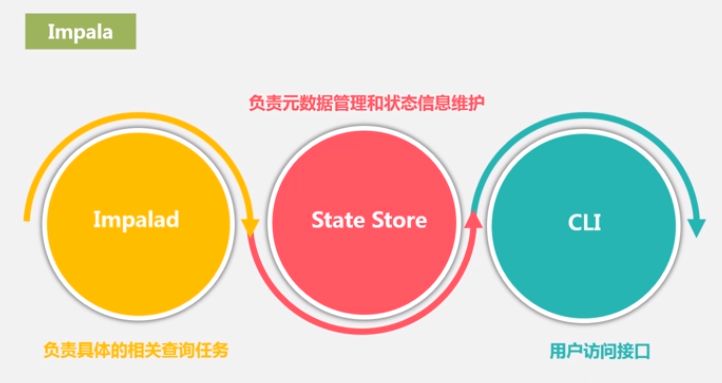
三部分组成

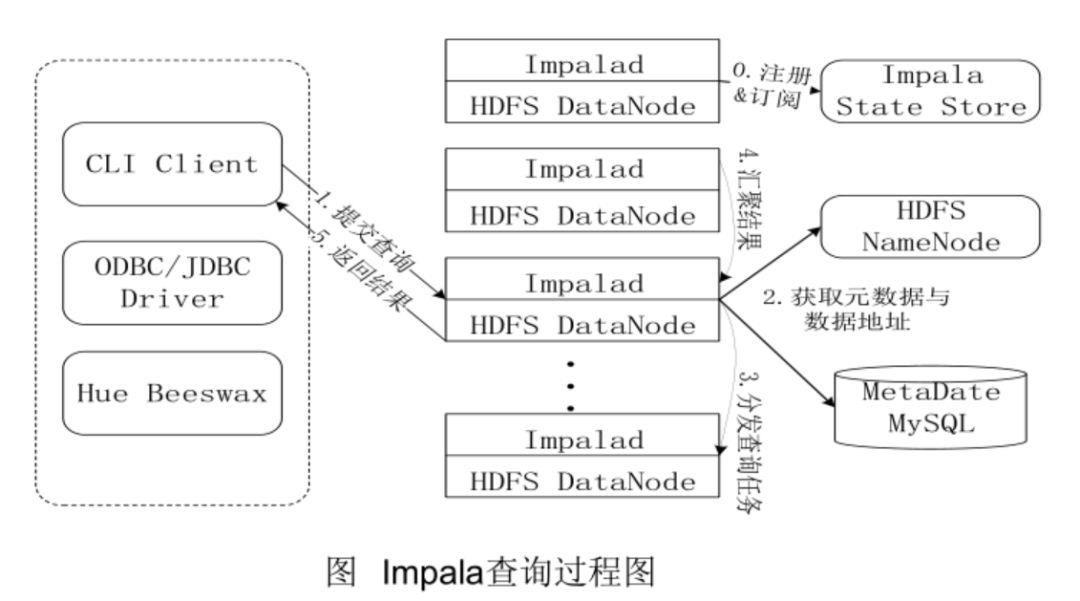
Impala查询过程
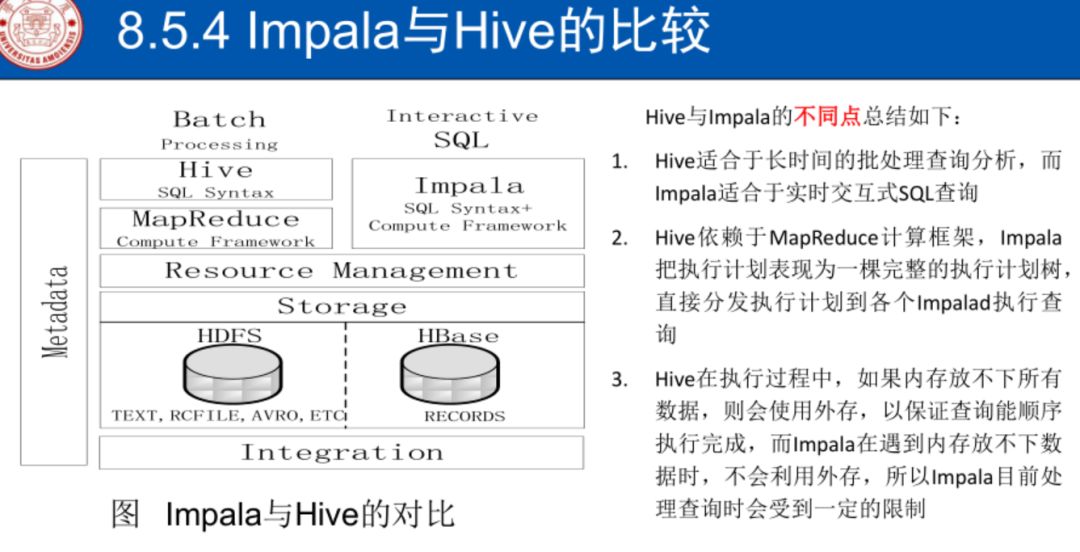
hive与impala不同
hive批量处理
impala实时交互sql查询
hive依赖MapReduce
impala生成执行树下发任务
hive可用外存
impala不会用外存,快但查询受限
hive和impala相同点
相同的存储数据池,都支持把数据存储于HDFS和HBase中
相同的元数据
对SQL的解释处理比较相似
总结
Impala的目的不在于替换现有的MapReduce工具
二者配合使用效果最佳
Hive先进行数据转换处理,之后再使用Impala在Hive处理后的结果数据集上进行快速的数据分析
hive编程实践
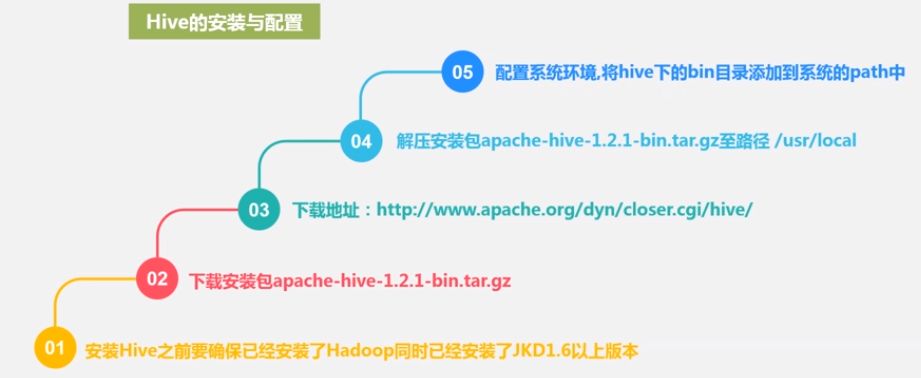

Hive有三种运行模式,单机模式、伪分布式模式、分布式模式。
均是通过修改hive-site.xml文件实现,如果文件不存在,可参考$HIVE_HOME/conf目录下的hive-default.xml.template文件新建。
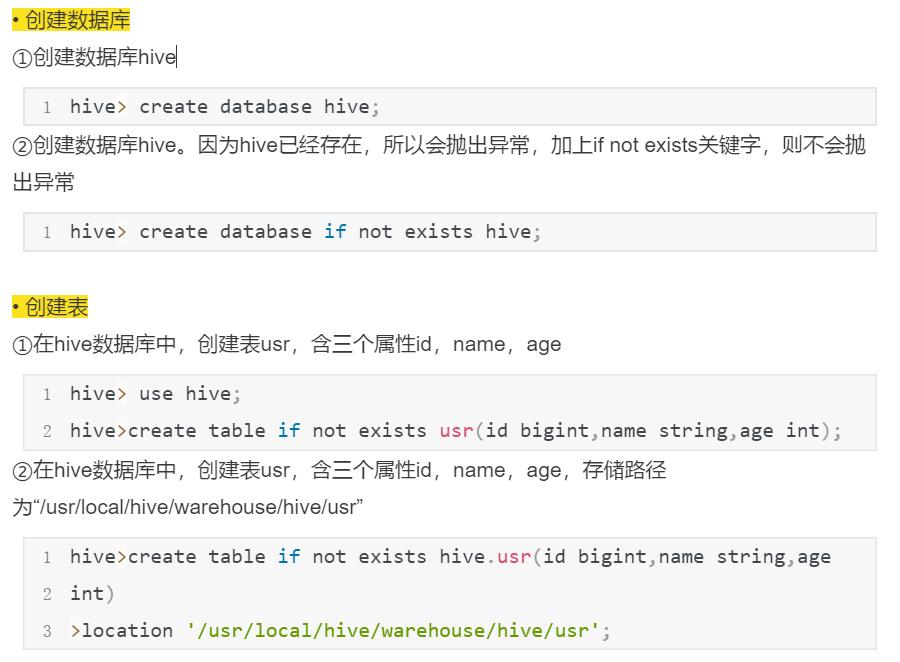
create database hive;等
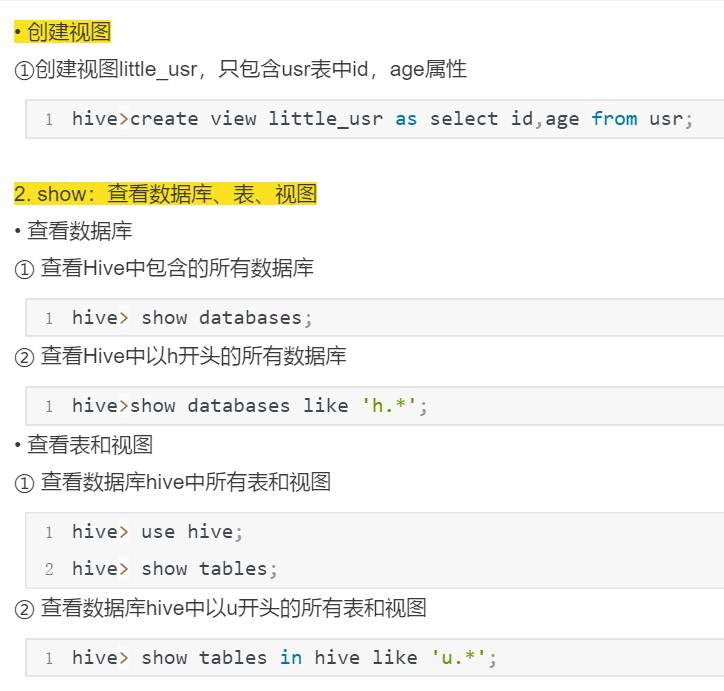
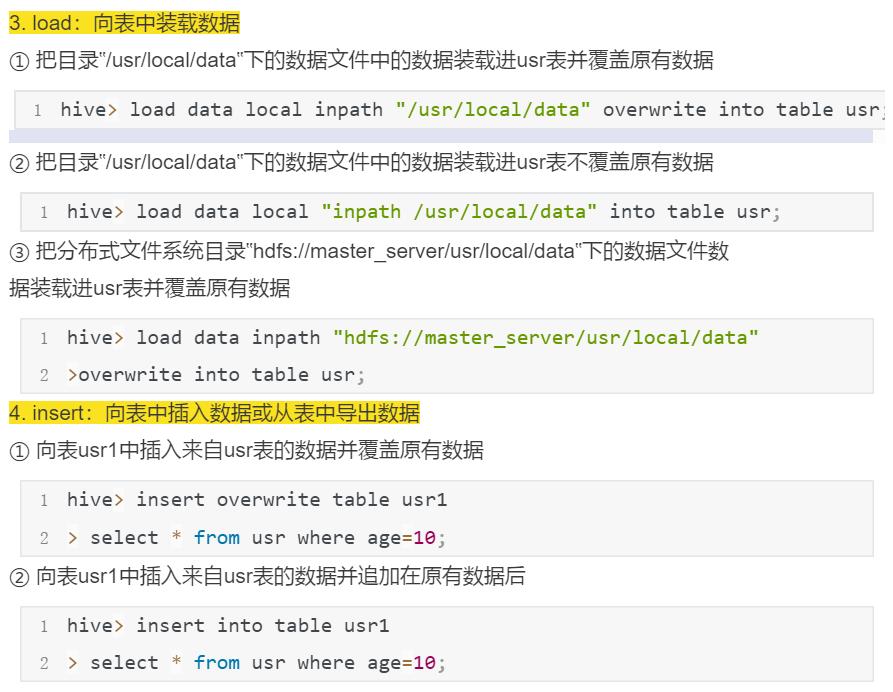
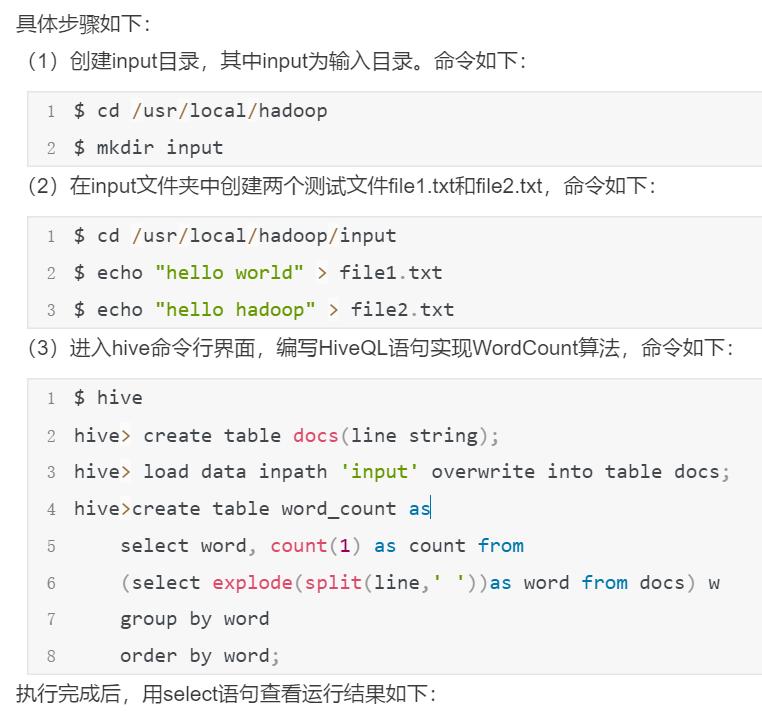
Hive中编程实现WordCount算法
在MapReduce中的编程实现和Hive中编程实现的主要不同点:
Hive代码量较少
在MapReduce需要编译生成jar文件来执行算法,而在Hive中不需要
HiveQL语句的最终实现需要转换为MapReduce任务来执行,这都是由Hive框架自动完成的,用户不需要了解具体实现细节

小总结
Hive是构建于Hadoop顶层的数据仓库工具,主要用于对存储在 Hadoop 文件中的数据集进行数据整理、特殊查询和分析处理。
Hive在某种程度上可以看作是用户编程接口,本身不存储和处理数据,依赖HDFS存储数据,依赖MapReduce处理数据。
Hive支持使用自身提供的命令行CLI、简单网页HWI访问方式,及通过Karmasphere、Hue、Qubole等工具的外部访问。
Hive在数据仓库中的具体应用中,主要用于报表中心的报表分析统计上。在Hadoop集群上构建的数据仓库由多个Hive进行管理,具体实现采用Hive HA原理的方式,实现一台超强“hive"。
Impala作为新一代开源大数据分析引擎,支持实时计算,并在性能上比Hive高出3~30倍,甚至在将来的某一天可能会超过Hive的使用率而成为Hadoop上最流行的实时计算平台。
以单词统计为例,介绍了如何使用Hive进行简单编程。
排版|悠闲是蓝蓝
文案|悠闲是蓝蓝呀
谦虚,低调,棒槌优越感
以上是关于大数据7|Hive数据仓库的主要内容,如果未能解决你的问题,请参考以下文章
大数据数据仓库-基于大数据体系构建数据仓库(Hive,Flume,Kafka,Azkaban,Oozie,SparkSQL)