教程 | 通过PyTorch实现对抗自编码器
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了教程 | 通过PyTorch实现对抗自编码器相关的知识,希望对你有一定的参考价值。
选自Paperspace Blog
机器之心编译
参与:Jane W、黄小天
「大多数人类和动物学习是无监督学习。如果智能是一块蛋糕,无监督学习是蛋糕的坯子,有监督学习是蛋糕上的糖衣,而强化学习则是蛋糕上的樱桃。我们知道如何做糖衣和樱桃,但我们不知道如何做蛋糕。」
Facebook 人工智能研究部门负责人 Yann LeCun 教授在讲话中多次提及这一类比。对于无监督学习,他引用了「机器对环境进行建模、预测可能的未来、并通过观察和行动来了解世界如何运作的能力」。
深度生成模型(deep generative model)是尝试解决机器学习中无监督学习问题的技术之一。在此框架下,需要一个机器学习系统来发现未标记数据中的隐藏结构。深度生成模型在许多应用中有许多广泛的应用,如密度估计、图像/音频去噪、压缩、场景理解(scene understanding)、表征学习(representation learning)和半监督分类(semi-supervised classification)。
变分自编码器(Variational Autoencoder/VAE)使得我们可以在概率图形模型(probabilistic graphical model)的框架下将这个问题形式化,在此框架下我们可以最大化数据的对数似然值的下界。在本文中,我们将介绍一种最新开发的架构,即对抗自编码器(Adversarial Autoencoder),它由 VAE 启发,但它在数据到潜在维度的映射方式中(如果现在还不清楚,不要担心,我们将在本文中重新提到这个想法)有更大的灵活性。关于对抗自编码器最有趣的想法之一是如何通过使用对抗学习(adversarial learning)将先验分布(prior distribution)运用到神经网络的输出中。
如果想将深入了解 Pytorch 代码,请访问 GitHub repo(https://github.com/fducau/AAE_pytorch)。在本系列中,我们将首先介绍降噪自编码器和变分自编码器的一些背景,然后转到对抗自编码器,之后是 Pytorch 实现和训练过程以及 MNIST 数据集使用过程中一些关于消纠缠(disentanglement)和半监督学习的实验。
背景
降噪自编码器(DAE)
我们可在自编码器(autoencoder)的最简版本之中训练一个网络以重建其输入。换句话说,我们希望网络以某种方式学习恒等函数(identity function)f(x)= x。为了简化这个问题,我们将此条件通过一个中间层(潜在空间)施加于网络,这个中间层的维度远低于输入的维度。有了这个瓶颈条件,网络必须压缩输入信息。因此,网络分为两部分:「编码器」用于接收输入并创建一个「潜在」或「隐藏」的表征(representation);「解码器」使用这个中间表征,并重建输入。自编码器的损失函数称为「重建损失函数(reconstruction loss)」,它可以简单地定义为输入和生成样本之间的平方误差:
当输入标准化为在 [0,1] N 范围内时,另一种广泛使用的重建损失函数是交叉熵(cross-entropy loss)。
变分自编码器(VAE)
变分自编码器对如何构造隐藏表征施加了第二个约束。现在,潜在代码的先验分布由设计好的某概率函数 p(x)定义。换句话说,编码器不能自由地使用整个潜在空间,而是必须限制产生的隐藏代码,使其可能服从先验分布 p(x)。例如,如果潜在代码上的先验分布是具有平均值 0 和标准差 1 的高斯分布,则生成值为 1000 的潜在代码应该是不可能的。
这可以被看作是可以存储在潜在代码中的信息量的第二类正则化。这样做的好处是现在我们可以作为一个生成模型使用该系统。为了创建一个服从数据分布 p(x)的新样本,我们只需要从 p(z)进行采样,并通过解码器来运行该样本以重建一个新图像。如果不施加这种条件,则潜在代码在潜在空间中的分布是随意的,因此不可能采样出有效的潜在代码来直接产生输出。
为了强制执行此属性,将第二项以先验分布与编码器建立分布之间的 KL 散度(Kullback-Liebler divergence)的形式添加到损失函数中。由于 VAE 基于概率解释,所使用的重建损失函数是前面提到的交叉熵损失函数。把它们放在一起我们有:
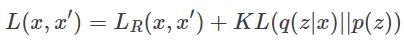
或
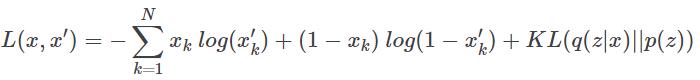
其中 q(z|x) 是我们网络的编码器,p(z) 是施加在潜在代码上的先验分布。现在这个架构可以使用反向传播(backpropagation)联合训练。
对抗自编码器(AAE)
作为生成模型的对抗自编码器
变分自编码器的主要缺点之一是,除了少数分布之外,KL 散度项的积分不具有封闭形式的分析解法。此外,对于潜在代码 z 使用离散分布并不直接。这是因为通过离散变量的反向传播通常是不可能的,使得模型难以有效地训练。这篇论文介绍了在 VAE 环境中执行此操作的一种方法(https://arxiv.org/abs/1609.02200)。
对抗自编码器通过使用对抗学习(adversarial learning)避免了使用 KL 散度。在该架构中,训练一个新网络来有区分地预测样本是来自自编码器的隐藏代码还是来自用户确定的先验分布 p(z)。编码器的损失函数现在由重建损失函数与判别器网络(discriminator network)的损失函数组成。
图中显示了当我们在潜在代码中使用高斯先验(尽管该方法是通用的并且可以使用任何分布)时 AAE 的工作原理。最上面一行相当于 VAE。首先,根据生成网络 q(z|x) 抽取样本 z,然后将该样本发送到根据 z 产生 x' 的解码器。在 x 和 x' 之间计算重建损失函数,并且相应地通过 p 和 q 反向推导梯度,并更新其权重。
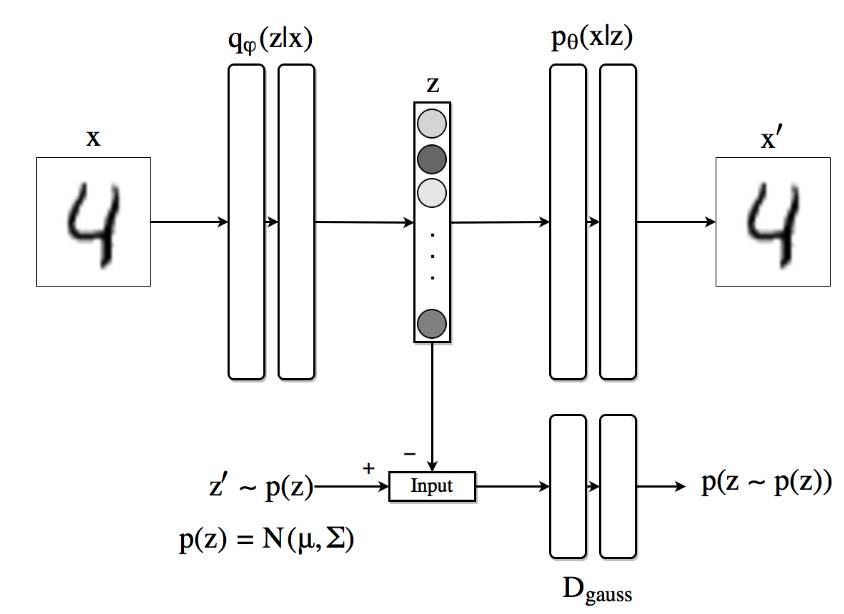
图 1. AAE 的基本架构最上面一行是自编码器,而最下面一行是对抗网络,迫使到编码器的输出服从分布 p(z)。
在对抗正则化部分,判别器收到来自分布为 q(z|x)的 z 和来自真实先验 p(z) 的 z' 采样,并为每个来自 p(z)的样本附加概率。发生的损失函数通过判别器反向传播,以更新其权重。然后重复该过程,同时生成器更新其参数。
我们现在可以使用对抗网络(它是自编码器的编码器)的生成器产生的损失函数而不是 KL 散度,以便学习如何根据分布 p(z)生成样本。这种修改使我们能够使用更广泛的分布作为潜在代码的先验。
判别器的损失函数是
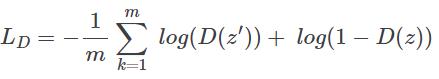
其中 m 是微批尺寸(minibatch size),z 由编码器生成,z' 是来自真实先验的样本。
对于对抗生成器,我们有
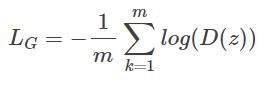
通过查看方程式和曲线,你应该明白,以这种方式定义的损失函数将强制判别器能够识别假样本,同时推动生成器欺骗判别器。
定义网络
在进入这个模型的训练过程之前,我们来看一下如何在 Pytorch 中实现我们现在所做的工作。对于编码器、解码器和判别器网络,我们将使用 3 个带有 ReLU 非线性函数与概率为 0.2 的 dropout 的 1000 隐藏状态层的简单前馈神经网络(feed forward neural network)。
在进入这个模型的训练过程之前,我们来看一下如何在 Pytorch 中实现我们现在所做的工作。对于编码器、解码器和判别器网络,我们将使用 3 个带有 ReLU 非线性函数与概率为 0.2 的 dropout 的 1000 隐藏状态层的简单前馈神经网络(feed forward neural network)。
#Encoderclass Q_net(nn.Module): def __init__(self): super(Q_net, self).__init__() self.lin1 = nn.Linear(X_dim, N) self.lin2 = nn.Linear(N, N) self.lin3gauss = nn.Linear(N, z_dim) def forward(self, x): x = F.droppout(self.lin1(x), p=0.25, training=self.training) x = F.relu(x) x = F.droppout(self.lin2(x), p=0.25, training=self.training) x = F.relu(x) xgauss = self.lin3gauss(x) return xgauss
# Decoderclass P_net(nn.Module): def __init__(self): super(P_net, self).__init__() self.lin1 = nn.Linear(z_dim, N) self.lin2 = nn.Linear(N, N) self.lin3 = nn.Linear(N, X_dim) def forward(self, x): x = self.lin1(x) x = F.dropout(x, p=0.25, training=self.training) x = F.relu(x) x = self.lin2(x) x = F.dropout(x, p=0.25, training=self.training) x = self.lin3(x) return F.sigmoid(x)
# Discriminatorclass D_net_gauss(nn.Module): def __init__(self): super(D_net_gauss, self).__init__() self.lin1 = nn.Linear(z_dim, N) self.lin2 = nn.Linear(N, N) self.lin3 = nn.Linear(N, 1) def forward(self, x): x = F.dropout(self.lin1(x), p=0.2, training=self.training) x = F.relu(x) x = F.dropout(self.lin2(x), p=0.2, training=self.training) x = F.relu(x) return F.sigmoid(self.lin3(x))
从这个定义可以注意到一些事情。首先,由于编码器的输出必须服从高斯分布,我们在最后一层不使用任何非线性定义。解码器的输出具有 S 形非线性,这是因为我们使用以其值在 0 和 1 范围内的标准化输入。判别器网络的输出仅为 0 和 1 之间的一个数字,表示来自真正先验分布的输入概率。
一旦网络的类(class)定义完成,我们创建每个类的实例并定义要使用的优化器。为了在编码器(这也是对抗网络的生成器)的优化过程中具有独立性,我们为网络的这一部分定义了两个优化器,如下所示:
torch.manual_seed(10) Q, P = Q_net() = Q_net(), P_net(0) # Encoder/Decoder D_gauss = D_net_gauss() # Discriminator adversarial if torch.cuda.is_available(): Q = Q.cuda() P = P.cuda() D_cat = D_gauss.cuda() D_gauss = D_net_gauss().cuda()# Set learning ratesgen_lr, reg_lr = 0.0006, 0.0008 # Set optimizatorsP_decoder = optim.Adam(P.parameters(), lr=gen_lr) Q_encoder = optim.Adam(Q.parameters(), lr=gen_lr) Q_generator = optim.Adam(Q.parameters(), lr=reg_lr) D_gauss_solver = optim.Adam(D_gauss.parameters(), lr=reg_lr)
训练步骤
每个微批处理的架构的训练步骤如下:
1)通过编码器/解码器部分进行前向路径(forward path)计算,计算重建损失并更新编码器 Q 和解码器 P 网络的参数。
z_sample = Q(X) X_sample = P(z_sample) recon_loss = F.binary_cross_entropy(X_sample + TINY, X.resize(train_batch_size, X_dim) + TINY) recon_loss.backward() P_decoder.step() Q_encoder.step()
2)创建潜在表征 z = Q(x),并从先验函数的 p(z) 取样本 z',通过判别器运行每个样本,并计算分配给每个 (D(z) 和 D(z')) 的分数。
Q.eval() z_real_gauss = Variable(torch.randn(train_batch_size, z_dim) * 5) # Sample from N(0,5) if torch.cuda.is_available(): z_real_gauss = z_real_gauss.cuda() z_fake_gauss = Q(X)
3)计算判别器的损失函数,并通过判别器网络反向传播更新其权重。在代码中,
# Compute discriminator outputs and loss D_real_gauss, D_fake_gauss = D_gauss(z_real_gauss), D_gauss(z_fake_gauss) D_loss_gauss = -torch.mean(torch.log(D_real_gauss + TINY) + torch.log(1 - D_fake_gauss + TINY)) D_loss.backward() # Backpropagate loss D_gauss_solver.step() # Apply optimization step
4)计算生成网络的损失函数并相应地更新 Q 网络。
# GeneratorQ.train() # Back to use dropout z_fake_gauss = Q(X) D_fake_gauss = D_gauss(z_fake_gauss)G_loss = -torch.mean(torch.log(D_fake_gauss + TINY)) G_loss.backward() Q_generator.step()
生成图像
现在我们尝试可视化 AAE 是如何将图像编码成具有标准偏差为 5 的 2 维高斯潜在表征的。为此,我们首先用 2 维隐藏状态训练模型。然后,我们在(-10,-10)(左上角)到(10,10)(右下角)的潜在空间上产生均匀点,并将其在解码器网络上运行。
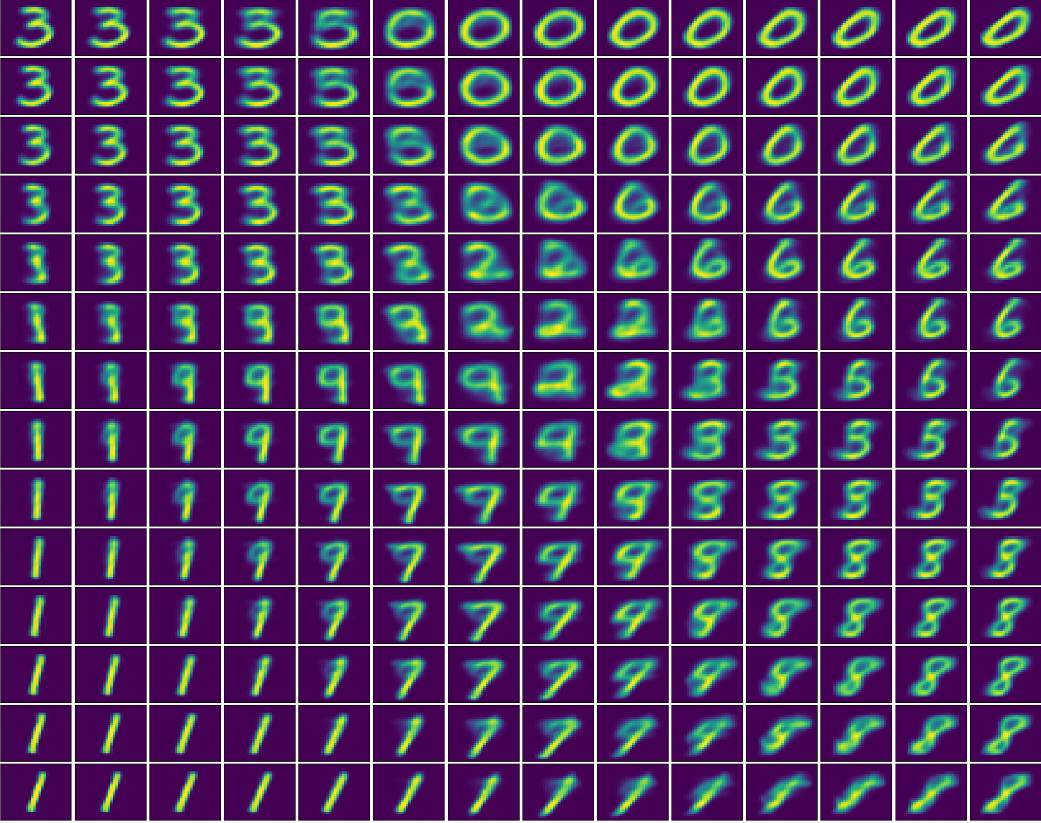
潜在空间。同时在 x 和 y 轴上从 -10 到 10 均匀地探索 2 维潜在空间时的图像重建。
AAE 学习消纠缠表征(disentangled representation)
数据的理想的中间表征将能够捕获产生观测数据变异的潜在因素。Yoshua Bengio 及其同事在一篇论文中(http://www.cl.uni-heidelberg.de/courses/ws14/deepl/BengioETAL12.pdf)中注明:「我们希望我们的表征能够消纠缠(解释)变异因素。在输入分布中,不同的数据解释因素倾向于彼此独立地变化」。他们还提到「最鲁棒的特征学习方法是尽可能多地解释因素,尽可能少地丢弃关于数据的信息」。
在 MNIST(http://yann.lecun.com/exdb/mnist/)数据(这是关于手写数字的大数据集)下,我们可以定义两个潜在的因果性因素,一方面是生成的数字,另一方面是书写的风格或方式。
监督式方法
在这部分中,我们比以前的架构进一步,并尝试在潜在代码 z 中强加某些结构。特别地,我们希望架构能够在完全监督的场景中将类别信息与字迹风格分开。为此,我们将以前的架构扩展到下图中。我们将潜在维度分为两部分:第一个 z 类似于上一个例子;隐藏代码的第二部分现在是一个独热向量(one-hot vector)y 表示馈送到自编码器的数字的身份。
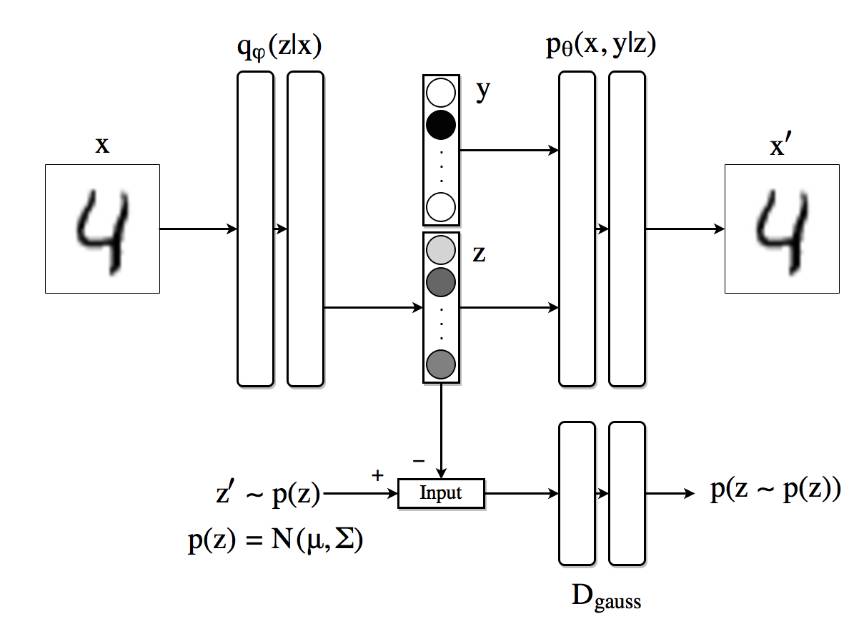
监督式对抗自编码器架构。
在该设置中,解码器使用独热向量 y 和隐藏代码 z 来重建原始图像。编码器的任务是编写 z 中的风格信息。在下面的图片中,我们可以看到用 10000 个标签的 MNIST 样本来训练这个架构的结果。该图显示了重建图像,其中对于每行,隐藏代码 z 被固定为特定值,类别标签 y 的范围从 0 到 9。字迹风格在列的维度上有效地保存了下来。

通过探索潜在代码 y 并保持 z 从左到右固定重建图像。
半监督式方法
作为我们最后一个实验,我们找到一种替代方法来获得类似的消纠缠结果,在这种情况下,我们只有很少的标签信息样本。我们可以修改之前的架构,使得 AAE 产生一个潜在的代码,它由表示类别或标签(使用 Softmax)的向量 y 和连续的潜在变量 z(使用线性层)连接组成。由于我们希望向量 y 表现为一个独热向量,我们通过使用第二个带有判别器 Dcat 的对抗网络迫使其遵从分类分布。编码器现在是 q(z,y|x)。解码器使用类别标签和连续隐藏代码重建图像。
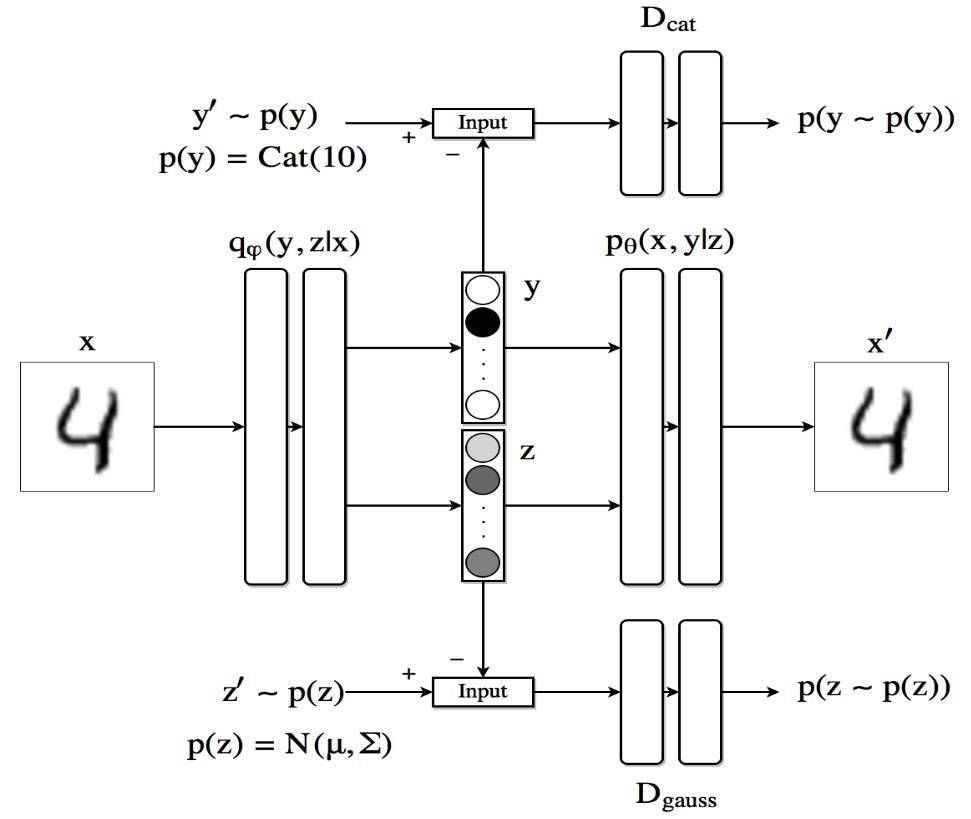
半监督式对抗自编码器架构。
基于重建损失函数创建隐藏代码和改进无需标签信息的生成器和判别器网络,未标记的数据通过这种方式改进编码器以促进训练过程。

用半监督式方法得到消纠缠结果。
值得注意的是,现在不仅可以通过较少标签信息生成图像,还可以通过查看潜在代码 y 并选择具有最高价值的图像来分类我们没有标签的图像。通过目前的设置,使用 100 个标签样本和 47000 个未标记的样本,分类误差约为 3%。
关于 GPU 训练
最后,我们将在 Paperspace 平台上为两个不同 GPU 和 CPU 中的最后一个算法做一个训练时间方面的简短比较。即使这种架构不是很复杂,而且由很少的线性层组成,但是在使用 GPU 加速时,训练时间的改善是巨大的。经过 500 epoch 的训练时间,从 CPU 的近 4 小时降至使用 Nvidia Quadro M4000 的 9 分钟,使用 Nvidia Quadro P5000 进一步下降到 6 分钟。
有无 GPU 加速的训练时间对比
更多资料
What is a variational autoencoder (https://jaan.io/what-is-variational-autoencoder-vae-tutorial) (Tutorial)
Auto-encoding Variational Bayes (https://arxiv.org/abs/1312.6114) (original paper)
Adversarial Autoencoders (https://arxiv.org/abs/1511.05644) (original paper)
Building Machines that Imagine and Reason: Principles and Applications of Deep Generative Models (http://videolectures.net/deeplearning2016_mohamed_generative_models/) (Video Lecture)
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
以上是关于教程 | 通过PyTorch实现对抗自编码器的主要内容,如果未能解决你的问题,请参考以下文章