自编码器,变分自编码器和生成对抗网络异同
Posted Patrick---
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自编码器,变分自编码器和生成对抗网络异同相关的知识,希望对你有一定的参考价值。
一、 AE(AutoEncoder)
1.1 自编码器简单模型介绍
自编码器可以理解为一个试图去 还原其原始输入的系统。
自动编码模型主要由编码器和解码器组成,其主要目的是将输入x转换成中间变量y,然后再将中间变量y转换成x’,然后对比输入和输出,使得他们两个无限接近。
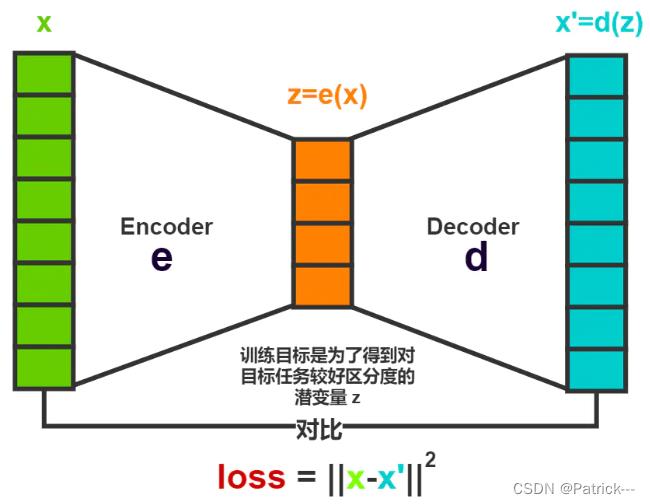
1.2 神经网络自编码器模型
在深度学习中,自动编码器是一种 无监督 的 神经网络 模型,它可以学习到输入数据的隐含特征,这称为编码(coding),同时用学习到的新特征可以重构出原始输入数据,称之为解码(decoding)。
从直观上来看,自动编码器可以用于 特征降维 ,类似主成分分析 PCA ,但是相比 PCA 其性能更强,这是由于神经网络模型可以提取更有效的新特征。除了进行特征降维,自动编码器学习到的新特征可以送入有监督学习模型中,所以自动编码器可以起到 特征提取器 的作用。举个例子,我有一张清晰图片,首先我通过编码器压缩这张图片的大小(如果展现出来可能比较模糊),然后在需要解码的时候将其还原成清晰的图片。
主要的功能是将输入信息进行特征方面的降维、提取等操作,进而通过计算真实值和预期值之间的差距不断迭代优化自编码器,达到编解码的目的。
那么此时可能会有人问了,好端端的图片为什么要压缩呢?其主要原因是:有时神经网络要接受大量的输入信息,比如输入信息是高清图片时,输入信息量可能达到上千万,让神经网络直接从上千万个信息源中学习是一件很吃力的工作。所以,何不压缩一下,提取出原图片中的最具代表性的信息 ,缩减输入信息量,再把缩减过后的信息放进神经网络学习。这样学习起来就简单轻松了。所以,自编码就能在这时发挥作用。通过将原数据 x 压缩,解压成 x~,然后通过对比 x 和 x~,求出预测误差,进行反向传递,逐步提升自编码的准确性。训练好的自编码中间这一部分就能总结出原数据的精髓。可以看出,从头到尾,我们只用到了输入数据 X,并没有用到 X 对应的数据标签,所以也可以说自编码是一种非监督学习。到了真正使用自编码的时候,通常只会用到自编码器的前半部分——编码器 (Encoder)。
1.3 神经网络自编码器三大特点
-
自动编码器是数据相关的(data-specific 或 data-dependent),这意味着自动编码器只能压缩那些与训练数据类似的数据。比如,使用人脸训练出来的自动编码器在压缩别的图片(比如树木)时,性能很差,因为它学习到的特征是与人脸相关的。
-
自动编码器是有损的,意思是解压缩的输出与原来的输入相比是退化的,MP3,JPEG等压缩算法也是如此。这与无损压缩算法不同。
-
自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。
1.4 自编码器搭建
搭建一个自动编码器需要完成下面三样工作:
-
搭建编码器;
-
搭建解码器;
-
设定一个损失函数,用以衡量由于压缩而损失掉的信息。
编码器和解码器一般都是参数化的方程,并关于损失函数可导,典型情况是使用神经网络。编码器和解码器的参数可以通过最小化损失函数而优化,例如SGD。
举个例子:根据上面介绍,自动编码器看作由两个级联网络组成:
-
第一个网络是一个编码器,负责接收输入 x,并将输入通过函数 h 变换为信号 y:y = h(x)
-
第二个网络将编码的信号 y 作为其输入,通过函数 f 得到重构的信号 r:r = f(y) = f(h(x))
-
定义误差 e 为原始输入 x 与重构信号 r 之差,e=x–r,网络训练的目标是减少均方误差(MSE),同 MLP 一样,误差被反向传播回隐藏层。
1.5 几种常见的自编码器
自编码器(autoencoder)是神经网络的一种,经过训练后能尝试将输入复制到输出。自编码器(autoencoder)内部有一个隐藏层 h,可以产生编码(code)表示输入。该网络可以看作由两部分组成:一个由函数 h = f(x) 表示的编码器和一个生成重构的解码器 r = g(h)。如果一个自编码器只是简单地学会将处处设置为 g(f(x)) = x,那么这个自编码器就没什么特别的用处。相反,我们 不应该 将自编码器设计成输入到输出完全相等。这通常需要向自编码器强加一些约束,使它只能 近似地 复制,并只能复制与训练数据相似的输入。这些约束强制模型考虑输入数据的哪些部分需要被优先复制,因此它往往能学习到数据的有用特性。
二、VAE(Variational AutoEncoder)
参考解析VAE
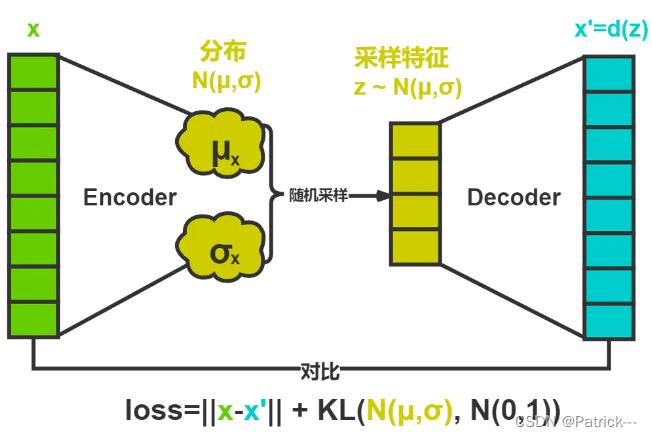
VAE将经过神经网络编码后的隐藏层假设为一个标准的高斯分布,然后再从这个分布中采样一个特征,再用这个特征进行解码,期望得到与原始输入相同的结果,损失和AE几乎一样,只是增加编码推断分布与标准高斯分布的KL散度的正则项,显然增加这个正则项的目的就是防止模型退化成普通的AE,因为网络训练时为了尽量减小重构误差,必然使得方差逐渐被降到0,这样便不再会有随机采样噪声,也就变成了普通的AE。
VAE将经过神经网络编码后的隐藏层假设为一个标准的高斯分布,然后再从这个分布中采样一个特征,再用这个特征进行解码,期望得到与原始输入相同的结果,损失和AE几乎一样,只是增加编码推断分布与标准高斯分布的KL散度的正则项,显然增加这个正则项的目的就是防止模型退化成普通的AE,因为网络训练时为了尽量减小重构误差,必然使得方差逐渐被降到0,这样便不再会有随机采样噪声,也就变成了普通的AE。
没错,我们先抛开变分,它就是这么简单的一个假设… 仔细想一下,就会觉得妙不可言。
它妙就妙在它为每个输入, 生成了一个潜在概率分布 ,然后再从分布中进行随机采样,从而得到了连续完整的潜在空间,解决了AE中无法用于生成的问题。
《论语》有言:“举一隅,不以三隅反,则不复也。” ,给我的启发就是看事物应该不能只看表面,而应该了解其本质规律,从而可以灵活迁移到很多类似场景。聪明人学习当举一反三,那么聪明的神经网络,自然也不能只会怼训练数据。如果我们把原始输入 看作是一个表面特征,而其潜在特征便是表面经过抽象之后的类特征,它将比表面特征更具备区分事物的能力,而VAE直接基于拟合了基于已知的潜在概率分布,可以说是进一步的掌握了事物的本质。
就拿一个人的某个行为来说,我们不能单纯看行为本身,因为这个行为往往代表了他的综合特性,他从出生开始,因为遗传,后天教育和环境,决定了他在面对某种情形的情况下,高概率会产生这个行为,也就是说掌握了概率分布,就掌控了一切。
三、GAN(Generative Adversarial Network)
生成对抗网络(Generative Adversarial Networks)是非监督式学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。该方法由伊恩·古德费洛等人于2014年提出。生成对抗网络由一个生成网络与一个判别网络组成。生成网络从潜在空间(latent space)中随机取样作为输入,其输出结果需要尽量模仿训练集中的真实样本。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。而生成网络则要尽可能地欺骗判别网络。两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实。
虽然生成对抗网络原先是为了无监督学习提出的,它也被证明对半监督学习、完全监督学习、强化学习是有用的。”
生成模型是一种自下而上的模型,容易生成更深一层的模型,但是容易忽略掉生成节点之间的关系。
判别模型作为一种自上而下的模型,考虑到了模型总体的情况,即各部分之间的关系,但是生成负样本时并不简单,特别是模型很复杂时,生成的负样本在短时间内并不会改善。
GAN结合了生成模型和判别模型各自的特点,清晰易懂,结构合理,正是这样的特点为14年之后的GAN的广泛应用做了铺垫。
以上是关于自编码器,变分自编码器和生成对抗网络异同的主要内容,如果未能解决你的问题,请参考以下文章