干货使用Pytorch实现卷积神经网络
Posted 专知
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货使用Pytorch实现卷积神经网络相关的知识,希望对你有一定的参考价值。
【导读】图像识别是深度学习取得重要成功的领域,特别是卷积神经网络在图像识别和图像分类中取得了超过人类的好成绩。本文详细介绍了卷积神经网络(CNN)的基本结构,对卷积神经网络中的重要部分进行详细讲解,如卷积、非线性函数ReLU、Max-Pooling、全连接等。另外,本文通过对 CIFAR-10 的10类图像分类来加深读者对CNN的理解和Pytorch的使用,列举了如何使用Pytorch收集和加载数据集、设计神经网络、进行网络训练、调参和准确度量。总的来讲,这篇文章偏重概念理解和动手实现,相信对您的入门会有帮助。
作者 | Justin Gage
编译 | 专知
参与 | Yingying, Sanglei
使用Pytorch实现卷积神经网络
卷积神经网络在许多计算机视觉任务中取得了令人震惊的突破,几乎是是开发人员和数据科学家必备技能之一。
本教程将介绍卷积神经网络(CNN)的基本结构,解释它的工作原理,并使用pytorch实一步步实现一个简单的CNN网络。
什么是卷积神经网络?
CNN算是计算机视觉的一个子领域,它的应用对象是视觉内容——图像。人们经常将CNN称为一种算法,但它实际上是多种不同算法的一种组合。 CNN与普通神经网络的主要区别在于预处理。它有两个要点:
特征工程/预处理 - 将图像转化为可以更高效地解释的表示形式。
分类 - 训练模型将图像映射到给定的类
CNN中的预处理旨在将输入图像转换为一组神经网络能更方便理解的特征。它看起来很复杂,但只要你记住上述两个要点,就不会迷茫。
卷积
CNN的名字来源于Convolution(卷积),它是提取提取图像特征的第一步。卷积可以看成是对图像滤波。我们传递一个小滤波器,通常称为kernel,并输出滤波后的图像。
由于图像只是一串像素值,实际上这意味着我们的输入图像的一部分与滤波器相乘。可调节的参数有:
Kernel大小 - 滤波器的大小。
Kernel类型 - 滤波器的值。比如单位矩阵,边缘检测滤波器,锐化滤波器等。
stride:Kernel在输入图像上移动的速率。步幅2代表2个像素为单位移动Kernel。
padding- 我们可以在图像的外部添加0值,以确保内核正确地通过图像的边缘。
输出层数 - 代表使用了多少个Kernel。
卷积的输出称为“卷积特征”或“特征图”。得到的特征可以看作是输入图像的优化表示。实践表明,卷积与后面的两个步骤(ReLU,池化)相结合可以大大提高图像分类的准确性。
在Pytorch中,卷积操作用torch.nn.Conv2d()函数实现。
ReLU
由于神经网络的前向传播本质上是一个线性函数(只是通过权重乘以输入并添加一个偏置项),CNN通常添加非线性函数来帮助神经网络理解底层数据。
在CNN中,最受欢迎的非线性函数式ReLU。ReLU表示整流线性单位,它只是将所有负值变成0.即output = Max(0,input)。
还有其他函数可以用来添加非线性,如tanh或softmax。但在CNN中,ReLU是最常用的。
在Pytorch中,ReLU操作用torch.nn.relu()函数实现。
Max-Pooling
使用CNN提取特征的最后一步是pooling,名如其实:我们将一个区域里面的最大值作为该区域的代表。这可以减少传入神经网络的特征。我们可以将它形象地表示为:
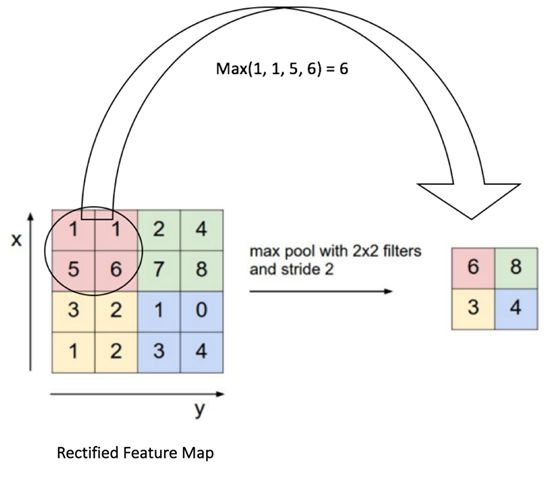
Max-Pooling也有一些可调整的参数,如步长和填充。还有别的池化方式,如sum-pooling和average-pooling。
在Pytorch中,Macpooling操作用 torch.nn.MaxPool2d() 函数实现.
全连接层
在上述预处理步骤之后,得到的特征(可能和一开始的完全不一样)被传递到传统的神经网络中。在这类我们使用包含一个隐藏层和一个输出层的两层神经网络。
这部分和其他网络相同,不是我们讨论的重点。CNNs的关键之处是提取特征。好的特征决定了模型达到的上限,而最终的分类器只决定我们有多接近这个上限。卷积,ReLU和maxpooling从图像中提取了有效的特征。
在Pytorch中,全连接操作用torch.nn.Linear()函数实现。
Pytorch入门
Pytorch是用于设计深度神经网络的以Python框架之一,和TensorFlow和Keras等流行的框架类似。
在为你的项目选择合适的框架时,需要考虑以下几点:
是否易于部署
是否容易理解
可不可以可视化
调试灵活性
可以肯定地说,Pytorch和其他框架相比更容易理解,并且它在数据科学领域很火。
收集和加载数据
大多数机器学习项目,不少代码是用来收集、清洗、准备数据大部分都用于收集。用Pytorch实现CNN也是一样。
Pytorch附带torchvision软件包,可以轻松下载和使用数据集。在这里,我们将使用CIFAR-10数据集。 CIFAR-10包含10个不同类别的图像。
首先导入必要的包,如Pytorch和用于数值计算的numpy。
import numpy asnp
importtorch
importtorchvision
importtorchvision.transforms as transforms
我们还需要设置一个标准的随机种子以获得可重现的结果。
seed =42
np.random.seed(seed)
torch.manual_seed(seed)
首先用Pytorch下载数据集。
#The compose function allows for multiple transforms
#transforms.ToTensor() converts our PILImage to a tensor of
shape (C x H x W) in the range [0,1]
#transforms.Normalize(mean,std) normalizes a tensor to
a (mean, std) for (R, G, B)
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = torchvision.datasets.CIFAR10(root='./cifardata',
train=True, download=True, transform=transform)
test_set = torchvision.datasets.CIFAR10(root='./cifardata',
train=False, download=True, transform=transform)
然后,指定标签:
classes = ('plane', 'car','bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
最后,定义采样器。在训练模型时,它们会将训练样例分解为训练,测试和交叉验证集。
from torch.utils.data.sampler import SubsetRandomSampler
#Training
n_training_samples =20000
train_sampler =SubsetRandomSampler(np.arange(n_training_samples,
dtype=np.int64))
#Validation
n_val_samples =5000
val_sampler =SubsetRandomSampler(np.arange(n_training_samples,
n_training_samples +n_val_samples, dtype=np.int64))
#Test
n_test_samples =5000
test_sampler =SubsetRandomSampler(np.arange(n_test_samples,
dtype=np.int64))
用Pytorch设计神经网络
用Pytorch实现上述步骤很容易,在CNN中使用4个主要函数:
torch.nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding)- 卷积
torch.nn.relu(x) - ReLU torch.nn.
MaxPool2d(kernel_size,stride,padding) - Max Pooling
torch.nn.Linear(in_features,out_features) - 全连接(学习权值乘以输入)
我们将创建继承torch.nn.Module类的SimpleCNN类。
from torch.autograd import Variable
importtorch.nn.functional as F
classSimpleCNN(torch.nn.Module):
#Our batch shape for input x is (3, 32, 32)
def__init__(self):
super(SimpleCNN,self).__init__()
#Input channels = 3, output channels = 18
self.conv1=torch.nn.Conv2d(3, 18, kernel_size=3, stride=1,
padding=1)
self.pool=torch.nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
#4608 input features, 64 output features (seesizing flow below)
self.fc1=torch.nn.Linear(18*16*16, 64)
#64 input features, 10 output features for our10 defined classes
self.fc2=torch.nn.Linear(64, 10)
defforward(self, x):
#Computes the activation of the firstconvolution
#Size changes from (3, 32, 32) to (18, 32, 32)
x=F.relu(self.conv1(x))
#Size changes from (18, 32, 32) to (18, 16, 16)
x=self.pool(x)
#Reshape data to input to the input layer ofthe neural net
#Size changes from (18, 16, 16) to (1, 4608)
#Recall that the -1 infers this dimension fromthe other
given dimension
x=x.view(-1, 18*16*16)
#Computes the activation of the first fullyconnected layer
#Size changes from (1, 4608) to (1, 64)
x=F.relu(self.fc1(x))
#Computes the second fully connected layer(activation
applied later)
#Size changes from (1, 64) to (1, 10)
x=self.fc2(x)
return(x)
让我来解释一下这段代码。我们在SimpleCNN类中定义了一个函数:forward。 forward() 函数CNN的前向传播,包括我们上面提到的预处理步骤。
手动定义神经网络的麻烦之处在于,我们需要为每一层指定输入和输出的大小。一般来说,输入集合中任何维度的输出大小都可以定义为:
def outputSize(in_size, kernel_size, stride,padding):
output =int((in_size - kernel_size +2*(padding))/stride) +1
return(output)
比如,在max pooling层中,输入维度为(18,32,32) - 将公式应用于最后的两个维度(第一维度或特征映射的数量在池化操作期间保持不变),我们得到的输出大小为(18,16,16)。
用Pytorch训练神经网络
在为CNN定义了类别之后,就可以开始训练网络。这是神经网络变得有趣的地方。如果您正在使用更多基本机器学习算法,则通常只需几行代码即可获得有意义的输出结果。例如,在sklearn Python包中实现支持向量机就如下一样简单:
#Import the support vectormachine module from the sklearn framework
fromsklearn import svm
#Label x and y variables from our dataset
x = ourData.features
y = ourData.labels
#Initialize our algorithm
classifier =svm.SVC()
#Fit model to our data
classifier.fit(x,y)
然而,使用Pytorch(和TensorFlow)实现神经网络,需要更多代码。基本流程是一个训练循环:每次我们通过循环(被称为“epoch”)时,我们计算网络上的前向传播并实施反向传播来调整权重。我们还会记录一些其他测量值,比如损失和时间,来分析网络的优劣。
首先,使用上面创建的采样器来定义我们的数据加载器。
#DataLoader takes in adataset and a sampler for loading
(num_workers deals with system level memory)
defget_train_loader(batch_size):
train_loader = torch.utils.data.DataLoader(train_set,
batch_size=batch_size, sampler=train_sampler, num_workers=2)
return(train_loader)
#Test and validation loadershave constant batch sizes,
so we can define them directly
test_loader =torch.utils.data.DataLoader(test_set,
batch_size=4, sampler=test_sampler, num_workers=2)
val_loader =torch.utils.data.DataLoader(train_set,
batch_size=128, sampler=val_sampler, num_workers=2)
我们还将定义我们的损失函数和优化器,CNN将使用它来调整权重。 我们将使用交叉熵损失(对数损失)作为损失函数,它会强烈惩罚错误的答案。 优化器选择流行的Adam算法。
import torch.optim as optim
defcreateLossAndOptimizer(net, learning_rate=0.001):
#Loss function
loss =torch.nn.CrossEntropyLoss()
#Optimizer
optimizer = optim.Adam(net.parameters(), lr=learning_rate)
return(loss,optimizer)
最后,我们将定义一个函数来使用简单的for循环来训练我们的CNN。
import time
deftrainNet(net, batch_size, n_epochs, learning_rate):
#Print all of the hyperparameters of thetraining iteration:
print("===== HYPERPARAMETERS =====")
print("batch_size=",batch_size)
print("epochs=",n_epochs)
print("learning_rate=",learning_rate)
print("="*30)
#Get training data
train_loader = get_train_loader(batch_size)
n_batches =len(train_loader)
#Create our loss and optimizer functions
loss,optimizer = createLossAndOptimizer(net, learning_rate)
#Time for printing
training_start_time = time.time()
#Loop for n_epochs
forepoch inrange(n_epochs):
running_loss =0.0
print_every = n_batches //10
start_time = time.time()
total_train_loss =0
fori, data inenumerate(train_loader, 0):
#Get inputs
inputs, labels = data
#Wrap them in a Variableobject
inputs, labels = Variable(inputs), Variable(labels)
#Set the parameter gradientsto zero
optimizer.zero_grad()
#Forward pass, backward pass,optimize
outputs = net(inputs)
loss_size = loss(outputs, labels)
loss_size.backward()
optimizer.step()
#Print statistics
running_loss += loss_size.data[0]
total_train_loss += loss_size.data[0]
#Print every 10th batch of anepoch
if (i +1) % (print_every +1) ==0:
print("Epoch {},{:d}% \t train_loss: {:.2f} took:
{:.2f}s".format(epoch+1, int(100* (i+1) /n_batches),
running_loss / print_every, time.time() - start_time))
#Reset running loss and time
running_loss =0.0
start_time = time.time()
#Atthe end of the epoch, do a pass on the validation set
total_val_loss =0
forinputs, labels in val_loader:
#Wrap tensors in Variables
inputs, labels = Variable(inputs), Variable(labels)
#Forward pass
val_outputs = net(inputs)
val_loss_size = loss(val_outputs, labels)
total_val_loss += val_loss_size.data[0]
print("Validation loss = {:.2f}".
format(total_val_loss/len(val_loader)))
print("Training finished, took {:.2f}s".
format(time.time() - training_start_time))
在每个训练阶段,我们将数据以预先定义的批量传递给模型。训练时,使用刚定义的SimpleCNN提取特征,并在几轮之后打印模型在验证集上的评估结果。
真正训练模型的代码其实只有如下两行:
CNN = SimpleCNN()
trainNet(CNN, batch_size=32, n_epochs=5, learning_rate=0.001)
就是这样!你成功地用Pytorch实现了CNN。
更进一步
准确度量
我们的训练循环打印出CNN的两个准确度量度:训练损失(每10轮打印一次)和验证集误差(每轮打印一次)。当定义CNN损失和优化函数时,我们使用了torch.nn.CrossEntropyLoss()函数。
交叉熵损失(也称为对数损失)输出介于0和1之间的概率值,随着预测标签与实际标签的分离概率的增加而增加。
对于机器学习,会使用精度,召回率和混淆矩阵等其他准确度度量。每个项目都有不同的目标,因此应该针对这些目标量身定制度量标准。
网络架构
在CIFAR-10数据集中,训练数据集上得到约60%的准确度。这比随机猜测要好得多,但它离现有最好的结果还很遥远。
我们的模型与精度达到80%以上的模型之间的主要差异之一是层数。我们的网络有一个卷积层,一个池层和一个全连接层,一个输出层。而VGG-16架构利用16个以上的层次,并在ImageNet 2014挑战赛中获得高分。
为了在我们的CNN中添加更多的层数,我们可以在初始化SimpleCNN类实例的过程中创建新的方法(尽管此时我们可能想要将类名更改为LessSimpleCNN)。
例如,我们可以尝试:
self.conv2= torch.nn.Conv2d(3,18,kernel_size = 3,stride = 1,
padding = 1)
self.pool2 = torch.nn.MaxPool2d(kernel_size = 2,stride = 2,
padding = 0)
调整超参数
除了改变我们使用的输入和激活函数之外,卷积和maxpooling还有更多可以调整的超参数。如kernel_size,stride和padding可以提取更多的信息特征,并得到更高的准确性(如果不是过拟合)。
原文链接:
https://blog.algorithmia.com/convolutional-neural-nets-in-pytorch/
更多教程资料请访问:
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知
以上是关于干货使用Pytorch实现卷积神经网络的主要内容,如果未能解决你的问题,请参考以下文章
基于pytorch使用实现CNN 如何使用pytorch构建CNN卷积神经网络
基于pytorch使用实现CNN 如何使用pytorch构建CNN卷积神经网络
[Pytorch系列-50]:卷积神经网络 - FineTuning的统一处理流程与软件架构 - Pytorch代码实现