基于pytorch使用实现CNN 如何使用pytorch构建CNN卷积神经网络
Posted _刘文凯_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于pytorch使用实现CNN 如何使用pytorch构建CNN卷积神经网络相关的知识,希望对你有一定的参考价值。
基于pytorch使用实现CNN 如何使用pytorch构建CNN卷积神经网络
本文是一个基于pytorch使用CNN在生物信息学上进行位点预测的例子
基于pytorch实现CNN,基于CNN进行位点预测,将CNN代码进行封装,可以非常简单的使用代码,基于最简单的特征提取方法。
所用工具
使用了python和pytorch进行实现
python3.6
toch1.10
目录结构:
如下图所示:
数据:
百度网盘地址(数据很小):
链接:https://pan.baidu.com/s/1uvYs7EBJiK3U89v7vMX9yw
提取码:nii4
代码:
以下代码直接复制可以运行
import torch # 需要的各种包
import torch.nn as nn
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import StratifiedKFold
from torch.autograd import Variable
import torch.utils.data as Data
import torch.utils.data as data
import torchvision # 数据库模块
import pandas as pd
import numpy as np
torch.manual_seed(1) # reproducible 将随机数生成器的种子设置为固定值,这样,当调用时torch.rand(x),结果将可重现
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
class CNN(nn.Module):
def __init__(self, seq_len):
super(CNN, self).__init__() # 固定写法
self.conv1 = nn.Sequential( # 假设输入为(1,21)
nn.Conv1d(in_channels=1, # input height 必须手动提供 输入张量的channels数
out_channels=16, # n_filter 必须手动提供 输出张量的channels数
kernel_size=3, # filter size 必须手动提供 卷积核的大小
stride=1, # filter step 卷积核在图像窗口上每次平移的间隔,即所谓的步长
padding=1 # 填补为2
), # output shape (16,21)
nn.ReLU(), # 分段线性函数,把所有的负值都变为0,而正值不变,即单侧抑制
nn.MaxPool1d(kernel_size=3, stride=1, padding=1), # 2采样,28/2=14,output shape (16,14,14) maxpooling有局部不变性而且可以提取显著特征的同时降低模型的参数,从而降低模型的过拟合
nn.Dropout(p=0.2)
)
self.conv2 = nn.Sequential(nn.Conv1d(16, 32, 3, 1, 1),
nn.ReLU(), # 分段线性函数,把所有的负值都变为0,而正值不变,即单侧抑制
nn.MaxPool1d(kernel_size=3, stride=1, padding=1),
# 2采样,28/2=14,output shape (16,14,14) maxpooling有局部不变性而且可以提取显著特征的同时降低模型的参数,从而降低模型的过拟合
nn.Dropout(p=0.2)
) # 输出为 max_len/
self.out = nn.Linear(seq_len*32, 2) # 全连接层,输出为2个one_hot编码
def forward(self, x):
x = self.conv1(x) # 卷一次
x = self.conv2(x) # 卷两次
x = x.view(x.size(0), -1) # 展平, 将前面多维度的tensor展平成一维 x.size(0)指batchsize的值
output = self.out(x) # fc out全连接层 分类器
return output
class Use_torch_CNN():
def __init__(self, epoch, batch_size, lr):
self.epoch = epoch
self.batch_size =batch_size
self.lr = lr
def to_torch(self, X_train, y_train): # 转化为torch数据
BATCH_SIZE = self.batch_size
X_train = torch.FloatTensor(X_train)
y_train = torch.FloatTensor(y_train)
train_loader = Data.DataLoader(Data.TensorDataset(X_train, y_train), BATCH_SIZE,
shuffle=False) # 自动划分Batch_size
return train_loader
def train(self, X_train, y_train):
seq_len = X_train.shape[-1]
train_loader = self.to_torch(X_train, y_train)
####### 以下为数据训练 ##########
self.cnn = CNN(seq_len=seq_len) # 创建网络
print(self.cnn) # 查看网络结构
optimizer = torch.optim.Adam(self.cnn.parameters(), lr=self.lr) # optimizer 优化器
loss_func = nn.CrossEntropyLoss() # 损失函数 交叉熵
for epoch in range(self.epoch):
for step, (x, y) in enumerate(train_loader):
batch_x = Variable(x)
batch_x = torch.unsqueeze(batch_x, dim=1)
batch_y = Variable(y)
optimizer.zero_grad() # 梯度归零 必须项
output = self.cnn(batch_x) # 输入训练数据
loss = loss_func(output, batch_y) # 计算误差 # 实际输出, 期望输出
loss.backward() # 误差反向传递 只需要调用.backward()即可
optimizer.step()
print(f"epoch:epoch loss:loss")
def predict_proba(self, X_valid):
val_data_x = torch.FloatTensor(X_valid)
val_data_x = torch.unsqueeze(val_data_x, dim=1)
test_output = self.cnn(val_data_x)
y_scores = test_output.detach().numpy()
return y_scores
def predict(self, X_valid):
y_scores = self.predict_proba(X_valid)
return np.argmax(y_scores, axis=1)
def ex_feature(data_pos, data_neg): ## 提取特征
def split_word(data_init, k=1): ## 分词处理 一般为1分词
data = data_init.tolist()
split_dict = '[PAD]': 0, '[CLS]': 1, '[SEP]': 2, '[MASK]': 3, 'B': 4,
'Q': 5, 'I': 6, 'D': 7, 'M': 8, 'V': 9, 'G': 10, 'K': 11,
'Y': 12, 'P': 13, 'H': 14, 'Z': 15, 'W': 16, 'U': 17, 'A': 18,
'N': 19, 'F': 20, 'R': 21, 'S': 22, 'C': 23, 'E': 24, 'L': 25,
'T': 26, 'X': 27, 'O': 28
def str_sum(s, i):
d = ''
for j in range(k):
d += s[i + j]
return d
for i, seq in enumerate(data):
data[i] = seq[0]
token_list = list()
max_len = 0 ## 最大长度
for seq in data:
seq_id = [split_dict[str_sum(seq, i)] for i in range(len(seq) - k + 1) if i % k == 0] # 字符转为数字
token_list.append(seq_id)
if len(seq_id) > max_len:
max_len = len(seq_id) ## 获取最大长度
return token_list, max_len
def add_CLS_SEP(token_list, max_len): # 增加标志 以及 补零
split_dict = '[PAD]': 0, '[CLS]': 1, '[SEP]': 2, '[MASK]': 3, 'B': 4,
'Q': 5, 'I': 6, 'D': 7, 'M': 8, 'V': 9, 'G': 10, 'K': 11,
'Y': 12, 'P': 13, 'H': 14, 'Z': 15, 'W': 16, 'U': 17, 'A': 18,
'N': 19, 'F': 20, 'R': 21, 'S': 22, 'C': 23, 'E': 24, 'L': 25,
'T': 26, 'X': 27, 'O': 28
data = []
for i in range(len(token_list)): # 由于长度不一致,不建议用numpy操作
token_list[i] = [split_dict['[CLS]']] + token_list[i] + [split_dict['[SEP]']]
n_pad = max_len - len(token_list[i])
token_list[i].extend([0] * n_pad) # 补零对齐
data.append(token_list[i])
return data
data_pos, max_len_pos = split_word(data_pos)
data_neg, max_len_neg = split_word(data_neg)
max_len = np.max([max_len_pos, max_len_neg])
data_pos = add_CLS_SEP(data_pos, max_len)
data_neg = add_CLS_SEP(data_neg, max_len)
return data_pos, data_neg
def generate_train_test(Px, Nx): # 分出X Y
Px = np.array(Px)
Nx = np.array(Nx)
Py = np.ones((Px.shape[0], 1))
Ny = np.zeros((Nx.shape[0], 1))
P_train = np.concatenate((Px, Py), axis=1) # 按列合并
N_train = np.concatenate((Nx, Ny), axis=1) # 按列合并
data_train = np.concatenate((P_train, N_train), axis=0) # 按行合并
np.random.seed(42)
np.random.shuffle(data_train) # 混淆数据
X = data_train[:,:-1] # 除-1列外的所有列
Y = (data_train[:,-1]).reshape(-1,1)
return X, Y
def get_kfold_data(X, Y, k=5):
X = np.array(X)
Y = np.array(Y)
kfold = StratifiedKFold(n_splits=k, shuffle=True, random_state=520)
data_kfold_list = []
for train_idx, val_idx in kfold.split(X,y):
data_kfold_list.append('train':'X':X[train_idx],'Y':Y[train_idx],
'val':'X':X[val_idx],'Y':Y[val_idx])
return data_kfold_list
### 迭代器形式 省内存 ###
# for train_idx, val_idx in kfold.split(X,y):
# data_kfold_list = 'train':'X':X[train_idx],'Y':y[train_idx],
# 'val':'X':X[val_idx],'Y':y[val_idx]
# yield data_kfold_list
# return
def get_one_data(X, Y, k=5):
X = np.array(X)
Y = np.array(Y)
One_Hot = OneHotEncoder().fit(Y)
Y_one_hot = One_Hot.transform(Y).toarray()
kfold = StratifiedKFold(n_splits=k, shuffle=True, random_state=520)
for train_idx, val_idx in kfold.split(X,Y):
return X[train_idx], Y_one_hot[train_idx], X[val_idx], Y_one_hot[val_idx]
if __name__ == '__main__':
EPOCH = 10 # 训练迭代次数
BATCH_SIZE = 32 # 分块送入训练器
LR = 0.001 # 学习率 learning rate
######## 以下为数据加载 #######
data_pos = np.array(pd.read_csv('./data/gly_pos.fa', header=None))
data_neg = np.array(pd.read_csv('./data/gly_neg.fa', header=None))
data_pos, data_neg = ex_feature(data_pos, data_neg) # 提取特征
train_x, train_y = generate_train_test(data_pos, data_neg)
X_train, y_train, X_valid, y_valid = get_one_data(train_x, train_y)
cnn = Use_torch_CNN(epoch=EPOCH, batch_size=BATCH_SIZE, lr=LR) # 构建模型
cnn.train(X_train, y_train) # 训练模型
y_scores = cnn.predict_proba(X_valid) # 预测
auc = roc_auc_score(y_valid[:,1], y_scores[:,1]) # y_true, y_score
print(f'auc:auc')
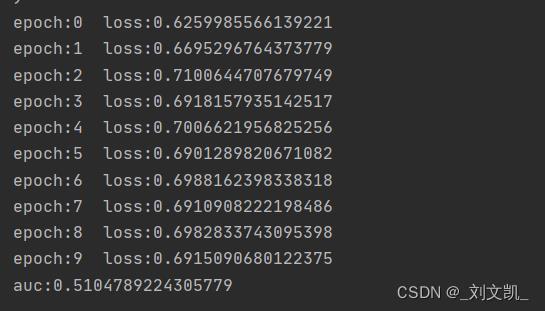
结果:
如下图所示,结果并不好,原因很简单,因为这个模型“提取特征”部分没做好:
改进思路
1、增加特征提取方式
2、利用自编码器提取特征
以上是关于基于pytorch使用实现CNN 如何使用pytorch构建CNN卷积神经网络的主要内容,如果未能解决你的问题,请参考以下文章