清晰易懂的朴素贝叶斯分类原理讲解
Posted 机器学习算法那些事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了清晰易懂的朴素贝叶斯分类原理讲解相关的知识,希望对你有一定的参考价值。
如何知道抛硬币的概率?高中数学是这样求解的——抛掷硬币几千次或者上万次,硬币正面向上的次数与硬币反面向上的次数接近一致,因此我们得到结论,硬币正面向上的概率与硬币反面向上的概率相等,即0.5。
这一结论是有理论根据,由大数定律可知,当随机事件发生的样本容量增加时,随机事件样本均值接近与总体均值,因此我们认为正面向上和反面向上的概率等于0.5。
那么如何预测本世纪两颗星球相撞的概率?根据抛硬币方法,我们通过两颗星球相撞几千次或几万次,然后根据大数定律得到两颗星球相撞的概率。
这种方法实际上是不可行的,因为星球相撞只能发生一次,因此传统的概率计算方法已经不适用了。
若我们分析两颗星球的轨迹,质量,以及周围星球的轨迹和质量,得出两颗星球在本世纪相撞的概率,这一思想即贝叶斯方法。
好了,相信大家对贝叶斯方法有了初步的理解,为了更好的理解贝叶斯分类原理,我们从贝叶斯理论开始介绍。
最能体现贝叶斯理论的公式:
P(A|B)是后验概率,即事件B发生的前提下,事件A发生的概率
P(B|A)是事件A发生的前提下,事件B发生的概率
P(A)是先验概率,即事件A发生的概率
P(B)是事件B发生的概率,P(B)不改变分类结果,是一个规范化因子,作用是获取后验概率的和等于1.
这就是本文要介绍的核心,贝叶斯定理是一个简单而有力的陈述,它提供了一个预测真实答案的过程,每次收集新数据时,我们都可以使用贝叶斯定理来完善我们的后验概率,说起来简单,但是初学者刚刚接触时很难理解它。
还是以星球相撞的事件来阐述贝叶斯理论:
我们根据现有的理论和星球的观测数据,得到了星球相撞的概率。若后面几十年,理论有了一定的突破,或有了新的观测数据,那么我们通过贝叶斯理论更新星球相撞的概率。是吧!贝叶斯理论预测事件发生的概率是一种过程,预测结果是根据当前的数据来预测的,若数据更新了,预测结果也相应的更新了。
现在我们理解了贝叶斯理论,我们开始介绍将这一定理应用到机器学习分类方法。
简单来说,朴素贝叶斯根据观测数据给出最佳的预测结果。假设观测数据为xₒ,分类结果是1或2,有:
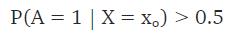
用朴素贝叶斯理论官话讲:观测数据xₒ,给出的事件A发生的概率大于0.5,因此分类结果为1。
具体一点,贝叶斯理论是如何工作的:
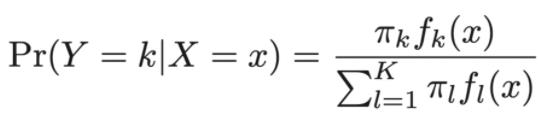
P(Y = k | X = x)是后验概率,变量Y的可能取值有K种结果,给定观测数据x,Y属于k类的结果。
πₖ是变量Y属于第k类的先验概率,顾名思义,这是我们事先定义的。
fₖ(x) 是似然函数,已知分类结果为k的前提下,观测数据为x的概率。
πₖ fₖ(x) 是贝叶斯理论的引擎,决定了后验概率分类结果。
Σ πₗ fₗ(x) 是规范化因子,确保后验概率的和等于1。
为了便于计算,朴素贝叶斯假设特征是条件独立的,即分类结果为k的前提下,特征变量间是相互独立的。
调用sklearn包的朴素贝叶斯类:
from sklearn.naive_bayes import GaussianNB
# fit the model
model = GaussianNB()
model.fit(X_train, y_train)
# make a prediction
y_pred = model.predict(X_test)
朴素贝叶斯分类是探索复杂类型的基础,如我们用得较多的马尔可夫理论,条件随机场等机器学习方法。本文以清晰易懂的白话形式,讲解了朴素贝叶斯理论及分类原理,正确理解该理论是学好机器学习的基础。
参考
https://towardsdatascience.com/the-naive-bayes-classifier-caaf5b01635e
以上是关于清晰易懂的朴素贝叶斯分类原理讲解的主要内容,如果未能解决你的问题,请参考以下文章