Kafka入门系列——Kafka环境安装
Posted 大数据Kafka技术分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka入门系列——Kafka环境安装相关的知识,希望对你有一定的参考价值。
Kafka环境安装
本文讲述如何安装Apache Kafka,包括安装Kafka的broker服务器和Apache zookeeper组件。Kafka使用zookeeper来保存broker的元数据信息。另外本文还会涉及到Kafka多节点集群的安装以及常规参数的设置。
准备工作
操作系统
Kafka是一个JVM系的框架。其服务器端的代码是由Scala语言编写的,新版客户端代码是Java语言编写的,所以它可以运行在很多操作系统下,比如Linux, Windows和OS X等。Apache Kafka官方推荐安装Kafka在Linux上。
Java
之前说过了,Kafka是JVM系的框架,所以需要安装Java。虽然目前还是支持Java7,不过还是推荐安装Java 8,因为Kafka和zookeeper都需要运行在Java环境中。截止到写本文时,Java 8的最新版本是jdk8u121 (http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)
安装Zookeeper
安装Zookeeper的第一步就是下载。当前的最新版本是: 3.4.9 (http://apache.org/dist/zookeeper/stable/zookeeper-3.4.9.tar.gz)下载之后解压并配置对应的配置文件:
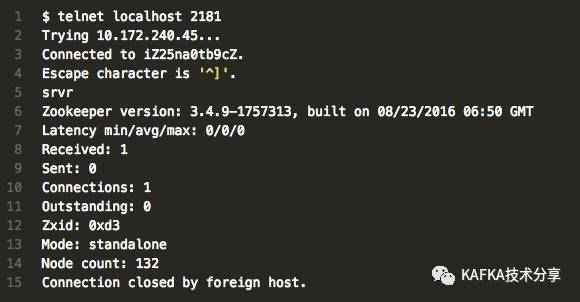
看到上面的STARTED即说明启动成功。当然,你可以使用telnet再去验证一下2181端口上的zk服务已经启动成功:
上面说的都是单机模式的配置。如果要启动多个zookeeper节点构成一个zookeeper集群,即配置集群模式。那么就需要保证所有节点上的配置文件都是相同的,然后在每个zookeeper节点的配置文件中dataDir所对应的目录下创建一个名为myid的文件。该文件的内容后面会提到。
假设我们搭建3台机器组成的zookeeper集群,且主机名分别为:zk1,zk2和zk3,那么3台zookeeper节点的配置文件内容为:
tickTime=2000
dataDir=/home/zookeeper
clientPort=2181
initLimit=20
syncLimit=5
server.1=zk1:2888:3888
server.2=zk2:2888:3888
server.3=zk3:2888:3888
简单提一句,上面server.x = [hostname]:nnnnn[:nnnnn]的配置项中,x就是组成zookeeper集群的节点编号,虽然不需要一定从0开始,但至少要是个整数。后面接2个端口号:第一个端口用于是给集群中的follower连接leader使用的,而第二个端口号是用于leader选举的。 其他的参数含义可以参考zookeeper的官方手册(https://zookeeper.apache.org/doc/r3.4.9/zookeeperAdmin.html#sc_configuration)。
还记得之前提到的myid文件吧? 每台机器上都应该在配置的dataDir下创建一个名为myid的文件,内容只有1行,就是该服务器是server.x中的x。比如第一台服务器就是1,第二台服务器就是2,以此类推。
配置好这些之后,运行zkServer.sh start命令就可以启动了。
安装Kafka
我们已经成功地安装了Java和Zookeeper, 下一步就是安装Apache Kafka了。笔者在写这篇文章时最新的Kafka版本是0.10.1.1,还是先下载吧: Kafka 0.10.1.1(https://www.apache.org/dyn/closer.cgi?path=/kafka/0.10.1.1/kafka_2.11-0.10.1.1.tgz) 值得注意的是,我选择了使用Scala2.11编译的版本,Scala2.12编译的版本目前还是测试预览版本。okay,下载完成后执行下面命令:

Kafka已经成功启动了并且能够成功地创建topic了。我们生产几条消息,看看稍后能否消费这些消息:
下面我们尝试去消费这些消息:
你可以看到可以看到这两条消息打印在你的控制台上。这就证明了Kafka已经被成功启动并且可以正常地工作。
同样地,这是Kafka的单机模式。如果要搭建多节点集群,那么我们需要简单地了解一下Kafka的配置文件,然后使用它搭建集群环境。
Kafka的配置文件位于config目录下,名字叫server.properties。在这个配置文件中,最关键的三个参数是:
broker.id
logs.dirs
zookeeper.connect
这三个参数是必须要配置的。假设我们现在要搭建由3台机器组成的Kafka集群,那么每台机器上的这三个配置文件分别为:
broker.id=0
logs.dirs=/home/kafka/data
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
broker.id=1
logs.dirs=/home/kafka/data
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
broker.id=2
logs.dirs=/home/kafka/data
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
你可以看到broker.id配置成了不同的数字,通常broker的序号从0开始,我们也建议你配置成这样。做完这些之后,在每台机器上分别运行之前的启动命令,一个3节点Kafka集群就安装完毕了。当然Kafka提供了超多的参数用于控制各种行为,有兴趣的话可以自己去官方的配置列表(https://kafka.apache.org/documentation/#brokerconfigs)中学习每个参数的具体用法。
以上是关于Kafka入门系列——Kafka环境安装的主要内容,如果未能解决你的问题,请参考以下文章