Kafka从入门到成神系列 五Kafka 幂等性及事务
Posted 爱敲代码的小黄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka从入门到成神系列 五Kafka 幂等性及事务相关的知识,希望对你有一定的参考价值。
- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,Java领域新星创作者。
- 📝个人公众号:爱敲代码的小黄(回复 “技术书籍” 可获千本电子书籍)
- 📕系列专栏:Java设计模式、数据结构和算法、Kafka从入门到成神
- 📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2022计划中:以梦为马,扬帆起航,2022追梦人
文章目录
一、幂等性和事务
我们上一篇讲到,消息丢失的时候,我们采用:先读取消息,再更新位移的操作,避免了消息丢失,但同时产生了一个新的问题:消息重复。
我们 Kafka 对我们的 Producer 和 Consumer 提供三种承诺:
- 最多一次:消息可能会丢失,但不会重复
- 至少一次:消息不会丢失,但不会重复
- 精确一次:消息不会丢失,也不会重复
目前,Kafka 提供的可靠性保障是第二种,既至少一次。当 Producer 发送消息到 Broker 端,可能由于网络抖动的原因,导致 Producer 无法确定消息是否真的发送成功,会进行重新发送的操作。不过,有可能会导致消息重复。
Kafka 也可以提供最大一次性保证,只需要让 Producer 禁止重试即可。
当然,最好的承诺还是第三种:精确一次,利用两种机制:幂等性和事务
1. 幂等性
“幂等” 这个词是数学领域的概念,指的是某个函数被执行多次,但每次得到的结果都是不变的。
简单来说,让数字乘以 1 就是一个幂等操作,因为你不论操作几次,最终的结果都是该数字,也就是最终的结果不会变化。
幂等有很多好处,其最大的优势在于我们可以安全的重试任何幂等性操作,反正他们不会破坏我们的系统状态。
在 Kafka 的 0.11 版本中引入了幂等性的功能。在此版本之前,Kafka 向分区发送消息,可能会出现同一条消息被发送了多次,导致消息重复的情况。在 0.11 版本后,指定 Producer 幂等性的方法很简单,仅需要设置:props.put(“enable.idempotence”, ture) 或 props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true)。
当我们开启幂等性后,Kafka 自动帮我们做消息的重复去重。底层的原理,使用空间去换时间的优化思路,既在我门的 Broker 端多保存一些字段。
我们引进了 ProducerID 和 SequenceNumber 两个字段。
ProducerID:每个 Producer 初始化时,会分配一个唯一的 ProducerIDSequenceNumber:对于每个 ProducerID,Producer发送数据的每个 Topic 和 Partition 都对应一个从 0 开始单调递增的SequenceNumber值。
我们出现消息重复的情况:
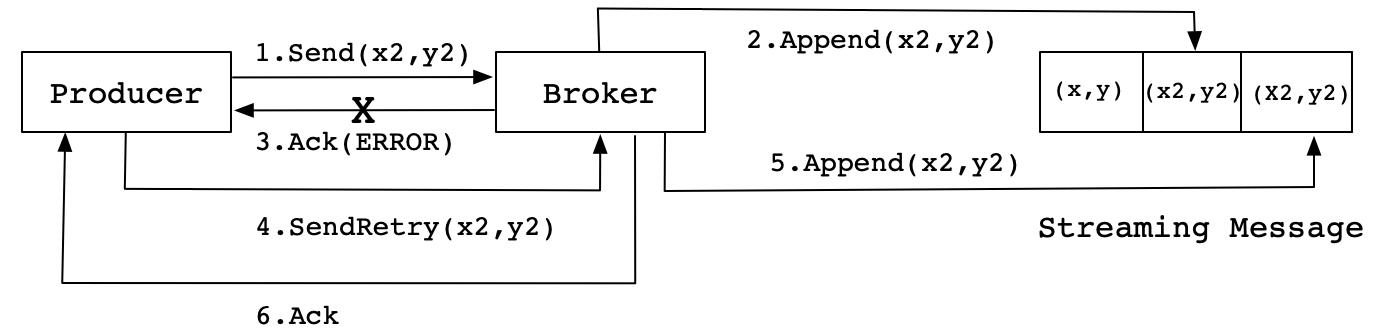
后续的改进:
- 根据当前的 PID 和 Sequence 来判断当前数据是否存在

ProducerID 是什么时候产生的呢?
还记得我们上期说到,当 实例化 KafkaProducer 的时候,会在后台产生一个新的线程 Sender,创建与各个 Broker 的连接。那么我们的 ProducerID 就是在这个 Sender 线程中产生的。
在 Kafka 的 org.apache.kafka.clients.producer.internals.Sender 类中,会有一个 maybeWaitForProducerId() 方法,主要在 ProducerIdAndEpoch producerIdAndEpoch = new ProducerIdAndEpoch(initProducerIdResponse.producerId(), initProducerIdResponse.epoch()); 中。
private void maybeWaitForProducerId()
while (!forceClose && !transactionManager.hasProducerId() && !transactionManager.hasError())
Node node = null;
try
node = awaitLeastLoadedNodeReady(requestTimeoutMs);
if (node != null)
ClientResponse response = sendAndAwaitInitProducerIdRequest(node);
InitProducerIdResponse initProducerIdResponse = (InitProducerIdResponse) response.responseBody();
Errors error = initProducerIdResponse.error();
if (error == Errors.NONE)
ProducerIdAndEpoch producerIdAndEpoch = new ProducerIdAndEpoch(
initProducerIdResponse.producerId(), initProducerIdResponse.epoch());
transactionManager.setProducerIdAndEpoch(producerIdAndEpoch);
return;
else if (error.exception() instanceof RetriableException)
log.debug("Retriable error from InitProducerId response", error.message());
else
transactionManager.transitionToFatalError(error.exception());
break;
else
log.debug("Could not find an available broker to send InitProducerIdRequest to. Will back off and retry.");
catch (UnsupportedVersionException e)
transactionManager.transitionToFatalError(e);
break;
catch (IOException e)
log.debug("Broker disconnected while awaiting InitProducerId response", node, e);
log.trace("Retry InitProducerIdRequest in ms.", retryBackoffMs);
time.sleep(retryBackoffMs);
metadata.requestUpdate();
而我们的 SequenceNumber 则是在 ProducerBatch 中的 setProducerState 添加了一些信息
public void setProducerState(ProducerIdAndEpoch producerIdAndEpoch, int baseSequence, boolean isTransactional)
recordsBuilder.setProducerState(producerIdAndEpoch.producerId, producerIdAndEpoch.epoch, baseSequence, isTransactional);
public void setProducerState(long producerId, short producerEpoch, int baseSequence, boolean isTransactional)
if (isClosed())
throw new IllegalStateException("Trying to set producer state of an already closed batch. This indicates a bug on the client.");
this.producerId = producerId;
this.producerEpoch = producerEpoch;
this.baseSequence = baseSequence;
this.isTransactional = isTransactional;
通过上面的讲述,我们可以看到,我们的 Producer 已经实现了幂等性。但需要注意,我们的 PID 和 SequenceNumber 是针对某 Topic 的某 Partition 进行的,也就是在不同的分区没办法保证消息重复性。
2. 事务
我们怎么能保证多分区的消息无重复呢?答案就是:事务
数据库的事务是经典的 ACID:原子性、一致性、隔离性、持久性
**隔离表示并发执行的事务彼此之间不受影响。**对于隔离的级别,不同的数据库有不同的定义,比如:可重复读、已提交读等。
Kafka 自 0.11 版本提供对事务的支持,目前主要在 read committed 隔离级别上做事情。能保证多条消息原子性的写入目标分区,同时也能保证 Consumer 只能看到事务成功提交的信息。
事务型 Producer 能够保证将消息原子性的写入多个分区中,这批消息要么全部写入成功,要么全部失败。
设置方法:
- 和幂等性 Producer 一样,开启 enable.idempotence = true
- 设置 Producer 端参数 transctional.id
实例代码如下:
// 初始化事务
producer.initTransactions();
try
// 开启事务
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
// 提交事务
producer.commitTransaction();
catch (KafkaException e)
// 终止事务
producer.abortTransaction();
我们的 record1 和 record2 被当做一个事务统一提交给 Kafka,要么他们全部提交,要么全部写入失败。当然,如果失败的话,我们的数据还是会写入到 Kafka 的底层日志中。
Comsumer 能不能看到这些消息,取决于下面的配置:
- **read_uncommitted:**表明 Consumer 能够读取到 Kafka 写入的任何消息,不论事务是否提交。当你开启事务时,不要使用这个参数
- **read_committed:**只会读取成功提交事务的消息
我们讲述一下事务具体的执行流程:
首先,Kafka 为了支持事务特性,引入了一个新的组件:Transaction Coordinator。主要负责记录 PID 和 事务状态。
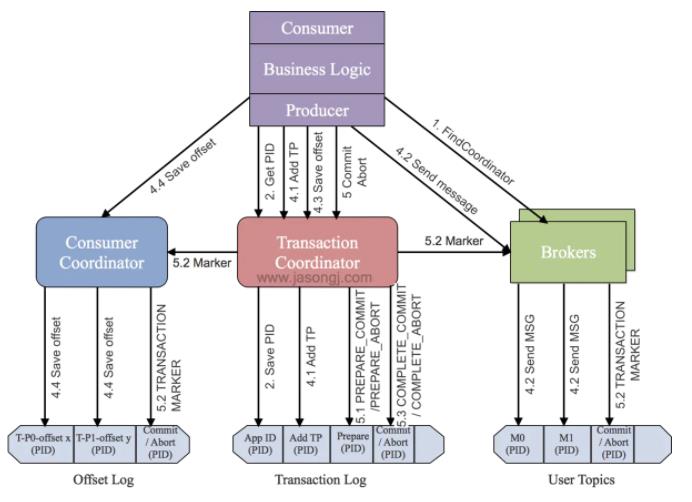
主要分为以下步骤:
-
查找 Transaction Coordinator
- Producer 向任意一个 Borker 发送 FindCoordinator 请求获取 Transaction Coordinator 地址
-
初始化事务 initTransactions
- Producer 发送请求给 Transaction Coordinator ,获取 PID。同时我们的 Transaction Coordinator 也会在 Transaction Log 记录
<TransactionId,pid>的映射关系。
- Producer 发送请求给 Transaction Coordinator ,获取 PID。同时我们的 Transaction Coordinator 也会在 Transaction Log 记录
-
开始事务 beginTransaction
- Producer 在本地记录下这个 Transaction 的状态为开始状态。这个操作是不会通知 Transaction Coordinator 的,只有在第一次发送消息的时候,事务才会开启。
-
read-process-write流程
- 一旦发送消息,我们的事务协调器(Transaction Coordinator)**会将该 <Transaction, Topic, Partition> 存于Transaction Log内,并将其状态置为BEGIN。**另外,如果该 <Topic,Partition> 是第一个,回启动该事务的倒计时。
- 事务日志注册完 <Transaction, Topic, Partition>之后,生产者发送数据,虽然现在还没有执行 commit 或者 abort,但是此时消息已经保存到 Broker 上了。即使后面执行 abort ,消息也不会删除,会更改状态字段标识为 abort
-
事务提交或终结 commitTransaction/abortTransaction
事务协调器执行两阶段提交:
- 第一阶段:将事务日志内的改事务状态设置为
PREPARE_COMMIT或PREPARE_ABORT - 第二阶段:将之前写入该日志所有的消息标记为 commit 或 abort。事务协调器会给所有的 <Topic,Partition> 的 Leader 所在的 Broker 发送请求,Broker 会将具体的控制信息写入到日志。
一旦
Transaction Marker写入完成,Transaction Coordinator 会将最终的COMPLETE_COMMIT或COMPLETE_ABORT状态写入Transaction Log中以标明该事务结束。 - 第一阶段:将事务日志内的改事务状态设置为
以上是关于Kafka从入门到成神系列 五Kafka 幂等性及事务的主要内容,如果未能解决你的问题,请参考以下文章