时间序列分类算法简介及其在能耗数据分类上的应用
Posted 南洋理工CAP组
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了时间序列分类算法简介及其在能耗数据分类上的应用相关的知识,希望对你有一定的参考价值。
时间序列分类算法简介
及其在能耗数据分类上的应用
李元龙/文
本文首先简要介绍最近几年来时间序列分类算法的最新研究成果,包括dynamic time warping的各种改进技术和相关研究,以及最新的聚合式算法(ensemble algorithm)。其次以根据能耗数据来监测服务器运行程序的研究为实例,介绍如何对实际应用中的时间序列数据进行更准确的分类。
时间序列分类算法综述
时间序列分类问题(Time Series Classification, TSC)是数据挖掘中的一个经典问题。其核心问题定义如下:

给定时间序列集合S,对任意时间序列x属于S, 其所属类别(label)为lx。给出任意测试数据x‘,求预测其可能所属的类别。

比如有一些人参与不同的运动项目。 假定我们采集了不同项目的运动轨迹数据集,那么给定一个未知的人的运动轨迹,判断其参与的运动项目就是个典型的时间序列分类问题。
上述问题与基于欧式距离的经典分类问题并无差别。然而在实际中,经典分类算法在时间序列分类上的表现一般较差,其根本原因在于时间序列数据与传统的空间点数据存在关键不同:对于一个时间序列x,其每一个时刻的测量值对应于传统欧式空间的一个维度。在传统的欧氏空间中,维度之间的关联关系是有限的,不同维度的数值大小可以千差万别。然而对于一个时间序列,其所有的信息都包含在不同时刻的变化中。时间序列通常会按照某一些模式变化,因此其数据在不同维度的上的关联性非常重要。基于此差异,时间序列数据无法很好地被传统基于欧式距离的分类算法所求解。
由于欧式距离不能很好地针对时间序列的波动模式进行分类,研发更适合时间序列分类的距离度量就成为关键,这其中最经典的时间序列距离度量就是Dynamic Time Warping (DTW)。 DTW的原理如下:

图 1
针对序列x和y,DTW计算在卷曲时间轴的情况下两个序列最好的匹配结果,并以这个匹配结果来计算他们之间的距离。如上图所示,x和y两个序列有相同的模式但是y序列在时间上移后了。如用欧式距离,x与y因距离较大很可能会被归为不同类别; 而DTW可以准确判别出x和y模式上的类似并得出一个较小的距离度量。实际上,DTW不仅可以考虑到上述简单的平移情形,还能考虑到时间轴上局部的缩放变形等。DTW通过对时间序列波动模式的分析可得到更好的时间序列分类结果。研究表明,在时间序列分类问题上,DTW距离度量配合简单的最小距离分类法(nearest neighbor)就可以取得较传统欧式距离算法(如SVM、经典多层神经网络、决策树、Adaboost)压倒性的优势。
DTW更进一步衍生出多种不同的变种,例如由Keogh和 Pazzani 提出的基于序列一阶导数的改进便取得了良好的效果;其中一种简单的方法叫Complexity Invariant distance (CID),其利用一阶导数信息对DTW距离做计算,在某些问题上具有突出效果。
除了DTW,还有其他考量时间序列的波动模式算法。例如Ye 和Keogh提出的Shapelet方法:考察序列中具有代表意义的子序列来作为Shapelet特征而进行分类。Lin等人提出了基于字典的方法,将序列根据特定的字典转化为词序列,从而进行分类。Deng提出了基于区间的方法,从区间中提取波动的特征。
除了上述方法外,聚合算法(将多种不同算法聚合在一起)的研究也有了长足的进步。最近提出的COTE算法几乎将上述所有不同分类算法聚合在一起,得到了优异的分类效果。想要进一步了解上述主要算法的细节以及更全面的时间序列分类算法综述,请参考“The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms. Extended Version”
基于能耗数据来监测服务器运行程序
时间序列分类算法具有广泛的应用。下面介绍一个在不干扰server运行状态下,基于服务器的能耗数据来判断正在运行的程序的应用。
该应用的核心技术路线如下:
首先在一个server上运行各种不同的程序,采集运行程序时server的能耗时间序列;运用这些数据(程序名作为label)训练一个分类模型;然后给定任意检测到的能耗数据,判断正在运行的程序。
我们收集了13类数据进行实验。这些数据一共有3000条,每条长度为200个时间节点。这些数据记录了不同程序运行时server的能耗(W)数据。
为了显示时间序列分类算法的优势,我们首先采用传统的分类算法分析这些数据。结果显示,在所测试的算法中,即便是表现最好random forest其分类准确率仅达63%左右, 而标准的多层神经网、SVM及基于欧式距离的算法只有50%左右的准确率。之所以准确率较低,是因为当我们把时间序列看作欧式空间中的点数据集时,其可分性非常差。
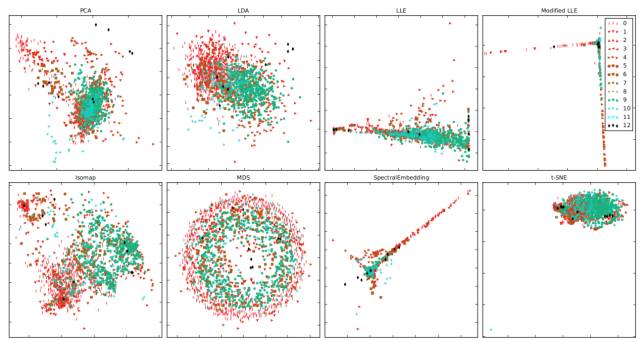
图2
将基于八种不同方法(从经典PCA到效果领先的基于流形学习的降维方法)所采集的数据投射到一个二维空间,可以得到如图2所示的效果图。可以看到,并没有一种方法可以呈现出非常好的类别分布。
鉴于此,我们提出基于DTW的时间序列分类方法对能耗数据进行分类与判断:
首先,虽然采用DTW距离可将分类准确度提高至84%,但分类速度慢,因此我们提出一种考察局部模式信息、对DTW距离函数加以改进的方案,即Local Time Warping (LTW)。 LTW被设计为非交换率,也就是LTW(x, y)可能不等于LTW(y, x):将LTW与最近临分类算法相配合来判断一个序列x’属于哪一类时,我们只需要找哪个训练数据y离x’最近,而不需要x‘也离y很近。这么做可使距离衡量的定义更为宽松,从而可对复杂分布的数据进行更好地分类。采用LTW这一DTW距离函数改进方案,算法的时间效率可提升近10倍(相对于经典DTW实现),分类准确率可达到88%。
同时,我们引入基于LSTM(Long Short Term Memory Neural Network)的分类算法。LSTM是一个具有序列数据建模能力的神经网络。随着深度学习的蓬勃发展,它的突出效果也日益显现。我们采用了一个经典的LSTM层来对数据进行分类,结构如下:
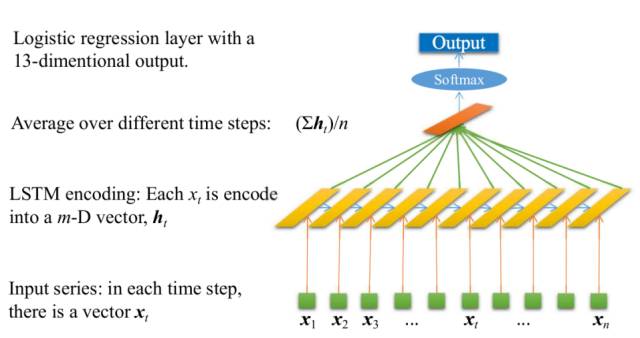
图3
经测试,LSTM算法的分类准确率也达到88%左右。
传统聚合算法并没有考虑到LSTM。LSTM在上述问题上的优异表现证明可以聚合LSTM与传统基于DTW的方法。虽然两种算法的分类效果类似(88%),但由于两者在原理上截然不同,可以预见他们准确预测的样本会有明显差别。我们将LTW和LSTM合二为一:将两者的分类概率向量简单相加,便可取得93%左右的实际分类效果。
综上,这种聚合LTW和LSTM的时间分类算法,对server能耗序列进行分类的准确率可达93%。这说明仅仅利用server的能耗数据,我们就有很大概率准确检测server内部正在运行何种程序。这样的检测机制可以推广到所有的电器。
本文简单总结了现有基于DTW的分类方法,并针对服务器能耗数据提出了一种聚合改进的距离衡量方法LTW和LSTM神经网络的方法,实现了93%的分类准确率。
时间序列分类问题是一个非常有意思的问题,尤其是当对比DTW和LSTM的不同作用机制时。运用DTW计算距离,针对不同的序列对,计算中的序列index warping是不同的。DTW实际采用动态规划来计算距离。这是一个严格意义的程序而不是一个简单的计算公式。而LSTM是一个固定的训练好的神经网络。针对不同的序列,其网络权重在训练好之后都不会变化,却可以达到类似DTW的效果。这是否在某种程度上证明LSTM可以类比动态规划呢?

本文版权归作者所有。
新加坡南洋理工CAP组
以上是关于时间序列分类算法简介及其在能耗数据分类上的应用的主要内容,如果未能解决你的问题,请参考以下文章