推荐系统-大规模信息网络Embedding表征学习
Posted 机器学习算法工程师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统-大规模信息网络Embedding表征学习相关的知识,希望对你有一定的参考价值。
编辑:陈人和
前 言
该方法相比于deepwalk来说,deepwalk本身是针对无权重的图,而且根据其优化目标可以大致认为是针对二阶相似度的优化,但是其使用random walk可以认为是一种DFS的搜索遍历,而针对二阶相似度来说,BFS的搜索遍历更符合逻辑。而LINE同时考虑来一阶和二阶相似度,一阶相似度可以认为是局部相似度,直接关联。二阶相似度可以作为一阶相似度的补充,来弥补一阶相似度的稀疏性。
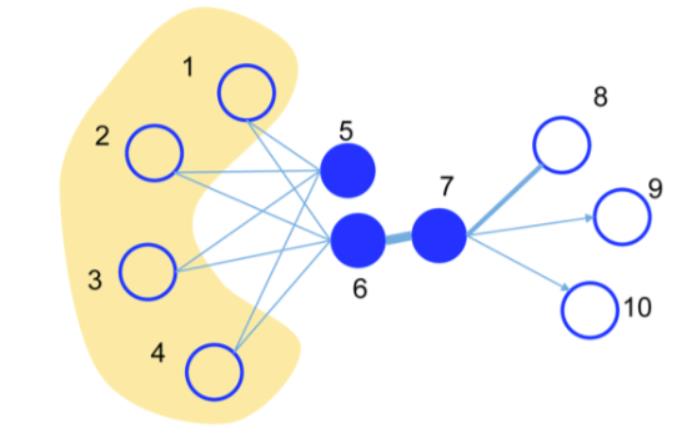
章节目录
论文解读
源码说明与运行
源码解析
分布式实现(腾讯Angel)
推荐场景中的实际应用
01
论文解读
定义
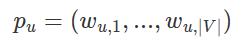
一阶近似
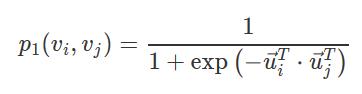
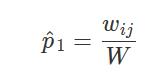
,即为全部权重的归一化后的占比,这里
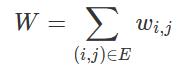
,所以对应的优化目标为
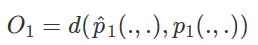
这就是我们的目标函数,即损失函数,我们要最小化该目标,让预定义的两个点之间的联合概率尽量靠近经验概率。d(.,.)用于度量两个分布之间的距离,作者选择KL散度(即交叉熵)来作为距离度量。那么使用KL散度并忽略常数项后,可以得到:
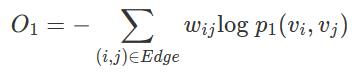
这就是最终的优化目标,这里需要注意,一阶相似度只能用于无向图。
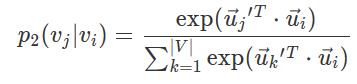
其中|V|是上下文节点的数量。其实和一阶的思路类似,这里用softmax对邻接节点做了一下归一化。优化目标也是去最小化分布之间的距离:
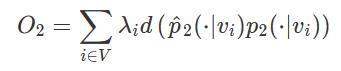
这里d(. , .)用于度量两个分布之间的差距。因为考虑到图中的节点重要性可能不一样,所以设置了参数λi来对节点进行加权。可以通过节点的出入度或者用pagerank等算法来估计出来。而这里的经验分布则被定义为:
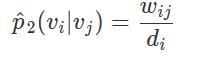
其中,w_ij是边(i, j)的权重,d_i是节点i的出度,即
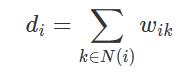
而N(i)就是节点i的出度节点的集合。同样采用KL散度作为距离度量,可以得到如下优化目标:
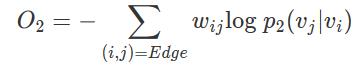
结合一阶近似和二阶近似
但是一般来说,从节点和边的性质上来说,能用一阶就不能用二阶,反之亦然。比如github上的相互关注,就是典型的一阶关系,因为彼此都是好基友。但是比如抖音上的屌丝男关注了女神,那就绝对不能用一阶关系,而应该是二阶关系。
这篇文章就是按照第二种方法,用一种复杂度为O(1)的方法:alias采样法,该方法在本文后面有详细描述。
02
源码说明与运行
网络的输入由网络中的边组成。输入文件的每一行代表网络中的一个DIRECTED边缘,指定为格式“起点-终点-权重”(可以用空格或制表符分隔)。对于每个无向边,用户必须使用两个DIRECTED边来表示它。以下是一个词共现网络的输入示例:
good the 3the good 3good bad 1bad good 1bad of 4of bad 4
4运行
./line -train network_file -output embedding_file -binary 1 -size 200 -order 2 -negative 5 -samples 100 -rho 0.025 -threads 20train,网络的输入文件;
output,嵌入的输出文件;
binary,是否以二进制模式保存输出文件;默认是0(关);
size,嵌入的维度;默认是100;
order,使用的相似度; 1为一阶,2为二阶;默认是2;
negative,负采样中负采样样本的数目;默认是5;
samples,训练样本总数(*百万);
rho,学习率的起始值;默认是0.025;
-
threads,使用的线程总数;默认是1。
5文件夹中的文件
数据集中共包括4945382条边(有向边,因为无向图中每条边被看做两条有向边,所以Youtube网络中有2472691条边)和至少937968个点(文件中节点的名字并不是连续的,有些节点的度为0,在数据集文件中没有出现)。
运行示例
将单向的关系变为双向的关系,因为youtobe好有关系是无向图
python3 preprocess_youtube.py youtube-links.txt net_youtube.txt通过reconstruct程序对原网络进行重建(1h)
./reconstruct -train net_youtube.txt -output net_youtube_dense.txt -depth 2 -threshold 1000两次运行line,分别得到一阶相似度和二阶相似度下的embedding结果
./line -train net_youtube_dense.txt -output vec_1st_wo_norm.txt -binary 1 -size 128 -order 1 -negative 5 -samples 10000 -threads 40./line -train net_youtube_dense.txt -output vec_2nd_wo_norm.txt -binary 1 -size 128 -order 2 -negative 5 -samples 10000 -threads 40
利用normalize程序将实验结果进行归一化
./normalize -input vec_1st_wo_norm.txt -output vec_1st.txt -binary 1./normalize -input vec_2nd_wo_norm.txt -output vec_2nd.txt -binary 1
使用concatenate程序连接一阶嵌入和二阶嵌入的结果
./concatenate -input1 vec_1st.txt -input2 vec_2nd.txt -output vec_all.txt -binary 1编译LINE源码
linux下GSL安装:
注意,可能会报错:
line.cpp:(.text+0x30b8): undefined reference to `gsl_rng_uniform'这时候,需要在编译选项
-lm -pthread -Ofast -march=native -Wall -funroll-loops -ffast-math -Wno-unused-result中加入
-lgsl -lgslcblas就好啦。
具体参见linux下GSL安装、can't link GSL properly?。
问题1
../bin/reconstruct -train ../data/net_youtube.txt -output ../data/net_youtube_dense.txt -depth 2 -threshold 1000会出现
../bin/reconstruct: error while loading shared libraries: libgsl.so.23: cannot open shared object file: No such file or directory解决办法:
export LD_LIBRARY_PATH=/usr/local/lib具体参见error while loading shared libraries: libgsl.so.23: cannot open shared object file: No such file or directory:
问题2
运行代码时可能还会遇到这个问题:
../bin/line: /lib64/libm.so.6: version `GLIBC_2.15' not found (required by ../bin/line)源码中存在的bug
要改正这个bug很简单,就是强制将index的数据类型改为longlong就行:
if (is_binary) for (b = 0; b < (unsigned long long)dim; b++) fwrite(&emb_vertex[a * (unsigned long long)dim + b], sizeof(real), 1, fo_vertex);
03
源码解析
将单向的关系变为双向的关系,因为youtobe好有关系是无向图
python3 preprocess_youtube.py youtube-links.txt net_youtube.txt通过reconstruct程序对原网络进行稠密化(1h)
./reconstruct -train net_youtube.txt -output net_youtube_dense.txt -depth 2 -threshold 1000两次运行line,分别得到一阶相似度和二阶相似度下的embedding结果
./line -train net_youtube_dense.txt -output vec_1st_wo_norm.txt -binary 1 -size 128 -order 1 -negative 5 -samples 10000 -threads 40./line -train net_youtube_dense.txt -output vec_2nd_wo_norm.txt -binary 1 -size 128 -order 2 -negative 5 -samples 10000 -threads 40
利用normalize程序将实验结果进行归一化
./normalize -input vec_1st_wo_norm.txt -output vec_1st.txt -binary 1./normalize -input vec_2nd_wo_norm.txt -output vec_2nd.txt -binary 1
使用concatenate程序连接一阶嵌入和二阶嵌入的结果
./concatenate -input1 vec_1st.txt -input2 vec_2nd.txt -output vec_all.txt -binary 1这个代码很简单,就是上述的流程。建议自己先把youtube-links.txt数据下下来,把那段下载的代码屏蔽掉,这样快一些。
#!/bin/shg++ -lm -pthread -Ofast -march=native -Wall -funroll-loops -ffast-math -Wno-unused-result line.cpp -o line -lgsl -lm -lgslcblasg++ -lm -pthread -Ofast -march=native -Wall -funroll-loops -ffast-math -Wno-unused-result reconstruct.cpp -o reconstructg++ -lm -pthread -Ofast -march=native -Wall -funroll-loops -ffast-math -Wno-unused-result normalize.cpp -o normalizeg++ -lm -pthread -Ofast -march=native -Wall -funroll-loops -ffast-math -Wno-unused-result concatenate.cpp -o concatenatewget http://socialnetworks.mpi-sws.mpg.de/data/youtube-links.txt.gzgunzip youtube-links.txt.gzpython3 preprocess_youtube.py youtube-links.txt net_youtube.txt./reconstruct -train net_youtube.txt -output net_youtube_dense.txt -depth 2 -threshold 1000./line -train net_youtube_dense.txt -output vec_1st_wo_norm.txt -binary 1 -size 128 -order 1 -negative 5 -samples 10000 -threads 40./line -train net_youtube_dense.txt -output vec_2nd_wo_norm.txt -binary 1 -size 128 -order 2 -negative 5 -samples 10000 -threads 40./normalize -input vec_1st_wo_norm.txt -output vec_1st.txt -binary 1./normalize -input vec_2nd_wo_norm.txt -output vec_2nd.txt -binary 1./concatenate -input1 vec_1st.txt -input2 vec_2nd.txt -output vec_all.txt -binary 1cd evaluate./run.sh ../vec_all.txtpython3 score.py result.txt
核心代码如下:
for (sv = 0; sv != num_vertices; sv++){///xxxsum = vertex[sv].sum_weight;node.push(sv);depth.push(0);weight.push(sum);while (!node.empty()){cv = node.front();cd = depth.front();cw = weight.front();node.pop();depth.pop();weight.pop();if (cd != 0) vid2weight[cv] += cw;// 一阶+二阶if (cd < max_depth){len = neighbor[cv].size();// 该节点的出度sum = vertex[cv].sum_weight;// 该节点的出度权值之和for (int i = 0; i != len; i++){node.push(neighbor[cv][i].vid);// 该节点的所有出度的链接节点depth.push(cd + 1);// 阶层加1weight.push(cw * neighbor[cv][i].weight / sum);//}}}//xxx}
这个程序和word2vec的风格很像,估计就是从word2vec改的。
首先在main函数这,特别说明一个参数:total_samples,这个参数是总的训练次数,LINE没有训练轮数的概念,因为LINE是随机按照权重选择边进行训练的。
我们直接看TrainLINE()函数中的TrainLINEThread()这个函数,多线程跑的就是这个函数。
训练结束条件是,当训练的次数超过total_samples的次数以后就停止训练。如下:
if (count > total_samples / num_threads + 2) break;首先要按边的权重采集一条边edge(u, v),得到其这条边的起始点u和目标点v:
curedge = SampleAnEdge(gsl_rng_uniform(gsl_r), gsl_rng_uniform(gsl_r));u = edge_source_id[curedge];v = edge_target_id[curedge];
然后最核心的部分就是负采样并根据损失函数更新参数:
lu = u * dim;for (int c = 0; c != dim; c++) vec_error[c] = 0;// NEGATIVE SAMPLINGfor (int d = 0; d != num_negative + 1; d++){if (d == 0){target = v;label = 1;}else{target = neg_table[Rand(seed)];label = 0;}lv = target * dim;if (order == 1) Update(&emb_vertex[lu], &emb_vertex[lv], vec_error, label);if (order == 2) Update(&emb_vertex[lu], &emb_context[lv], vec_error, label);}for (int c = 0; c != dim; c++) emb_vertex[c + lu] += vec_error[c];
很显然,1阶关系训练的是两个节点的emb_vertex,而2阶关系训练的是开始节点的emb_vertex(节点本身的embedding)和目标节点的emb_context(节点上下文的embedding)。
接下来进入最关键的权值更新函数Update():
/* Update embeddings */void Update(real *vec_u, real *vec_v, real *vec_error, int label){real x = 0, g;for (int c = 0; c != dim; c++) x += vec_u[c] * vec_v[c];g = (label - FastSigmoid(x)) * rho;for (int c = 0; c != dim; c++) vec_error[c] += g * vec_v[c];for (int c = 0; c != dim; c++) vec_v[c] += g * vec_u[c];}
这时我们需要回到论文中,看公式(8)和公式(7):
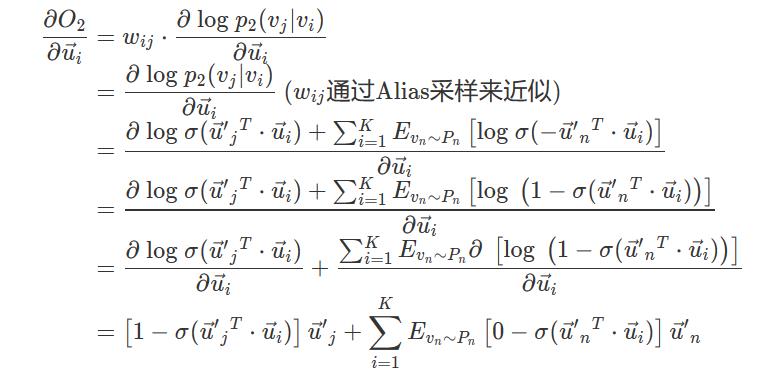
上式中的
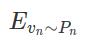
target = neg_table[Rand(seed)];label = 0;
边eage(u, v)中的v会在每次update时更新,u会在负采样完之后统一更新。
// 边eage(u, v)中的v会在每次update时更新void Update(real *vec_u, real *vec_v, real *vec_error, int label){xxxxxfor (int c = 0; c != dim; c++) vec_error[c] += g * vec_v[c];for (int c = 0; c != dim; c++) vec_v[c] += g * vec_u[c];}void *TrainLINEThread(void *id){xxxwhile (1){// NEGATIVE SAMPLINGfor (int d = 0; d != num_negative + 1; d++){xxx}// 边eage(u, v)中的u会在负采样完之后统一更新for (int c = 0; c != dim; c++) emb_vertex[c + lu] += vec_error[c];count++;}xxx}
问题:比如一个随机事件包含四种情况,每种情况发生的概率分别为:
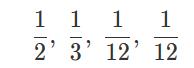
我之前有在【数学】均匀分布生成其他分布的方法中写过均匀分布生成其他分布的方法,这种方法就是产生0~1之间的一个随机数,然后看起对应到这个分布的CDF中的哪一个,就是产生的一个采样。比如落在0~1/2之间就是事件A,落在1/2~5/6之间就是事件B,落在5/6~11/12之间就是事件C,落在11/12~1之间就是事件D。
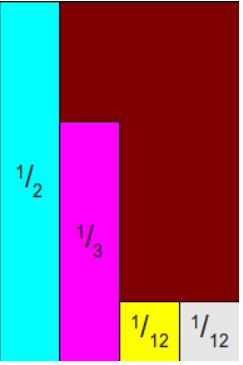
可以像上图这样采样,将四个事件排成4列:1~4,扔两次骰子,第一次扔1~4之间的整数,决定落在哪一列。
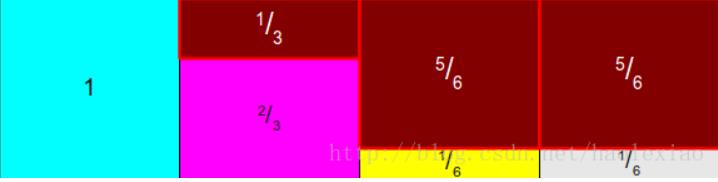
如上如所示,将其按照最大的那个概率进行归一化。在1步中决定好哪一列了之后,扔第二次骰子,0~1之间的任意数,如果落在了第一列上,不论第二次扔几,都采样时间A,如果落在第二列上,第二次扔超过2323则采样失败,重新采样,如果小于2323则采样时间B成功,以此类推。
-
这样算法复杂度最好为O(1)O(1)最坏有可能无穷次,平均意义上需要采样O(N)
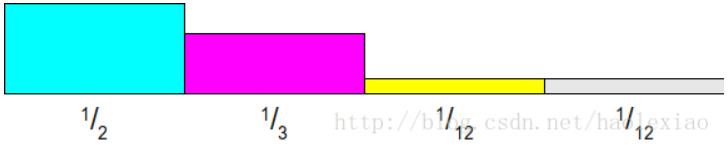
还是如上面的那样的思路,但是如果我们不按照其中最大的值去归一化,而是按照其均值归一化。即按照1/N(这里是1/4)归一化,即为所有概率乘以N,得到如下图:
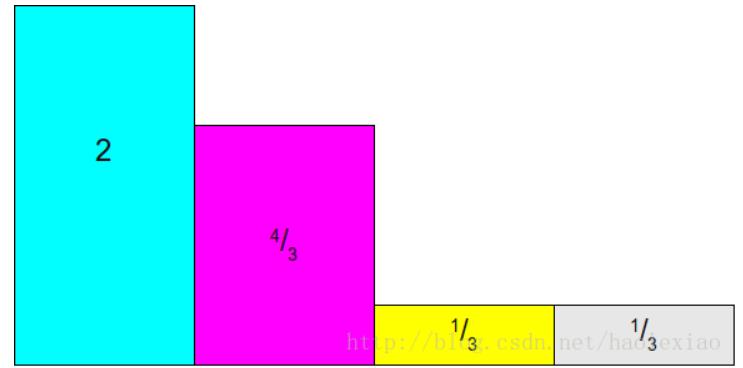
其总面积为N,然后可以将其分成一个1*N的长方形,如下图:
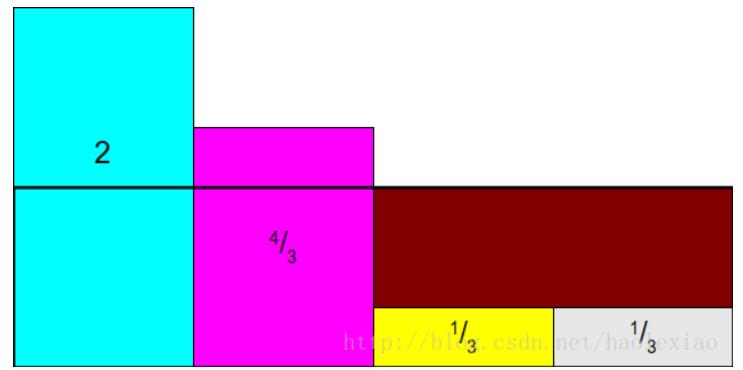
将前两个多出来的部分补到后面两个缺失的部分中。先将1中的部分补充到4中:
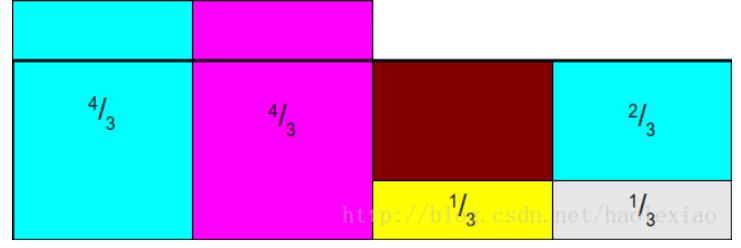
这时如果,将1,2中多出来的部分,补充到3中,就麻烦了,因为又陷入到如果从中采样超过2个以上的事件这个问题中,所以Alias Method一定要保证:每列中最多只放两个事件 所以此时需要讲1中的补满3中去:
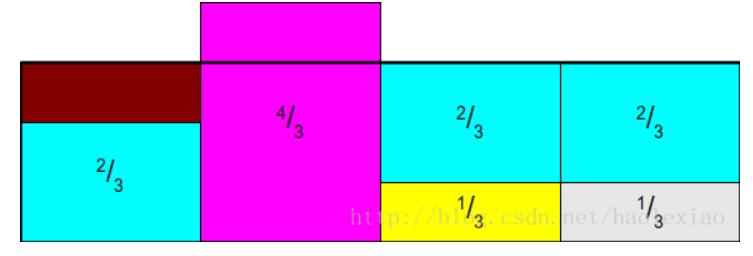
再将2中的补到1中:
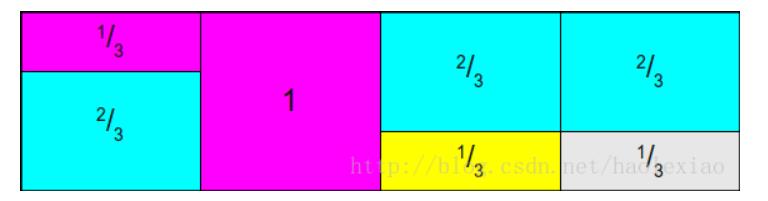
-
按照上面说的方法,将整个概率分布拉平成为一个1*N的长方形即为Alias Table,构建上面那张图之后,储存两个数组,一个里面存着第i列对应的事件i矩形占的面积百分比【也即其概率】,上图的话数组就为Prab[2/3, 1, 1/3, 1/3],另一个数组里面储存着第i列不是事件i的另外一个事件的标号,像上图就是Alias[2 NULL 1 1] -
产生两个随机数,第一个产生1~N 之间的整数i,决定落在哪一列。扔第二次骰子,0~1之间的任意数,判断其与Prab[i]大小,如果小于Prab[i],则采样i,如果大于Prab[i],则采样Alias[i]
Naive方法
存在性证明
那么Alias Table一定存在吗,如何去证明呢?要证明Alias Table一定存在,就说明上述的算法是能够一直运行下去,直到所有列的面积都为1了为止,而不是会中间卡住。一个直觉就是,这一定是可以一直运行下去的。上述方法每运行一轮,就会使得剩下的没有匹配的总面积减去1,在第n轮,剩下的面积为N-n,如果存在有小于1的面积,则一定存在大于1的面积,则一定可以用大于1的面积那部分把小于1部分给填充到1,这样就进入到了第n+1轮,最后一直到所有列面积都为1。更为严谨的证明见Blog:Darts, Dice, and Coins: Sampling from a Discrete Distribution。
更快的构建方法
至此Alias Method就讲完了,感觉还是一个非常精妙的方法,而且方法实现起来也非常的简单。值得学习。
04
分布式实现(腾讯Angel)
GITHUB:LINE,可直接从Github上把源码下载到本地IDEA编辑器中打开。
进入/data2/recxxxd/angel-2.2.0-bin/bin,直接sh SONA-example,就可以运行了。可以打开SONA-example,查看其内容:
source ./spark-on-angel-env.sh$SPARK_HOME/bin/spark-submit \--master yarn-cluster \--conf spark.ps.jars=$SONA_ANGEL_JARS \--conf spark.ps.instances=10 \--conf spark.ps.cores=2 \--conf spark.ps.memory=6g \--conf spark.hadoop.angel.ps.env="HADOOP_MAPRED_HOME=${HADOOP_MAPRED_HOME:-"/opt/yarn"}" \--conf spark.hadoop.angel.am.env="HADOOP_MAPRED_HOME=${HADOOP_MAPRED_HOME:-"/opt/yarn"}" \--conf spark.hadoop.angel.staging.dir="/tmp/recommend" \--jars $SONA_SPARK_JARS\--name "LR-spark-on-angel" \--driver-memory 10g \--num-executors 10 \--executor-cores 2 \--executor-memory 4g \--class com.tencent.angel.spark.examples.basic.LR \./../lib/spark-on-angel-examples-${ANGEL_VERSION}.jar \input:hdfs://nameservice3/tmp/lu.jiawei/angel \lr:0.1 \
,要想改源码或者替换成其他模型,那就进入~/IdeaProjects/angel/spark-on-angel/examples,然后进行打包编译mvn package。
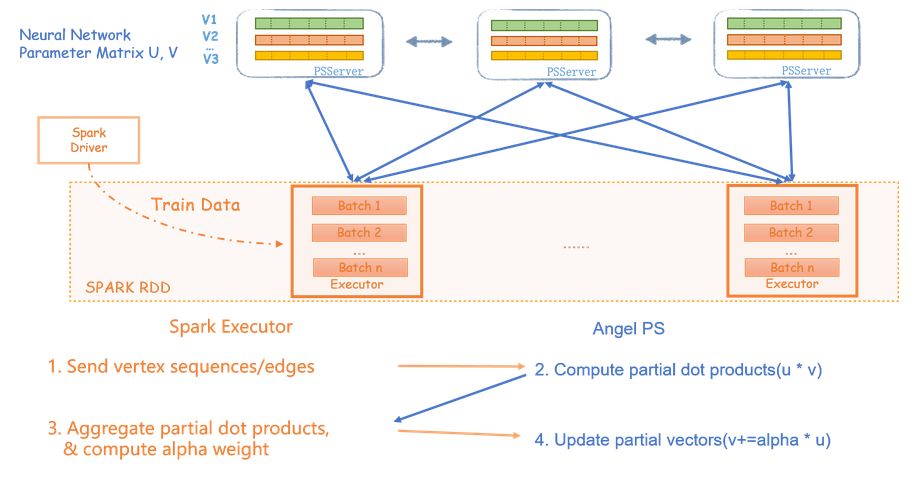
分布式实现原理
Network–Efficient Distributed Word2vec Training System for Large Vocabularies
, 将Embedding向量按维度拆分到多个PS上,节点之间的点积运算可以在每个PS内部进行局部运算,之后再拉取到spark端合并。Spark端计算每个节点的梯度,推送到每个PS去更新每个节点对应的向量维度。
05
推荐场景中的实际应用
通过User的vectext embedding和Item的Context embedding,计算User对Item的喜好,再通过Item的vertex embedding和User的Context embedding,计算Item对User的喜好。然后两者相乘,就是双方的匹配程度。
参考资料:
Embedding算法Line源码简读
https://blog.csdn.net/daiyongya/article/details/80963767
LINE实验
https://www.jianshu.com/p/f6a9af93d081
"LINE源码说明与运行"参考此博客。
【数学】时间复杂度O(1)的离散采样算法—— Alias method/别名采样方法
https://blog.csdn.net/haolexiao/article/details/65157026
Alias Method:时间复杂度O(1)的离散采样方法
https://github.com/snowkylin/line

END
往期回顾
【1】
【2】
【3】
【4】
【5】
机器学习算法工程师
进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助
以上是关于推荐系统-大规模信息网络Embedding表征学习的主要内容,如果未能解决你的问题,请参考以下文章
应用在大规模推荐系统,Facebook提出组合embedding方法 | KDD 2020