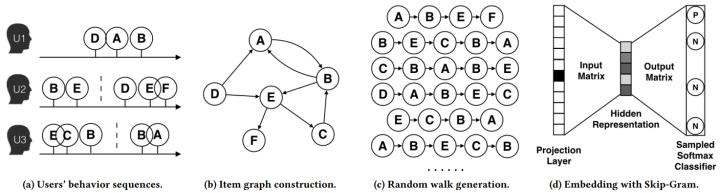
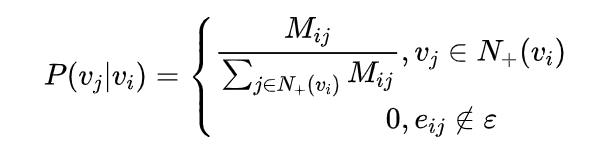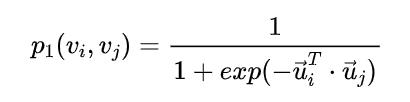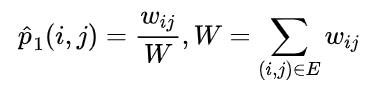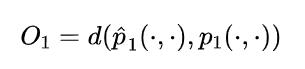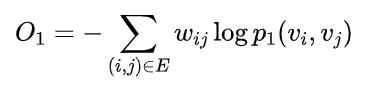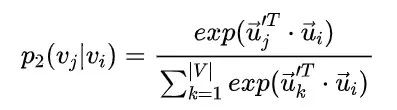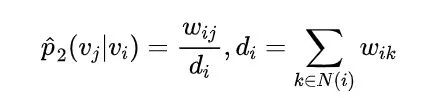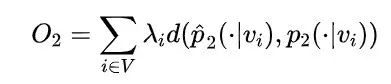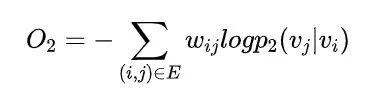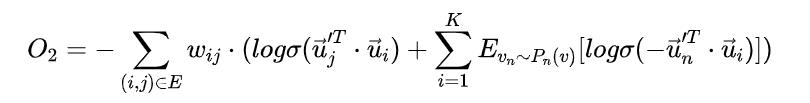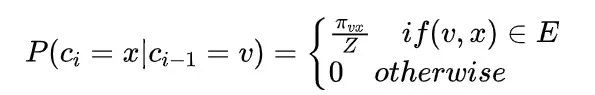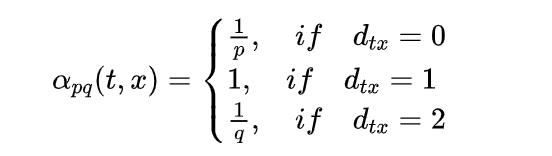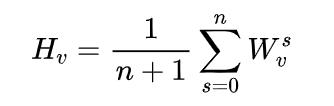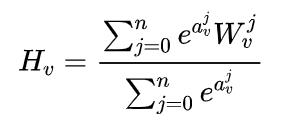注意:在DeepWalk论文中,作者只提出DeepWalk用于无向无权图。DeepWalk用于有向有权图的内容是阿里巴巴论文《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》中提出的Base Graph Embedding(BGE)模型,其实该模型就是对DeepWalk模型的实践,本文后边部分会讲解该模型。
DeepWalk相关论文:[1] Perozzi B, Alrfou R, Skiena S, et al. DeepWalk: online learning of social representations[C]. knowledge discovery and data mining, 2014: 701-710.[2] Wang J, Huang P, Zhao H, et al. Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba[C]. knowledge discovery and data mining, 2018: 839-848.
3. LINE-DeepWalk的改进
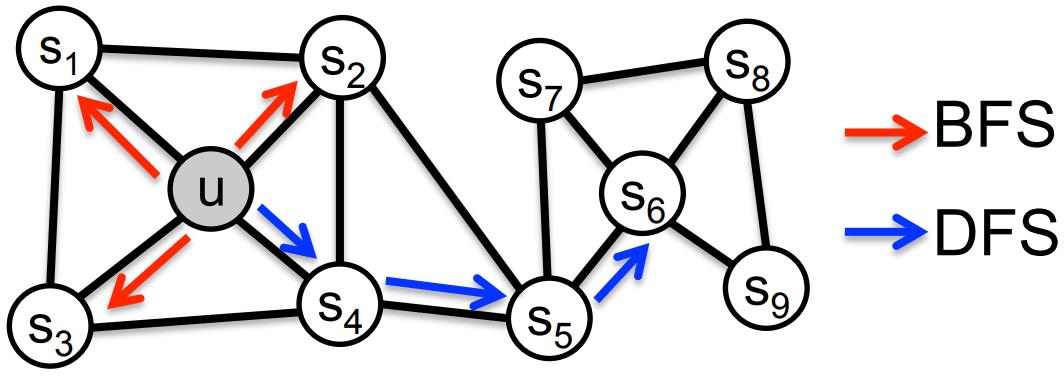
DeepWalk使用DFS(Deep First Search,深度优先搜索)随机游走在图中进行节点采样,使用Word2Vec在采样的序列上学习图中节点的向量表示。LINE(Large-scale Information Network Embedding)也是一种基于邻域相似假设的方法,只不过与DeepWalk使用DFS构造邻域不同的是,LINE可以看作是一种使用BFS(Breath First Search,广度优先搜索)构造邻域的算法。在Graph Embedding各个方法中,一个主要区别是对图中顶点之间的相似度的定义不同,所以先看一下LINE对于相似度的定义。
[1] Tang J, Qu M, Wang M, et al. Line: Large-scale information network embedding[C]//Proceedings of the 24th international conference on world wide web. 2015: 1067-1077.
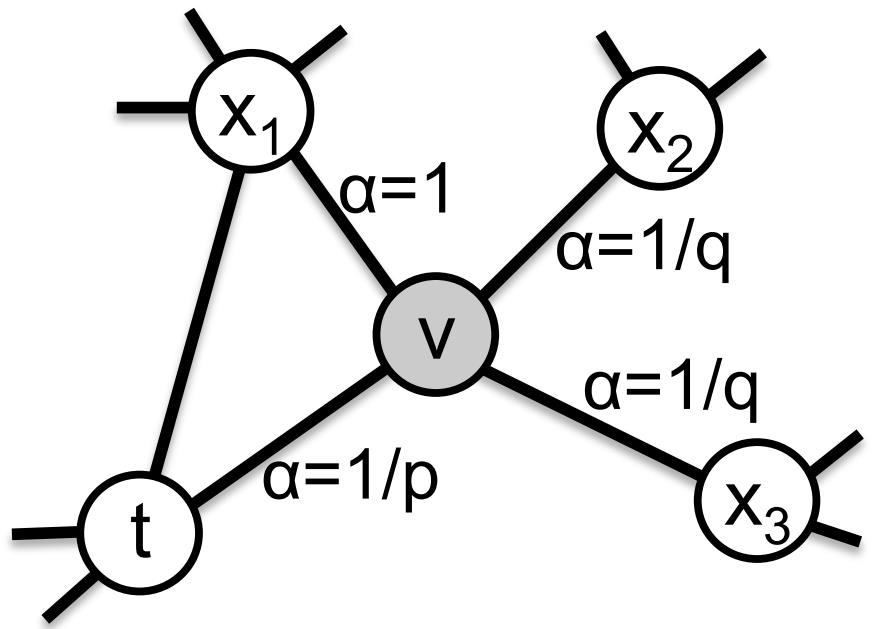
[1] Grover A, Leskovec J. node2vec: Scalable feature learning for networks[C]//Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. 2016: 855-864.
5. EGES - Graph Embedding最佳实践
2018 年,阿里巴巴公布了其在淘宝应用的Embedding方法 EGES(Enhanced Graph Embedding with Side Information)算法,其基本思想是Embedding过程中引入带权重的补充信息(Side Information),从而解决冷启动的问题。 淘宝平台推荐的三个问题:
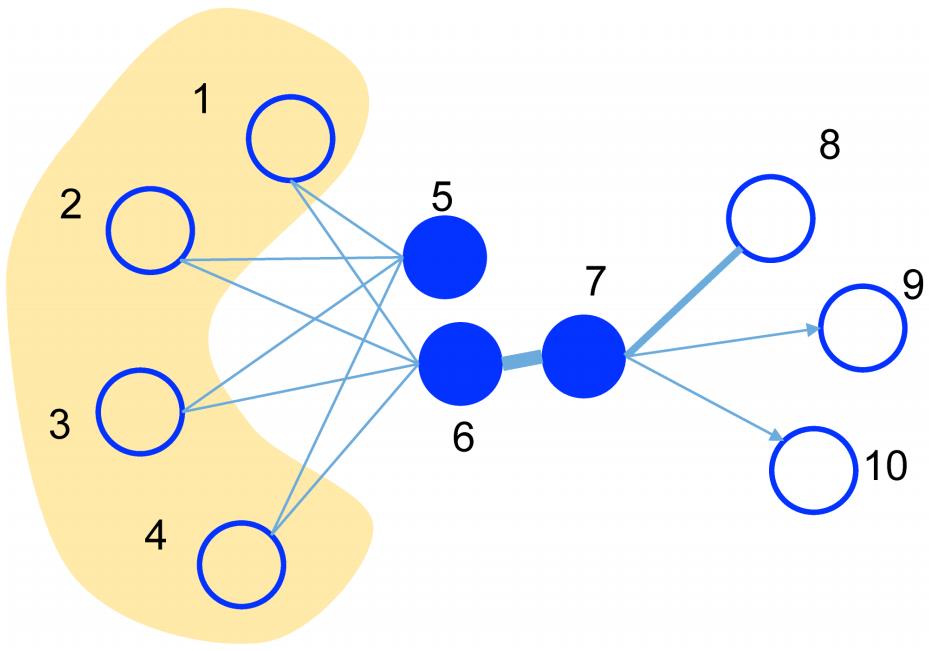
现在业界针对海量数据的推荐问题通用框架是分成两个阶段,即matching 和 ranking。在matching阶段,我们会生成一个候选集,它的items会与用户接触过的每个item具有相似性;接着在ranking阶段,我们会训练一个深度神经网络模型,它会为每个用户根据他的偏好对候选items进行排序。论文关注的问题在推荐系统的matching阶段,也就是从商品池中召回候选商品的阶段,核心的任务是计算所有item之间的相似度。 为了达到这个目的,论文提出根据用户历史行为构建一个item graph,然后使用DeepWalk学习每个item的embedding,即Base Graph Embedding(BGE)。BGE优于CF,因为基于CF的方法只考虑了在用户行为历史上的items的共现率,但是对于少量或者没有交互行为的item,仍然难以得到准确的embedding。 为了减轻该问题,论文提出使用side information来增强embedding过程,提出了Graph Embedding with Side information (GES)。例如,属于相似类别或品牌的item的embedding应该相近。在这种方式下,即使item只有少量交互或没有交互,也可以得到准确的item embedding。 在淘宝场景下,side information包括:category、brand、price等。不同的side information对于最终表示的贡献应该不同,于是论文进一步提出一种加权机制用于学习Embedding with Side Information,称为Enhanced Graph Embedding with Side information (EGES)。
5.1 基于图的Embedding(BGE)
该方案是 DeepWalk 算法的实践,具体流程如下:
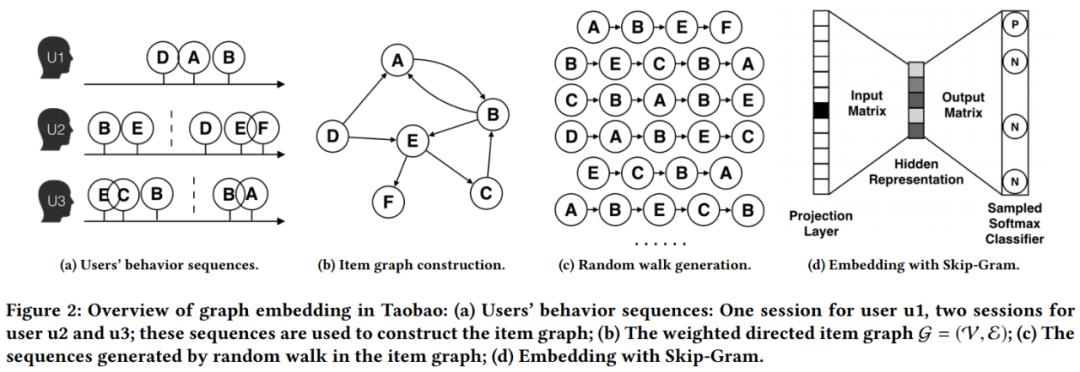
首先,我们拥有上亿用户的行为数据,不同的用户,在每个 Session 中,访问了一系列商品,例如用户 u2 两次访问淘宝,第一次查看了两个商品 B-E,第二次产看了三个商品 D-E-F。
Base Graph Embedding 与 DeepWalk 不同的是:通过 user 的行为序列构建网络结构,并将网络定义为有向有权图。其中:根据行为的时间间隔,将一个 user 的行为序列分割为多个session。session分割可以参考Airbnb这篇论文《Real-time Personalization using Embeddings for Search Ranking at Airbnb》。
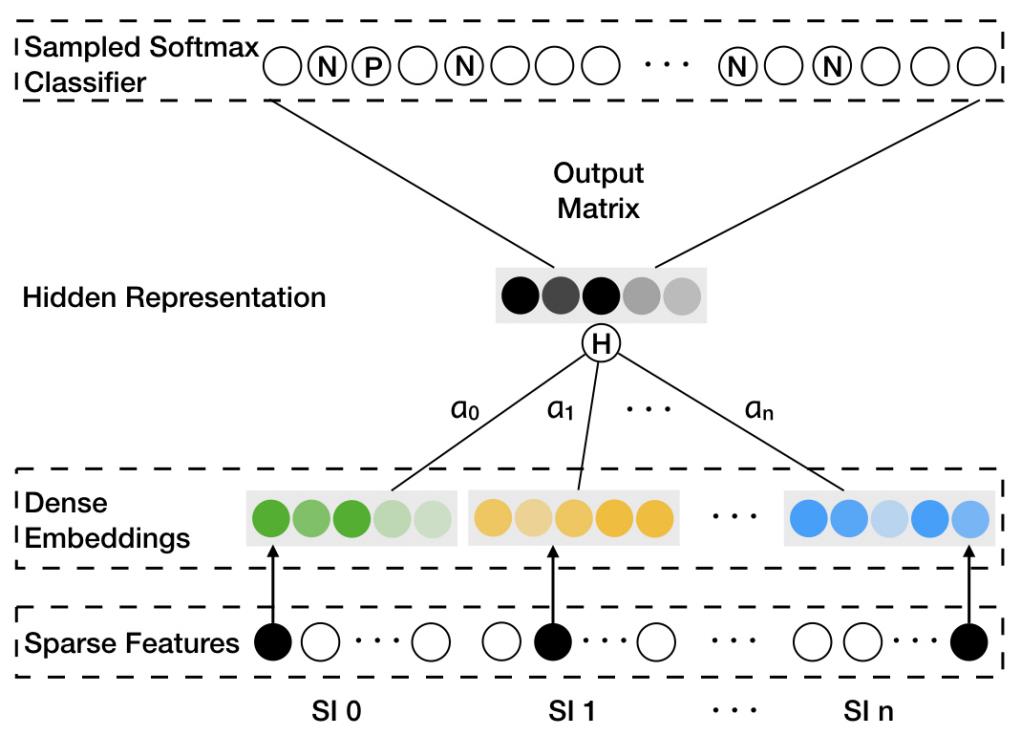
GES中存在一个问题是,针对每个item,它把所有的side information embedding求和后做了平均,没有考虑不同的side information 之间的权重,EGES就是让不同类型的side information具有不同的权重,提出来一个加权平均的方法来聚集这些边界embedding。 因为每个item对其不同边信息的权重不一样,所以就需要额外矩阵来表示每个item边信息的权重,其大小为,是item的个数,是边信息的个数,加是还要考虑item自身Embedding的权重。为了简单起见,我们用表示第个item、第个类型的side information的权重。表示第个item自身Embedding的权重。这样就可以获得加权平均的方法:
[1] Wang J, Huang P, Zhao H, et al. Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba[C]. knowledge discovery and data mining, 2018: 839-848.