深度强化学习 如何训练
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度强化学习 如何训练相关的知识,希望对你有一定的参考价值。
多谢邀请。关于gym可参考我的知乎专栏帖子:强化学习实战 第一讲 gym学习及二次开发 - 知乎专栏。关注该专栏,可以学到很多强化学习的知识(理论知识和实践知识)。下面正式回答你的问题:搞深度强化学习,训练环境的搭建是必须的,因为训练环境是测试算法,训练参数的基本平台(当然,也可以用实际的样机进行训练,但时间和代价是相当大的)。
现在大家用的最多的是openai的gym( github.com/openai/gym ),或者universe
(github.com/openai/unive),。这两个平台非常好,是通用的平台,而且与tensorflow和Theano无缝连接,虽然目前只支持python语言,但相信在不久的将来也会支持其他语言。下面我根据自己的理解,讲下关于gym的一些事情。
Gym的原理是什么?它是新东西吗?
在我看来,gym并不是完全的新东西,它不过是用python语言写的仿真器。对于仿真器大家肯定并不陌生。学控制的人都用过或听过matlab的simulink,学机械的人应该用过动力学仿真软件adams,gym在本质上和simulink,adams没什么区别。
如果把Gym,simulink,adams等等这些仿真器去掉界面显示(如动画显示),剩下的本质不过是一组微分方程。所以Gym,simulink,adams等等一切仿真器的本质是微分方程。比如,运动学微分方程,动力学微分方程,控制方程等。Gym在构造环境时,主要的任务就是构建描述你模型的微分方程。
我们举例说明:
Gym中的CartPole环境是如何构建的:
下面的链接是gym中CartPole环境模型:
github.com/openai/gym/b
在该环境模型中,最核心的函数是def _step(self, action)函数,该函数定义了CartPole的环境模型,而在该函数中最核心的代码如下:
图中方框中又是这段代码中最核心的地方,这两行代码便决定了CartPole的模型。简单的模型,通过手工推导便可完成。
那么对于复杂的模型,比如战斗机器人,各种大型游戏怎么办呢?
这就需要专门的多刚体仿真软件了,这些软件背后的核心技术都是物理引擎。大家可以搜下物理引擎这个词,游戏以及各种仿真软件都要用到物理引擎,用的多的而且开源的物理引擎有:ODE, Bullet, Havok, Physx等。原则上来说利用这些物理引擎都可以搭建训练环境。Gym在搭建机器人仿真环境用的是mujoco,ros里面的物理引擎是gazebo。
下面针对你的问题,逐条回答:
1. gym中CartPole, MountainCar这种环境的构建原理是怎样的?
答:这种简单的环境只需要手动推导便可写出动力学方程,然后可以人为编写环境模型。只是,gym中除了给出了动力学方程,还加入了界面程序,将结果更直观地显示出来。
2. gym中的环境源代码能不能查看和修改?
Gym是开源开发工具,所有代码都可查看和修改。可以模仿gym已有的例子自己创建环境。Gym创建环境很方便,只需要编写你的环境模型,并将你的环境模型注册到环境文件中即可,至于如何构建新的环境,请关注我的知乎专栏,我会在后面讲一讲。我的专栏中深入剖析了gym并给出了创建自己环境的实例,强化学习实战 第一讲 gym学习及二次开发 - 知乎专栏。 参考技术A 深度强化学习一直以来都以智能体训练时间长、计算力需求大、模型收敛慢等而限制很多人去学习,加州大学伯克利分校教授Pieter Abbeel最近发表了深度强化学习的加速方法,解决了一些问题。
深度强化学习一直以来都以智能体训练时间长、计算力需求大、模型收敛慢等而限制很多人去学习,比如:AlphaZero训练3天的时间等,因此缩短训练周转时间成为一个重要话题。
加州大学伯克利分校教授,Pieter Abbeel最近发表了深度强化学习的加速方法,他从整体上提出了一个加速深度强化学习周转时间的方法,成功的解决了一些问题。
最近几年,深度强化学习在各行各业已经有了很成功的应用,但实验的周转时间(turn-around time)仍然是研究和实践中的一个关键瓶颈。
该论文研究如何在现有计算机上优化现有深度RL算法,特别是CPU和GPU的组合。
且作者确认可以调整策略梯度和Q值学习算法以学习使用许多并行模拟器实例。 通过他们进一步发现可以使用比标准尺寸大得多的批量进行训练,而不会对样品复杂性或最终性能产生负面影响。
同时他们利用这些事实来构建一个统一的并行化框架,从而大大加快了两类算法的实验。 所有神经网络计算都使用GPU,加速数据收集和训练。
在使用同步和异步算法的基础上,结果标明在使用整个DGX-1在几分钟内学习Atari游戏中的成功策略。 参考技术B 这个具体就要学深度学习和强化学习的相关知识了,可以拿最简单的DQN举例,DQN就是用神经网络去代替了传统的Q表,从而进行训练。
强化学习系列12:使用julia训练深度强化模型
1. 介绍
使用flux作为深度学习的框架,入门代码:
using ReinforcementLearning
run(E`JuliaRL_BasicDQN_CartPole`)
显示:
This experiment uses three dense layers to approximate the Q value.
The testing environment is CartPoleEnv.
Agent and statistic info will be saved to: `/home/runner/work/JuliaReinforcementLearning.github.io/JuliaReinforcementLearning.github.io/checkpoints/JuliaRL_BasicDQN_CartPole_2020_09_30_05_40_03`
You can also view the tensorboard logs with
`tensorboard --logdir /home/runner/work/JuliaReinforcementLearning.github.io/JuliaReinforcementLearning.github.io/checkpoints/JuliaRL_BasicDQN_CartPole_2020_09_30_05_40_03/tb_log`
To load the agent and statistic info:
```
agent = RLCore.load("/home/runner/work/JuliaReinforcementLearning.github.io/JuliaReinforcementLearning.github.io/checkpoints/JuliaRL_BasicDQN_CartPole_2020_09_30_05_40_03", Agent)
BSON.@load joinpath("/home/runner/work/JuliaReinforcementLearning.github.io/JuliaReinforcementLearning.github.io/checkpoints/JuliaRL_BasicDQN_CartPole_2020_09_30_05_40_03", "stats.bson") total_reward_per_episode time_per_step
根据提示启动tensorboard,如果启动不了,去安装包里面把如下的文件夹删除:
~-nsorboard-1.14.0.dist-info
~b_nightly-2.1.0a20191026.dist-info
~ensorboard-1.13.1.dist-info
~ensorboard-1.14.0.dist-info
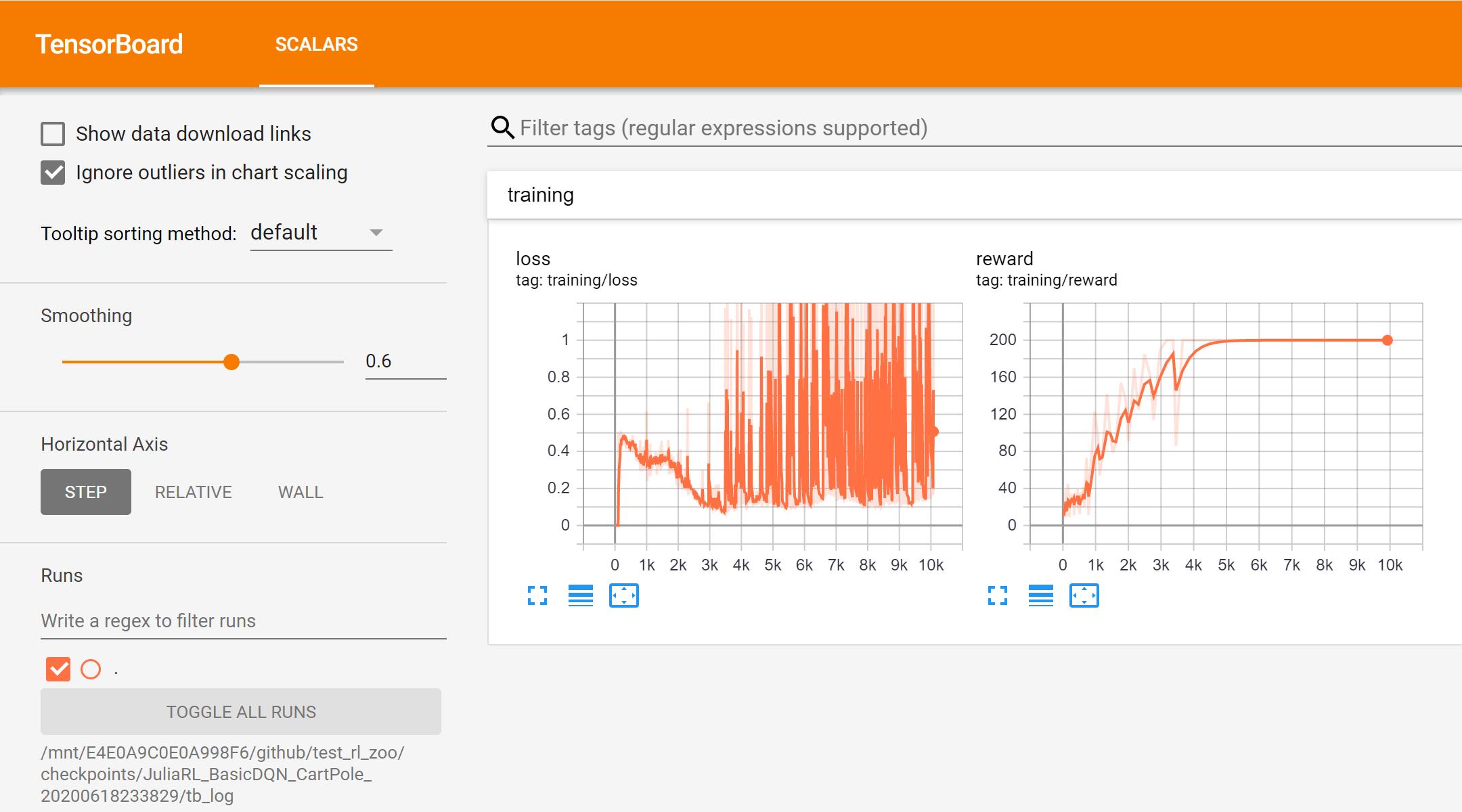
我们也可以尝试其他算法:
JuliaRL_BasicDQN_CartPole
JuliaRL_DQN_CartPole
JuliaRL_PrioritizedDQN_CartPole
JuliaRL_Rainbow_CartPole
JuliaRL_IQN_CartPole
JuliaRL_A2C_CartPole
JuliaRL_A2CGAE_CartPole
JuliaRL_PPO_CartPole
2. 组件介绍
主要是4个组件,定义在一个experiment中:
Agent
Environment
Hook
Stop Condition
执行
run(E`JuliaRL_BasicDQN_CartPole`)等价于执行
experiment = E`JuliaRL_BasicDQN_CartPole`
agent = experiment.agent
env = experiment.env
stop_condition = experiment.stop_condition
hook = experiment.hook
run(agent, env, stop_condition, hook)
详细的信息如下:
ReinforcementLearningCore.Experiment
├─ agent => ReinforcementLearningCore.Agent
│ ├─ policy => ReinforcementLearningCore.QBasedPolicy
│ │ ├─ learner => ReinforcementLearningZoo.BasicDQNLearner
│ │ │ ├─ approximator => ReinforcementLearningCore.NeuralNetworkApproximator
│ │ │ │ ├─ model => Flux.Chain
│ │ │ │ │ └─ layers
│ │ │ │ │ ├─ 1
│ │ │ │ │ │ └─ Flux.Dense
│ │ │ │ │ │ ├─ W => 128×4 Array{Float32,2}
│ │ │ │ │ │ ├─ b => 128-element Array{Float32,1}
│ │ │ │ │ │ └─ σ => typeof(NNlib.relu)
│ │ │ │ │ ├─ 2
│ │ │ │ │ │ └─ Flux.Dense
│ │ │ │ │ │ ├─ W => 128×128 Array{Float32,2}
│ │ │ │ │ │ ├─ b => 128-element Array{Float32,1}
│ │ │ │ │ │ └─ σ => typeof(NNlib.relu)
│ │ │ │ │ └─ 3
│ │ │ │ │ └─ Flux.Dense
│ │ │ │ │ ├─ W => 2×128 Array{Float32,2}
│ │ │ │ │ ├─ b => 2-element Array{Float32,1}
│ │ │ │ │ └─ σ => typeof(identity)
│ │ │ │ └─ optimizer => Flux.Optimise.ADAM
│ │ │ │ ├─ eta => 0.001
│ │ │ │ ├─ beta
│ │ │ │ │ ├─ 1
│ │ │ │ │ │ └─ 0.9
│ │ │ │ │ └─ 2
│ │ │ │ │ └─ 0.999
│ │ │ │ └─ state => IdDict
│ │ │ │ ├─ ht => 32-element Array{Any,1}
│ │ │ │ ├─ count => 0
│ │ │ │ └─ ndel => 0
│ │ │ ├─ loss_func => typeof(ReinforcementLearningCore.huber_loss)
│ │ │ ├─ γ => 0.99
│ │ │ ├─ batch_size => 32
│ │ │ ├─ min_replay_history => 100
│ │ │ ├─ rng => Random.MersenneTwister
│ │ │ └─ loss => 0.0
│ │ └─ explorer => ReinforcementLearningCore.EpsilonGreedyExplorer
│ │ ├─ ϵ_stable => 0.01
│ │ ├─ ϵ_init => 1.0
│ │ ├─ warmup_steps => 0
│ │ ├─ decay_steps => 500
│ │ ├─ step => 1
│ │ ├─ rng => Random.MersenneTwister
│ │ └─ is_training => true
│ ├─ trajectory => ReinforcementLearningCore.CombinedTrajectory
│ │ ├─ reward => 0-element ReinforcementLearningCore.CircularArrayBuffer{Float32,1}
│ │ ├─ terminal => 0-element ReinforcementLearningCore.CircularArrayBuffer{Bool,1}
│ │ ├─ state => 4×0 view(::ReinforcementLearningCore.CircularArrayBuffer{Float32,2}, :, 1:0) with eltype Float32
│ │ ├─ next_state => 4×0 view(::ReinforcementLearningCore.CircularArrayBuffer{Float32,2}, :, 2:1) with eltype Float32
│ │ ├─ full_state => 4×0 view(::ReinforcementLearningCore.CircularArrayBuffer{Float32,2}, :, 1:0) with eltype Float32
│ │ ├─ action => 0-element view(::ReinforcementLearningCore.CircularArrayBuffer{Int64,1}, 1:0) with eltype Int64
│ │ ├─ next_action => 0-element view(::ReinforcementLearningCore.CircularArrayBuffer{Int64,1}, 2:1) with eltype Int64
│ │ └─ full_action => 0-element view(::ReinforcementLearningCore.CircularArrayBuffer{Int64,1}, 1:0) with eltype Int64
│ ├─ role => DEFAULT_PLAYER
│ └─ is_training => true
├─ env => ReinforcementLearningEnvironments.CartPoleEnv: ReinforcementLearningBase.SingleAgent(),ReinforcementLearningBase.Sequential(),ReinforcementLearningBase.PerfectInformation(),ReinforcementLearningBase.Deterministic(),ReinforcementLearningBase.StepReward(),ReinforcementLearningBase.GeneralSum(),ReinforcementLearningBase.MinimalActionSet(),ReinforcementLearningBase.Observation{Array}()
├─ stop_condition => ReinforcementLearningCore.StopAfterStep
│ ├─ step => 10000
│ ├─ cur => 1
│ └─ progress => ProgressMeter.Progress
├─ hook => ReinforcementLearningCore.ComposedHook
│ └─ hooks
│ ├─ 1
│ │ └─ ReinforcementLearningCore.TotalRewardPerEpisode
│ │ ├─ rewards => 0-element Array{Float64,1}
│ │ └─ reward => 0.0
│ ├─ 2
│ │ └─ ReinforcementLearningCore.TimePerStep
│ │ ├─ times => 0-element ReinforcementLearningCore.CircularArrayBuffer{Float64,1}
│ │ └─ t => 832228407951
│ ├─ 3
│ │ └─ ReinforcementLearningCore.DoEveryNStep
│ │ ├─ f => ReinforcementLearningZoo.var"#136#141"
│ │ ├─ n => 1
│ │ └─ t => 0
│ ├─ 4
│ │ └─ ReinforcementLearningCore.DoEveryNEpisode
│ │ ├─ f => ReinforcementLearningZoo.var"#138#143"
│ │ ├─ n => 1
│ │ └─ t => 0
│ └─ 5
│ └─ ReinforcementLearningCore.DoEveryNStep
│ ├─ f => ReinforcementLearningZoo.var"#140#145"
│ ├─ n => 10000
│ └─ t => 0
└─ description => " This experiment uses three dense layers to approximate the Q value...
2.1 Agent
Agent接收env,返回action。
数据结构上,主要包含两部分:Policy和Trajectory。Policy实现接收env返回action的功能,Trajectory用来记录数据,并在合适的时候更新策略。来看一个例子
using ReinforcementLearning
using Random
using Flux
rng = MersenneTwister(123) # 这就是个随机数发生器
env = CartPoleEnv(;T = Float32, rng = rng) # 需要定义记录的数据格式
ns, na = length(get_state(env)), length(get_actions(env))
agent = Agent(
policy = QBasedPolicy(
learner = BasicDQNLearner(
approximator = NeuralNetworkApproximator(
model = Chain(
Dense(ns, 128, relu; initW = glorot_uniform(rng)),
Dense(128, 128, relu; initW = glorot_uniform(rng)),
Dense(128, na; initW = glorot_uniform(rng)),
) |> cpu,
optimizer = ADAM(),
),
batch_size = 32,
min_replay_history = 100,
loss_func = huber_loss,
rng = rng,
),
explorer = EpsilonGreedyExplorer(
kind = :exp,
ϵ_stable = 0.01,
decay_steps = 500,
rng = rng,
),
),
trajectory = CircularCompactSARTSATrajectory(
capacity = 1000,
state_type = Float32,
state_size = (ns,),
),
)
2.1.1 Policy
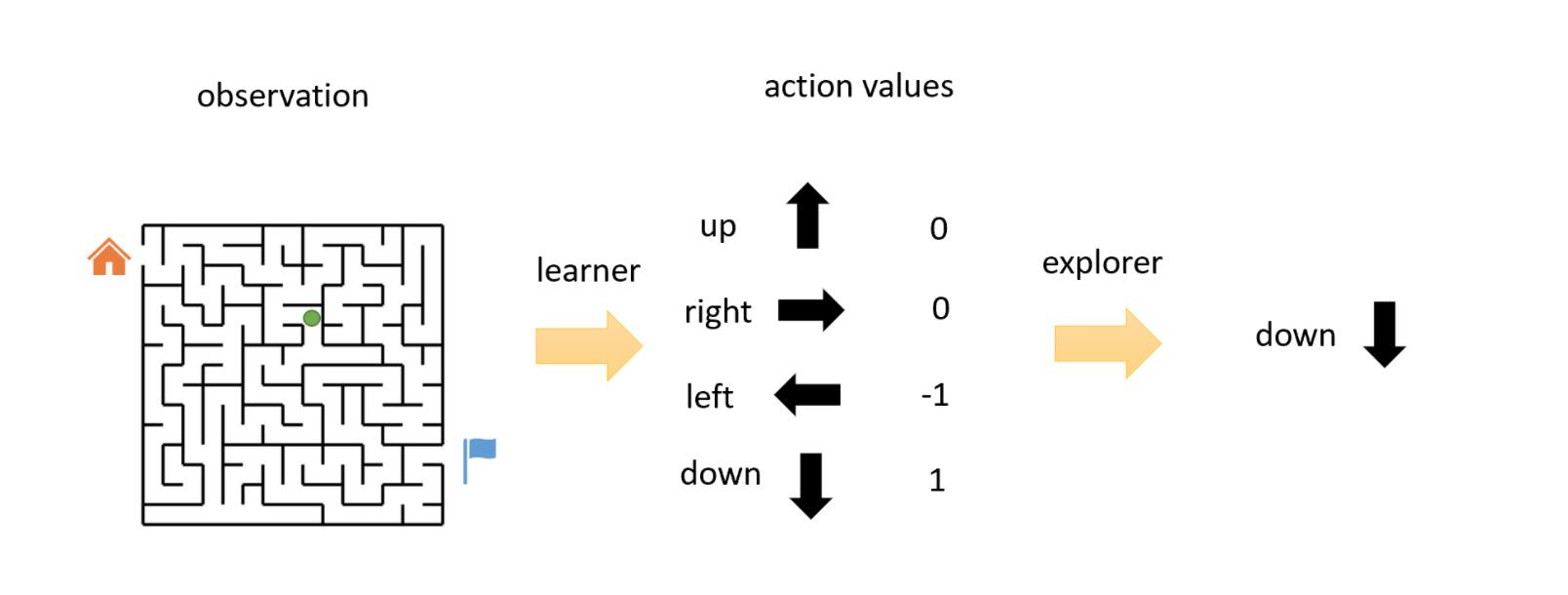
最简单的策略莫过于random policy了,然后还有QBasedPolicy,需要一个映射函数叫Q-learner去计算每一个action的value,然后有一个explorer会以一定概率去探索效果不好的action。
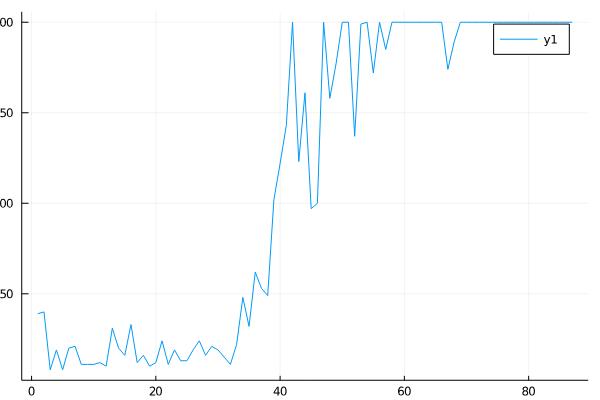
我们可以修改Policy的参数,然后绘制图形看变化:
using Plots
experiment = E`JuliaRL_BasicDQN_CartPole`
experiment.agent.policy.learner.γ = 0.98
hook = TotalRewardPerEpisode()
run(experiment.agent, experiment.env, experiment.stop_condition, hook)
plot(hook.rewards)
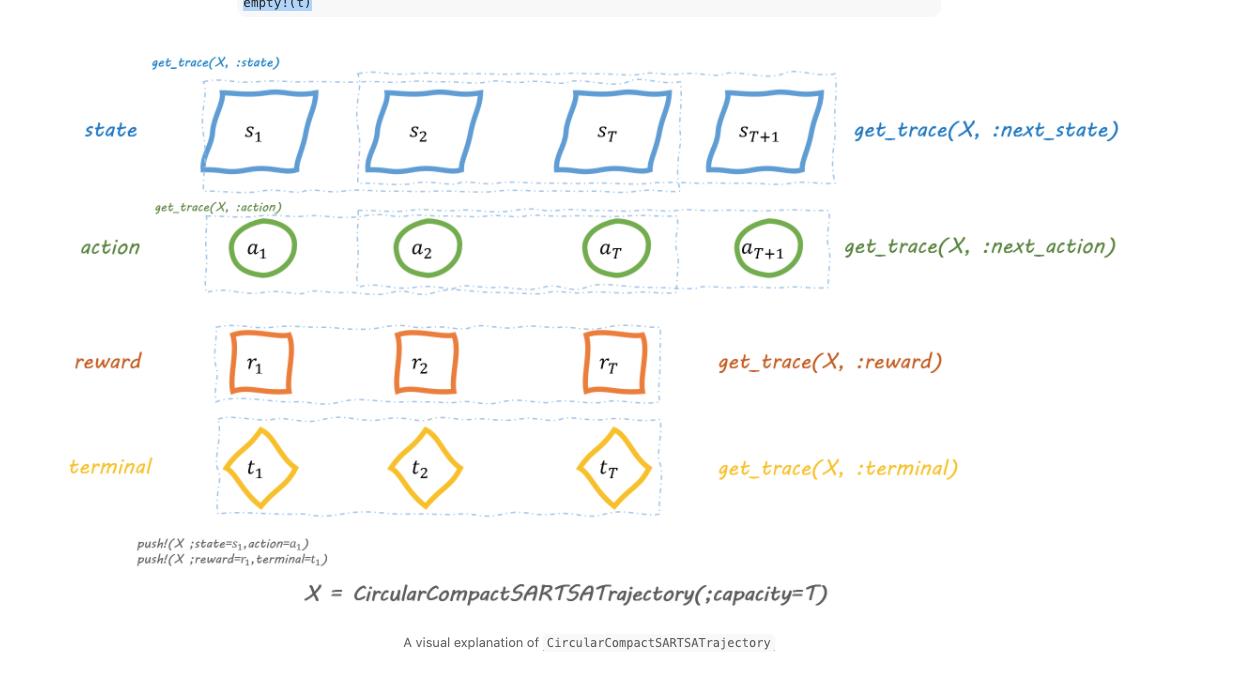
2.1.2 Trajectory
t = CircularCompactSARTSATrajectory(;capacity=3)
push!(t; state=1, action=1, reward=0., terminal=false, next_state=2, next_action=2)
get_trace(t, :state)
empty!(t)
下面是图示:
2.2 Environment
Env中需要定义获取state、reward和终止的函数:
reset!(env) # reset env to the initial state
get_state(env) # get the state from environment, usually it's a tensor
get_reward(env) # get the reward since last interaction with environment
get_terminal(env) # check if the game is terminated or not
env(rand(get_actions(env))) # feed a random action to the environment
下面是CartPoleEnv的介绍:
# ReinforcementLearningEnvironments.CartPoleEnv
## Traits
| Trait Type | Value |
|:----------------- | ----------------------------------------------:|
| NumAgentStyle | ReinforcementLearningBase.SingleAgent() |
| DynamicStyle | ReinforcementLearningBase.Sequential() |
| InformationStyle | ReinforcementLearningBase.PerfectInformation() |
| ChanceStyle | ReinforcementLearningBase.Deterministic() |
| RewardStyle | ReinforcementLearningBase.StepReward() |
| UtilityStyle | ReinforcementLearningBase.GeneralSum() |
| ActionStyle | ReinforcementLearningBase.MinimalActionSet() |
| DefaultStateStyle | ReinforcementLearningBase.Observation{Array}() |
## Actions
ReinforcementLearningBase.DiscreteSpace{UnitRange{Int64}}(1:2)
## Players
* `DEFAULT_PLAYER`
## Current Player
`DEFAULT_PLAYER`
## Is Environment Terminated?
No
2.3 Hook
hook用来收集实验数据、修改agent和env的参数。下面是常用的两个hook:
experiment = E`JuliaRL_BasicDQN_CartPole`
hook = TotalRewardPerEpisode()
run(experiment.agent, experiment.env, experiment.stop_condition, hook)
plot(hook.rewards)
2.3.1 自定义hook
DoEveryNStep() do t, agent, env
with_logger(lg) do
@info "training" loss = agent.policy.learner.loss
end
end
2.4 Stop condition
两个常用的停止条件为StopAfterStep和StopAfterEpisode
3. 自定义例子
运行的代码为:
run(agent,
env,
stop_condition
DoEveryNStep(EVALUATION_FREQ) do t, agent, env
Flux.testmode!(agent)
run(agent, env, eval_stop_condition, eval_hook)
Flux.trainmode!(agent)
end)
我们这里举一个例子,买彩票的蒙特卡洛树搜索
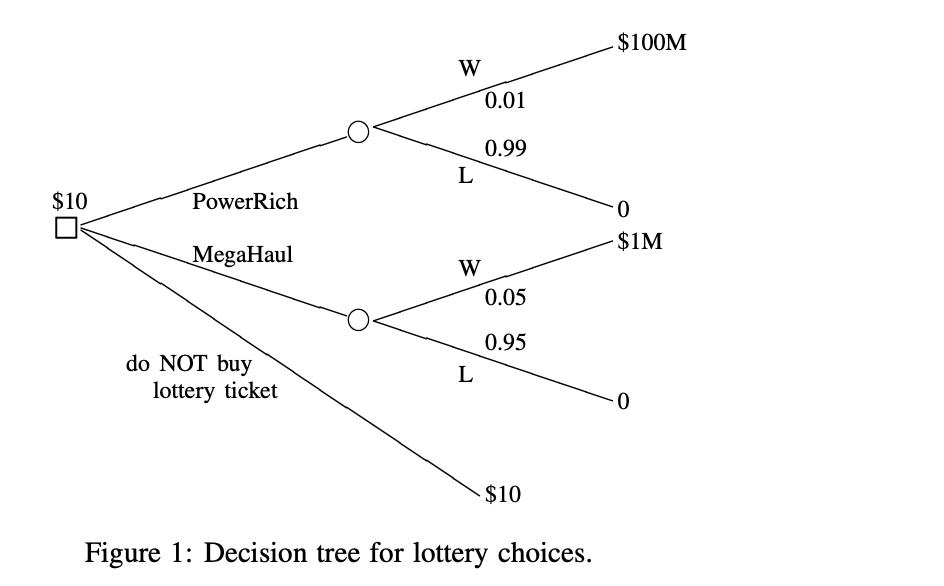
3.1 需要定义的内容
get_actions(env::YourEnv)
get_state(env::YourEnv)
get_reward(env::YourEnv)
get_terminal(env::YourEnv)
reset!(env::YourEnv)
(env::YourEnv)(action)
3.2 定义env
using ReinforcementLearning
mutable struct LotteryEnv <: AbstractEnv
reward::Union{Nothing, Int}
end
# 下面是需要实现的方法,RL.Base是ReinforcementLearningBase的缩写
# 对架构中的方法进行了封装,因此能看到调用reward获取env.reward的操作
# 需要定义完框架后才能去定义env
RLBase.get_actions(env::LotteryEnv) = (:PowerRich, :MegaHaul, nothing)
RLBase.get_reward(env::LotteryEnv) = env.reward
RLBase.get_state(env::LotteryEnv) = !isnothing(env.reward)
RLBase.get_terminal(env::LotteryEnv) = !isnothing(env.reward)
RLBase.reset!(env::LotteryEnv) = env.reward = nothing
# 定义policy,接受action,设置reward
function (env::LotteryEnv)(action)
action = e
if action == :PowerRich
env.reward = rand() < 0.01 ? 100_000_000 : -10
elseif action == :MegaHaul
env.reward = rand() < 0.05 ? 1_000_000 : -10
else
env.reward = 0
end
end
env = LotteryEnv(nothing)
返回
## Traits
| Trait Type | Value |
|:----------------- | --------------------:|
| NumAgentStyle | SingleAgent() |
| DynamicStyle | Sequential() |
| InformationStyle | PerfectInformation() |
| ChanceStyle | Deterministic() |
| RewardStyle | StepReward() |
| UtilityStyle | GeneralSum() |
| ActionStyle | MinimalActionSet() |
| DefaultStateStyle | Observation{Array}() |
## Actions
(:PowerRich, :MegaHaul, nothing)
## Players
* `DEFAULT_PLAYER`
## Current Player
`DEFAULT_PLAYER`
## Is Environment Terminated?
No
接着来测试运行一下
hook = TotalRewardPerEpisode()
run(
Agent(
;policy = RandomPolicy(env),
trajectory = VectCompactSARTSATrajectory(
state_type=Bool,
action_type=Any,
reward_type=Int,
terminal_type=Bool,
),
),
LotteryEnv(),
StopAfterEpisode(1_000),
hook
)
TotalRewardPerEpisode([-10.0, -10.0, -10.0, -10.0, -10.0, 0.0, 1.0e8, -10.0, -10.0, -10.0 … -10.0, -10.0, 0.0, -10.0, 0.0, 0.0, -10.0, -10.0, -10.0, 0.0], 0.0)
println(sum(hook.rewards) / 1_000)
14993.58
以上是关于深度强化学习 如何训练的主要内容,如果未能解决你的问题,请参考以下文章
1个GPU几分钟搞定强化学习训练,谷歌新引擎让深度学习提速1000倍丨开源
百度正式发布PaddlePaddle深度强化学习框架PARL
深度强化学习的实操 动作空间状态空间回报函数的设计以及算法选择训练调试和性能冲刺