1个GPU几分钟搞定强化学习训练,谷歌新引擎让深度学习提速1000倍丨开源
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了1个GPU几分钟搞定强化学习训练,谷歌新引擎让深度学习提速1000倍丨开源相关的知识,希望对你有一定的参考价值。
博雯 发自 凹非寺
量子位 报道 | 公众号 QbitAI
机器人要如何完成这样一个动作?

我们一般会基于强化学习,在仿真环境中进行模拟训练。
这时,如果在一台机器的CPU环境下进行模拟训练,那么需要几个小时到几天。
但现在,只需一个TPU/GPU,就能和数千个CPU或GPU的计算集群的速度一样快,直接将所需时间缩短到几分钟!
相当于将强化学习的速度提升了1000倍!
这就是来自谷歌的科学家们开发的物理模拟引擎Brax。

三种策略避免逻辑分支
现在大多数的物理模拟引擎都是怎么设计的呢?
将重力、电机驱动、关节约束、物体碰撞等任务都整合在一个模拟器中,并行地进行多个模拟,以此来逼近现实中的运动系统。
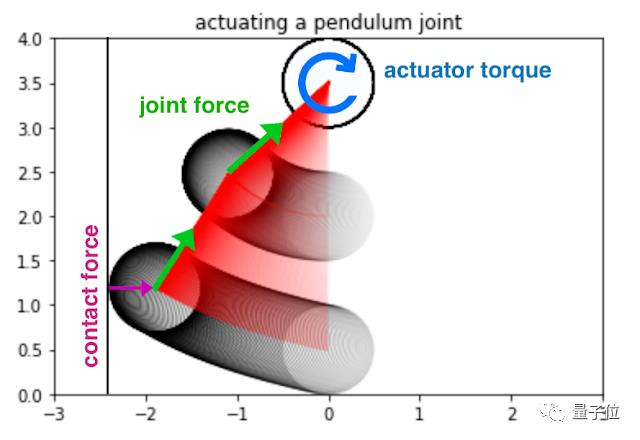
△对于每个模拟时间步长,力和力矩被整合在一起
这种情况下,每个模拟器中的计算都不相同,且数据必须在数据中心内通过网络传输。
这种并行布局也就导致了较高的延迟时间——即学习者可能需要超过10000纳秒的等待时间,才能从模拟器中获得经验。
那么怎样才能缩短这种延迟时间呢?
Brax选择通过避免模拟中的分支来保证数千个并行环境中的计算完全统一,进而降低整个训练架构的复杂度。
直到复杂度降低到可以在单一的TPU或GPU上执行,跨机器通信的计算开销就随之降低,延迟也就能被有效消除。

主要分为以下三个方法:
连续函数替换离散分支逻辑
比如,在计算一个小球与墙壁之间的接触力时,就产生了一个分支:
如果球接触墙壁,就执行模拟球从墙壁反弹的独立代码;
否则,就执行其他代码;
这里就可以通过符号距离函数来避免这种if/else的离散分支逻辑的产生。
使用JAX即时编译中评估分支
在仿真时间之前评估基于环境静态属性的分支,例如两个物体是否有可能发生碰撞。
在模拟中只选择需要的分支结果
在使用了这三种策略之后,我们就得到了一个模拟由刚体、关节、执行器组成环境的物理引擎。
同时也是一种实现在这种环境中各类操作(如进化策略,直接轨迹优化等)的学习算法。
那么Brax的性能究竟如何呢?
速度最高提升1000倍
Brax测试所用的基准是OpenAI Gym中Ant、HalfCheetah、Humanoid、Reacher四种。
同时也增加了三个新环境:包括对物理的灵巧操作、通用运动(例如前往周围任何一个放置了物体的地点)、以及工业机器人手臂的模拟:



研究人员首先测试了Brax在并行模拟越来越多的环境时,可以产生多少次物理步骤(也即对环境状态的更新)。
测试结果中的TPUv3 8x8曲线显示,Brax可以在多个设备之间进行无缝扩展,每秒可达到数亿个物理步骤:

而不仅是在TPU上,从V100和P100曲线也能看出,Brax在高端GPU上同样表现出色。
然后就是Brax在单个工作站(workstation)上运行一个强化学习实验所需要的时间。
在这里,研究人员将基于Ant基准环境训练的Brax引擎与MuJoCo物理引擎做了对比:
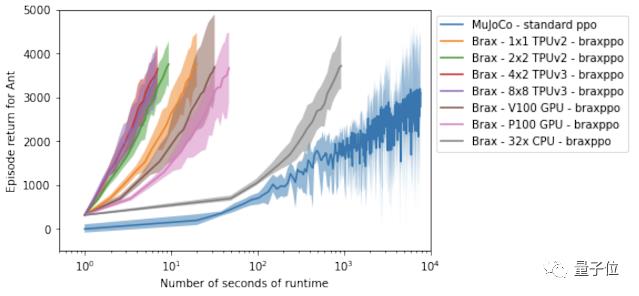
可以看到,相对于MuJoCo(蓝线)所需的将近3小时时间,使用了Brax的加速器硬件最快只需要10秒。
使用Brax,不仅能够提高单核训练的效率,还可以扩展到大规模的并行模拟训练。
论文地址:
https://arxiv.org/abs/2106.13281
下载:
https://github.com/google/brax
参考链接:
https://ai.googleblog.com/2021/07/speeding-up-reinforcement-learning-with.html
以上是关于1个GPU几分钟搞定强化学习训练,谷歌新引擎让深度学习提速1000倍丨开源的主要内容,如果未能解决你的问题,请参考以下文章