Presto on Yarn在易果大数据平台实践
Posted 易果数据技术部
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Presto on Yarn在易果大数据平台实践相关的知识,希望对你有一定的参考价值。
一.平台部署实践
易果大数据平台上线已经一年多,数据存储采用HDFS,Yarn组件做为集群资源管理器,离线计算主要采用Hive和Sparksql,实时计算采用SparkStreaming,即席查询采用Presto,同时对Presto做了二次开发,以满足我们域帐号认证,以及表级,列级数据权限管理的要求。 由于B/S架构的Presto查询工具(例如:Superset)在数据量大和高并发的情况下会导致OOM, 影响使用者体验,故选择了C/S 架构的Dbvisualizer作为我们的Client端,如下图
由于上线初期,Presto没有加入到Yarn调度,随着业务量的巨增,使用人数的增长,会出现某个大查询占用全部资源,其他查询任务无法提交的情况,极大影响使用者的工作效率,这急需一个资源隔离解决方案,通过调研,我们准备使用Presto on Yarn,官网解决方案是可以用Slider把Presto部署到Yarn上,但是国内还没有使用这个方案的公司,网上也没有相关实践经验,所以我们只能从官网文档入手,把Presto成功部署到Yarn上,步骤如下:
(1)在conf/slider-client.xml中配置参数如下:

(2)在Yarn集群各个节点上创建Presto涉及到的目录并赋予权限,目录参考appConfig.json中site.global.app_user定义的,创建目录命令如下:
mkdir -p /var/lib/presto/data
chown -R yarn:yarn /var/lib/presto/data
(3)运行 Slider:
bin/slider package --install --namePRESTO --package /opt/presto-yarn/presto-yarn.zip
bin/slider create presto_web --template/opt/presto-yarn/resources/appConfig.json --resources/opt/presto-yarn/resources-multinode.json --queue presto_web
(4)在Yarn集群节点用Jps命令查看Presto进程是否存在,如果在表示部署成功。
部署成功后,我们发现Yarn每次在重启时候,Coordinator节点会飘,官方的解决方案是在Hadoop节点上打Label,但目前只有Capacity Scheduler模式适合打Label,而我们是采用Fair Scheduler模式,所以只能想其他的解决方案。我们搜索业界的解决方法,也有公司通过分离Discovery Server来实现固定Coordinator,就是在外部的Discovery Server上启动Coordinator,但这种方法侵入性比较大,所以不太推荐。
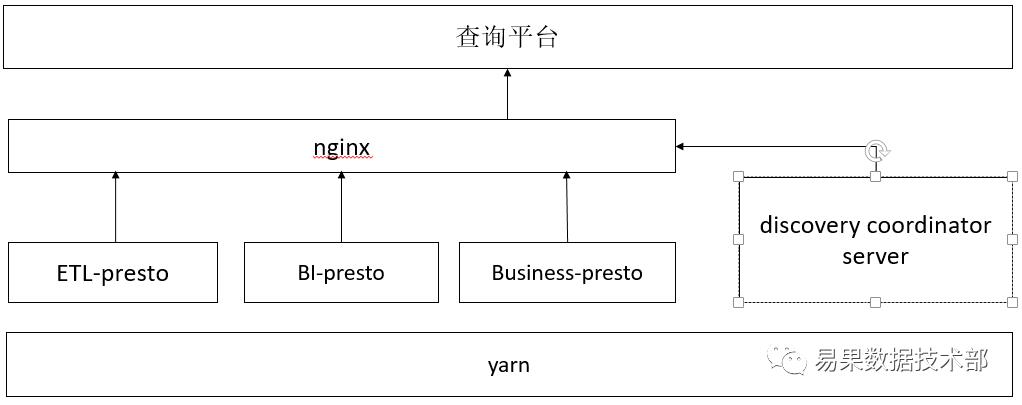
经过大家讨论,我们自己开发实现一个服务发现功能,如下图中Discovery Coordinator Server,原理是通过nginx代理方式,定期的从Yarn上获取Coordinator节点IP,然后修改Nginx Conf文件,最后Reload Nginx,这样暴露给前端的只有Nginx代理IP,如下图。同时因为Presto资源是常驻在Yarn上,为了做到资源弹性管理,我们在晚上23点会通过Slider Flex动态调整资源,以让出更多资源给晚上离线计算任务,同时又在早8点恢复资源给Presto即席查询任务。
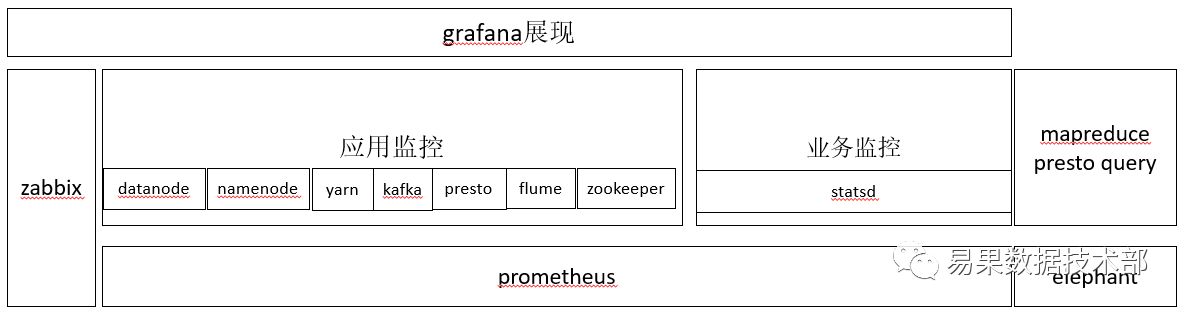
三军未动,粮草先行,对于任何Online系统,我们首先要做好监控,监控不仅是为了系统稳定运行,而且还是我们了解系统内部健康情况,针对集群资源使用监控,Presto监控有两种方案,一是对Dr.elephant进行二次开发监控每个查询的Sql性能,主要是分析Sql使用的资源情况,如果严重耗资源Sql,我们会打上Label,为后期优化做准备,二是我们在Presto Client端上部署Jmx Export,在Promtheus Server端获取Presto Jmx各种数据,架构如下图
二.平台优化
Presto是我们第一次使用,难免会遇到某些坑,起初我们给了Presto 的jvm=40G,query.max-memory-per-node=20G,想当然的以为内存已经很大了,其实不然,线上使用的时候我们发现经常有很多的Query被 Block了,通过监控,如下图,发现三个pool的总使用内存没有20G,并且发现这个20G是Reservedpool中的内存,而且一直未用,反而General pool在频繁使用。
其实Presto有三个内存池分别是:Generalpool、Reserved pool、System pool中内存。默认Reserved pool大小是通过query.max-memory-per-node该参数设置,System pool大小默认是Jvm内存的40%,剩下就是General pool Memory = Jvm的MaxHeap – System Memeory – Reserved Memory当General pool中的Query blocked了,才会使用Reserved pool,而System pool是Presto自己使用的。但是如果想使用Reserved pool的条件还是比较苛刻,通过解读原码,如下图,可以看出Generalpool的Query被Blocked并且Reserved pool没有Biggest query占用时才会使用Reserved pool内存,所以基本上Query内存都是在General pool中,所以之前我们认为query.max-memory-per-node设置越大提供查询内存越大,根据我们的实践其实不太合理的,这个参数只保证单个节点的查询内存使用最大限制,所以还要充分利用集群资源还是要保留足够的General pool内存。
三.总结与展望
Presto自部署到Yarn几个月,一直运行稳定,资源争抢的问题已经基本得到解决。作为一款优秀的Ad-hoc查询引擎,Presto目前已经被各个公司应用于生产环境,但是相比Spark和Hive,其资源管理又相对薄弱,未来我们也将尝试Presto on K8s来加强Presto的资源管控。
文:李迅,罗瑞星 审核:周方军
以上是关于Presto on Yarn在易果大数据平台实践的主要内容,如果未能解决你的问题,请参考以下文章