EMR on ACK 全新发布,助力企业高效构建大数据平台
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了EMR on ACK 全新发布,助力企业高效构建大数据平台相关的知识,希望对你有一定的参考价值。
简介: 阿里云 EMR on ACK 为用户提供了全新的构建大数据平台的方式,用户可以将开源大数据服务部署在阿里云容器服务(ACK)上。利用 ACK 在服务部署和对高性能可伸缩的容器应用管理的能力优势,用户只需要专注在大数据作业本身。用户可以便捷地将 Spark、Presto、Flink 作业执行在 ACK 集群上,100%兼容开源,性能优于开源。
一、背景介绍
技术趋势
- 存储与计算分离,向云原生演进
- 在线业务、AI、大数据统一接入 ACK 集群,错峰调度,离线在线混部,提升机器利用率
- 统一运维入口,统一运维工具链,统一监控体系
- 以集群为中心->以作业为中心
- 多版本支持,例如可以同时跑 Spark2.x、Spark3.x
云原生面临挑战
- 计算与存储分离:如何构建以对象存储 OSS 为底座的 HCFS 文件系统
• 需要完全兼容现有的 HDFS
• 性能对标 HDFS,成本降低
- 计算引擎 shuffle 数据存算分离:如何解决 ACK 混合异构机型
• 异构机型没有本地盘
• 社区[ Spark-25299]讨论,支持 Spark 动态资源,成为业界共识
- ACK 调度能力:如何解决调度性能瓶颈
• 性能对标 Yarn
• 多级队列管理
- 错峰调度
• 借助 K8s 操作系统能力,编排组织各种业务的波峰波谷
EMR on ACK 优势
- Remote Shuffle Service 提供中间 shuffle 数据的存储计算分离方案
• 可以使计算节点无需本地盘和云盘
• 支持打开 Spark 动态资源功能,Spark-25299 终极方案
- JindoFS 针对 OSS 存储提供湖加速解决方案
• Block 模式1TB TPCDS 场景下有15%以上的性能提升
- 调度层面支持 Scheduler Framework V2
• 调度性能比社区提升3x以上
• 提供多级队列管理
- 引擎能力增强
• 10TB TPCDS Benchmark 场景下,EMR Spark 比社区有3x性能提升
• Hudi、DeltaLake 比社区功能性能增强
- 完整的错峰调度方案
二、EMR 容器化架构
EMR on ACK 架构
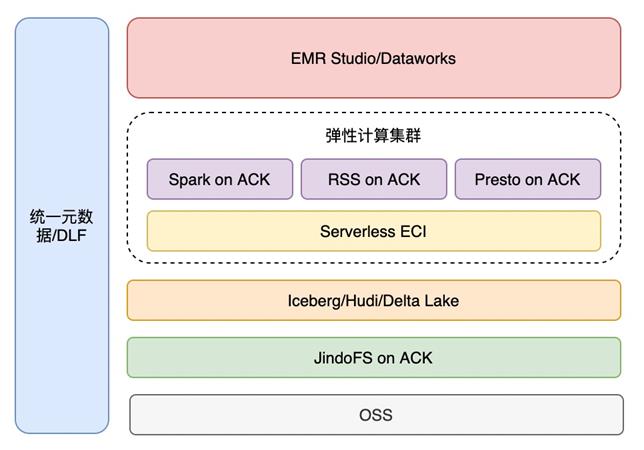
- 轻量化管控,对接已有数据平台
- 通过数据开发集群/调度平台提交到不同的执行平台
- 错峰调度,根据业务高峰低峰策略调整
- 云原生数据湖架构,ACK 弹性扩缩容能力强
- ACK 管理异构机型集群,灵活性好
三、产品介绍
产品首页
参考链接:https://www.aliyun.com/product/emapreduce
EMR on ACK Beta 版,前往体验>>

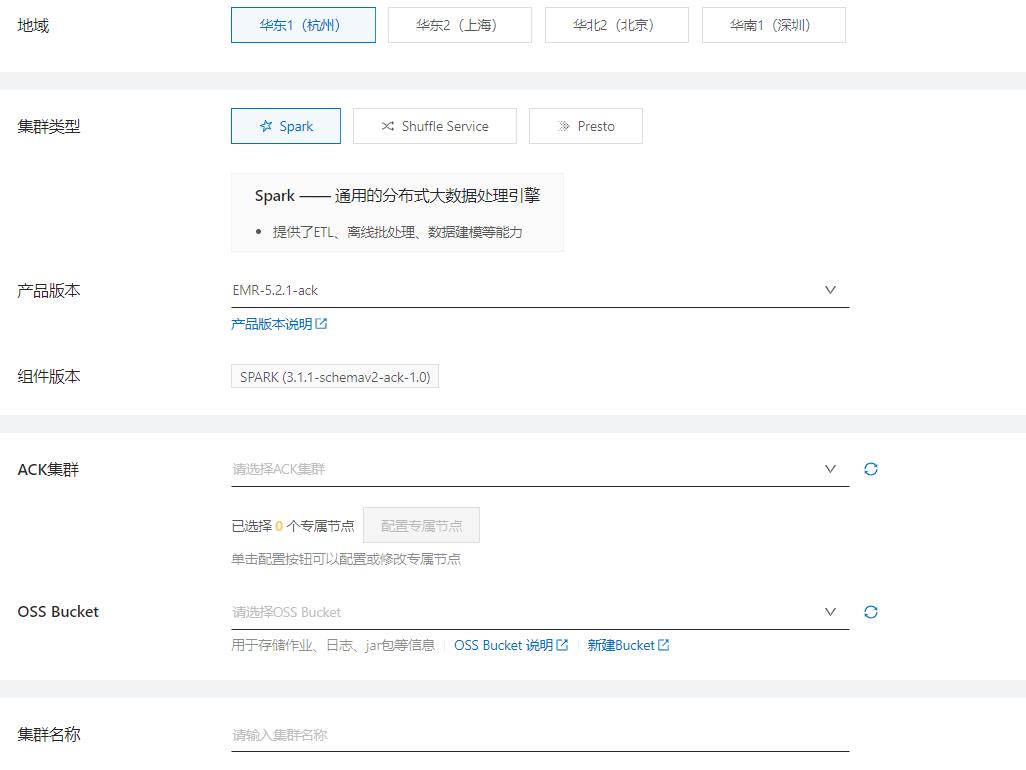
新建集群
- 地域:目前开放杭州、上海、北京、深圳等地域(持续开放中)
- 集群类型:Spark 、Shuffle Service、Presto
- Spark — 通用的分布式大数据处理引擎
• 提供了 ETL、离线批处理、数据建模等能力
- Shuffle Service — 针对 EMR 计算引擎提供优化的 Shuffle 服务
• 解决 Kubernetes 下对本地盘的依赖问题
• 解决大规模计算集群的网络和磁盘的 IO 瓶颈
• 支持计算与存储分离的架构,可服务多个 EMR 集群
- Presto — 基于内存的分布式 SQL 交互式查询引擎
• 支持多种数据源
• 适合 PB 级海量数据的复杂分析,以及跨数据源的查询
- 组件版本:Spark (3.1.1)
- 专属节点:
• 现有 ACK 集群,share 部分节点给到 EMR
• 新建 ACK 集群,可选择整个集群为专属节点
- OSS Bucket:用于存储作业、日志、jar 包等信息
集群管理
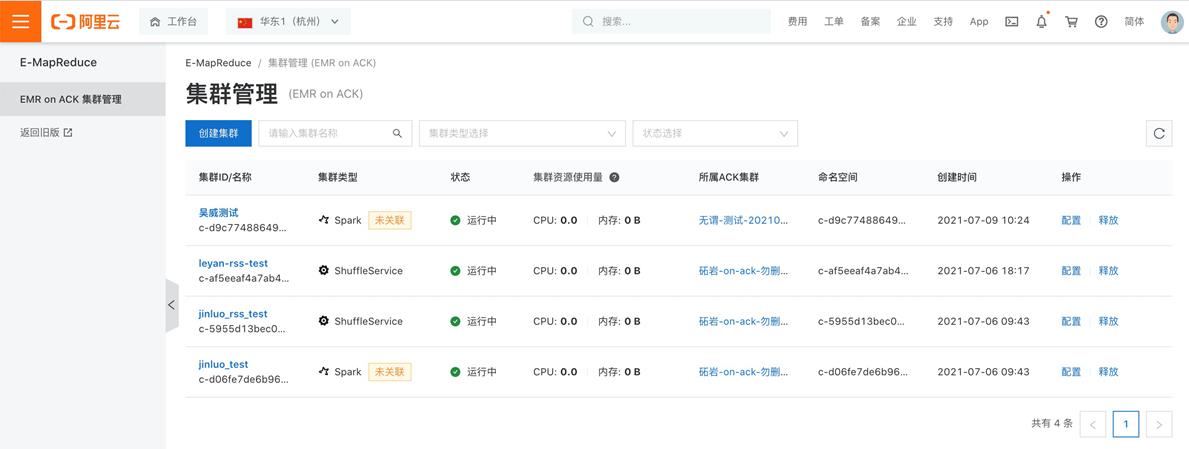
- 集群 ID/名称:点击进入作业管理
- 集群状态:检测集群是否可用
- 所属 ACK 集群:可关联到现有 ACK 集群
- 配置:Spark 作业配置
- 释放:释放空间
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于EMR on ACK 全新发布,助力企业高效构建大数据平台的主要内容,如果未能解决你的问题,请参考以下文章
阿里大数据云原生化实践,EMR Spark on ACK 产品介绍