大数据平台建设 —— SQL查询引擎之Presto
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据平台建设 —— SQL查询引擎之Presto相关的知识,希望对你有一定的参考价值。
大数据查询引擎Presto简介
SQL on Hadoop:
- Hive的出现让技术人员可以通过类SQL的方式对批量数据进行查询,而不用开发MapReduce程序
- MapReduce计算过程中大量的中间结果磁盘落地使运行效率较低
- 为了提高SQL on Hadoop的效率,各大工具应运而生,比如Shark、Impala等
SQL on Hadoop的常见工具:
Presto是什么:
- Presto是由Facebook开发的分布式SQL查询引擎,用来进行高速实时的数据分析
- Presto的产生是为了解决Hive的MapReduce模型太慢且不能通过BI等工具展现HDFS数据的问题
- Presto是一个计算引擎,它不存储数据,通过丰富的Connector获取第三方服务的数据,并支持扩展
Presto显而易见的优点:
- Presto支持标准的SQL,降低了分析人员和开发人员的使用门槛
- Presto支持可插拔的Connector,可以连接多种数据源。包括HiveRDBMS、Kafka、 MongoDB等等
- Presto是一个低延时、高并发的内存计算引擎,比Hive执行效率高的多
Presto数据模型:
- Catalog:即数据源。Hive、 Mysq|都 是数据源。Presto可 以连接多个Hive和多个mysql。
- Schema:类比于DataBase,一个Catalog下有多个Schema
- Table:数据表,与我们常用的数据库表意义相同,一个Schema下有多个数据表
Presto架构与执行流程
Presto架构图: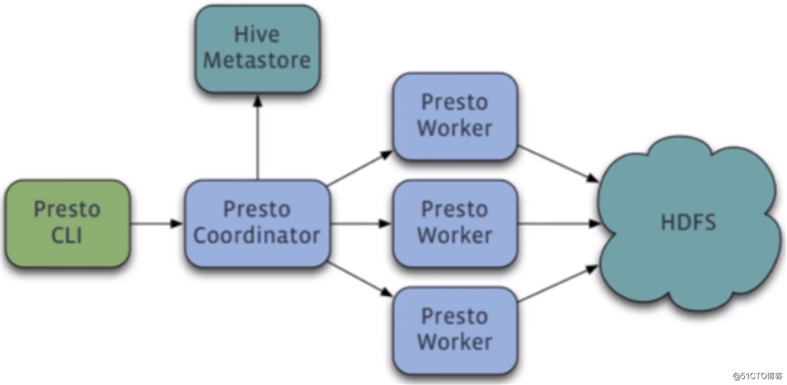
Presto为Master - Slave架构,由三部分组成:
- 一个Coordinator节点
- 一个Discovery Server节点
- 多个Worker节点
Presto组件:
- Coordinator负责解析SQL语句,生成查询计划,分发执行任务
- Discovery Server负责维护Coordinator和Worker的关系,通常内嵌于Coordinator节点
- Worker节点负责执行查询任务以及与HDFS进行交互读取数据
Presto查询流程: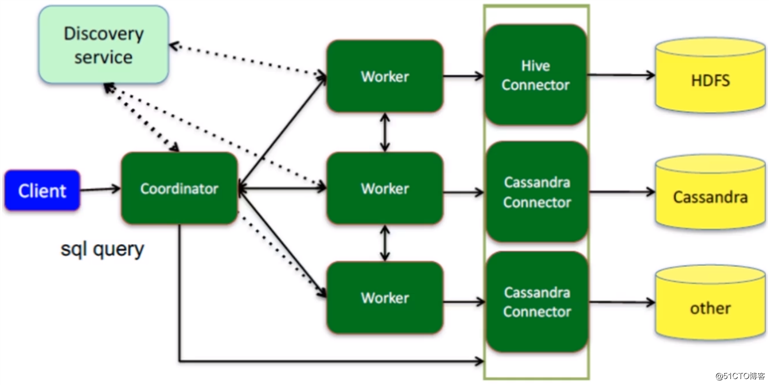
Presto的一些名词:
- Plan:Presto将需要执行的SQL进行解析,生成执行计划
- Stage:Presto执行计划分 为多个Stage,比如读取数据、聚合数据等
- Exchange:用于连接不同的Stage,进行数据交互
- Task:Stage由多个Task组成,每个Task分配到 一个Worker执行
- Split:一个分片表示大的数据集合中的一个小子集,与MapReduce类似
- Page:Presto 中处理的最小数据单元
关于数据库架构设计:
- Shared Everthting:完全透明共享CPU/MEMORY/IO,并行处理能力是最差的
- Shared Storage:各个处理单元使用自己的私有CPU和Memory,共享磁盘系统
- Shared Nothing:各个处理单元都有自己私有的CPU/内存/硬盘等
Presto属于MPP架构设计: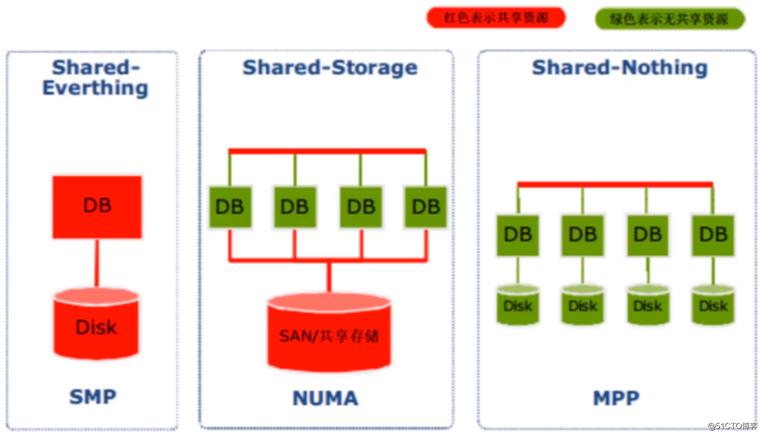
MPP架构的优缺点
- 易扩容:可轻松通过扩展机器节点(处理单元)扩展整个系统的分布式存储和计算能力
- 效率高:任务并行执行能力强,充分发挥本地计算的能力,数据无共享、无I/O冲突,无锁资源竞争,计算速度快
- 短板效应:单个节点查询效率慢会影响整个查询
Presto安装部署
官方文档:
Presto的安装方式有两种,一是到官网下载编译好的二进制包进行安装,二是从Github仓库上拉取源码进行编译安装。为了简单起见,我这里选择第一种方式,Server和Client都需要下载。
将下载的安装包上传到服务器上:
[root@hadoop ~]# cd /usr/local/src
[root@hadoop /usr/local/src]# ls
presto-server-0.243.2.tar.gz presto-cli-0.243.2-executable.jar
[root@hadoop /usr/local/src]# 解压presto-server安装包,并移动到合适的目录下:
[root@hadoop /usr/local/src]# tar -zxvf presto-server-0.243.2.tar.gz
[root@hadoop /usr/local/src]# mv presto-server-0.243.2 /usr/local/presto-server
[root@hadoop /usr/local/src]# cd /usr/local/presto-server/
[root@hadoop /usr/local/presto-server]# ls
bin lib NOTICE plugin README.txt
[root@hadoop /usr/local/presto-server]# 配置presto-server:
[root@hadoop /usr/local/presto-server]# mkdir etc
[root@hadoop /usr/local/presto-server]# vim etc/config.properties
# 作为coordinator节点
coordinator=true
# 指定即是coordinator也是work节点
node-scheduler.include-coordinator=true
http-server.http.port=9090
# 是否使用内嵌的discovery-server
discovery-server.enabled=true
discovery.uri=http://192.168.243.161:9090
[root@hadoop /usr/local/presto-server]# vim etc/node.properties # 每个节点的特殊配置
# presto集群的名称
node.environment=presto_dev
# 当前节点的id
node.id=ffffffff-ffff-ffff-ffff-ffffffffff01
# 节点的数据存储目录
node.data-dir=/data/presto
[root@hadoop /usr/local/presto-server]# vim etc/jvm.config # JVM相关配置
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
[root@hadoop /usr/local/presto-server]# vim etc/log.properties # 日志相关配置
com.facebook.presto=INFO配置catalog的连接信息:
[root@hadoop /usr/local/presto-server]# mkdir etc/catalog
[root@hadoop /usr/local/presto-server]# vim etc/catalog/jmx.properties
connector.name=jmx
[root@hadoop /usr/local/presto-server]# vim etc/catalog/hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://192.168.243.161:9083
hive.config.resources=/usr/local/hadoop-2.8.5/etc/hadoop/hdfs-site.xml,/usr/local/hadoop-2.8.5/etc/hadoop/core-site.xml
hive.allow-drop-table=false完成以上的配置后,启动presto-server:
[root@hadoop /usr/local/presto-server]# bin/launcher run
...
2020-11-16T16:55:35.776+0800 INFO main com.facebook.presto.server.PrestoServer ======== SERVER STARTED ========以上这种启动方式是前台启动,后台启动的方式如下:
[root@hadoop /usr/local/presto-server]# bin/launcher start
Started as 5908
[root@hadoop /usr/local/presto-server]# 检查presto-server进程是否正常:
[root@hadoop /usr/local/presto-server]# jps |grep -i presto
5908 PrestoServer
[root@hadoop /usr/local/presto-server]# netstat -lntp |grep 5908
tcp6 0 0 :::39225 :::* LISTEN 5908/java
tcp6 0 0 :::42622 :::* LISTEN 5908/java
tcp6 0 0 :::9090 :::* LISTEN 5908/java
tcp6 0 0 :::36714 :::* LISTEN 5908/java
tcp6 0 0 :::45066 :::* LISTEN 5908/java
tcp6 0 0 :::32982 :::* LISTEN 5908/java
[root@hadoop /usr/local/presto-server]# 将presto-client的jar包移动到bin目录下:
[root@hadoop /usr/local/presto-server]# mv /usr/local/src/presto-cli-0.243.2-executable.jar bin/presto-cli.jar
[root@hadoop /usr/local/presto-server]# chmod a+x bin/presto-cli.jar使用presto-client连接presto-server,进入到交互式终端,测试下能否正常查询Hive中的数据:
[root@hadoop /usr/local/presto-server]# bin/presto-cli.jar --server localhost:9090 --catalog hive --user root
presto> show catalogs;
Catalog
---------
hive
jmx
system
(3 rows)
Query 20201116_091555_00001_cus94, FINISHED, 1 node
Splits: 19 total, 19 done (100.00%)
0:00 [0 rows, 0B] [0 rows/s, 0B/s]
presto> show schemas;
Schema
--------------------
db01
default
information_schema
(3 rows)
Query 20201116_091557_00002_cus94, FINISHED, 1 node
Splits: 19 total, 19 done (100.00%)
0:00 [3 rows, 44B] [16 rows/s, 243B/s]
presto> use db01;
USE
presto:db01> show tables;
Table
----------
log_dev
log_dev2
(2 rows)
Query 20201116_091652_00004_cus94, FINISHED, 1 node
Splits: 19 total, 19 done (100.00%)
0:00 [2 rows, 43B] [5 rows/s, 117B/s]
presto:db01> select * from log_dev;
id | name | create_time | creator | info
----+----------+-------------+---------+----------------
4 | 更新用户 | 1554189515 | yarn | 更新用户 test3
6 | 创建用户 | 1554299345 | yarn | 创建用户 test5
(2 rows)
Query 20201116_091705_00005_cus94, FINISHED, 1 node
Splits: 17 total, 17 done (100.00%)
0:01 [2 rows, 84B] [2 rows/s, 84B/s]
presto:db01> presto-server提供了ui界面,可以在该界面上查看一些监控信息。使用浏览器访问9090端口: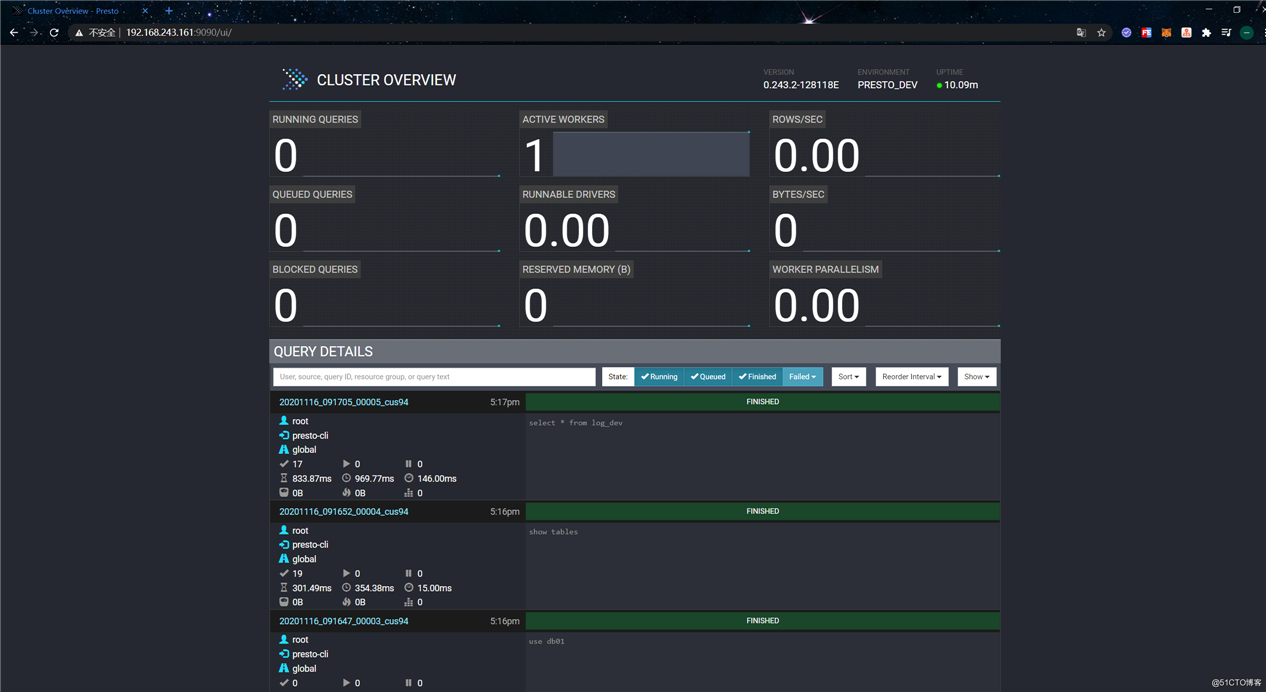
点击Query ID可以进入Query Detail页面查看该Query的详细信息: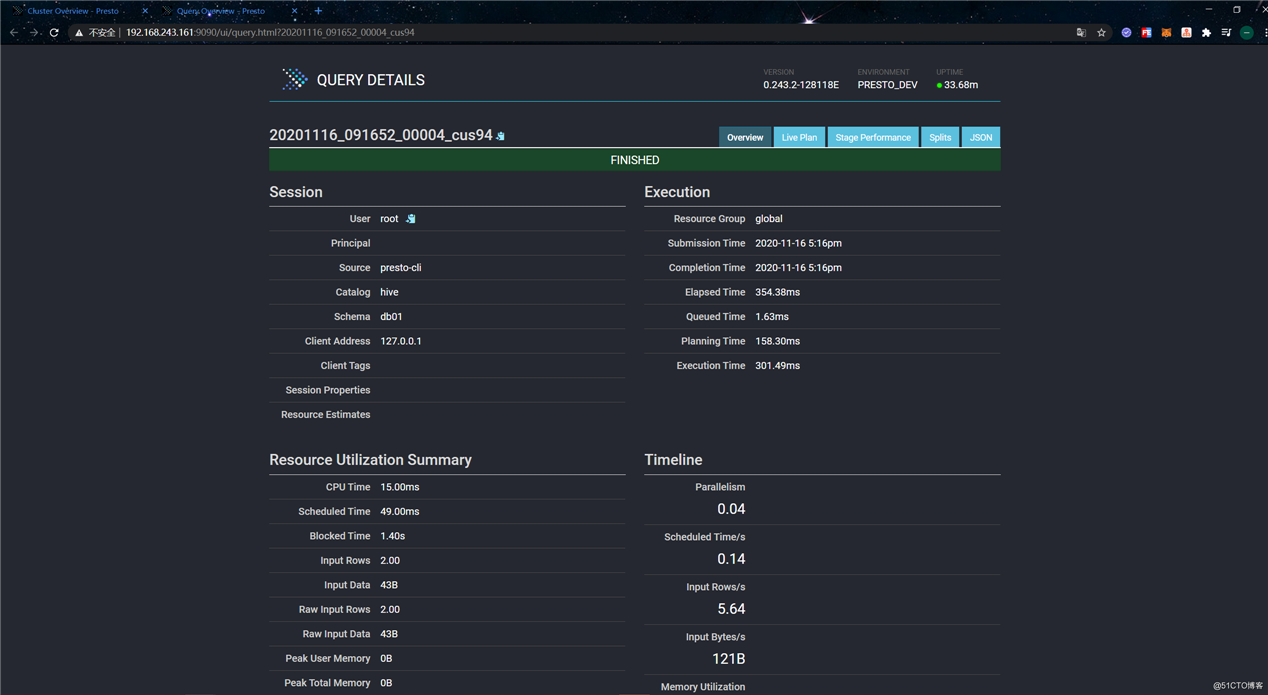
往下拉可以查看Stages和Task信息: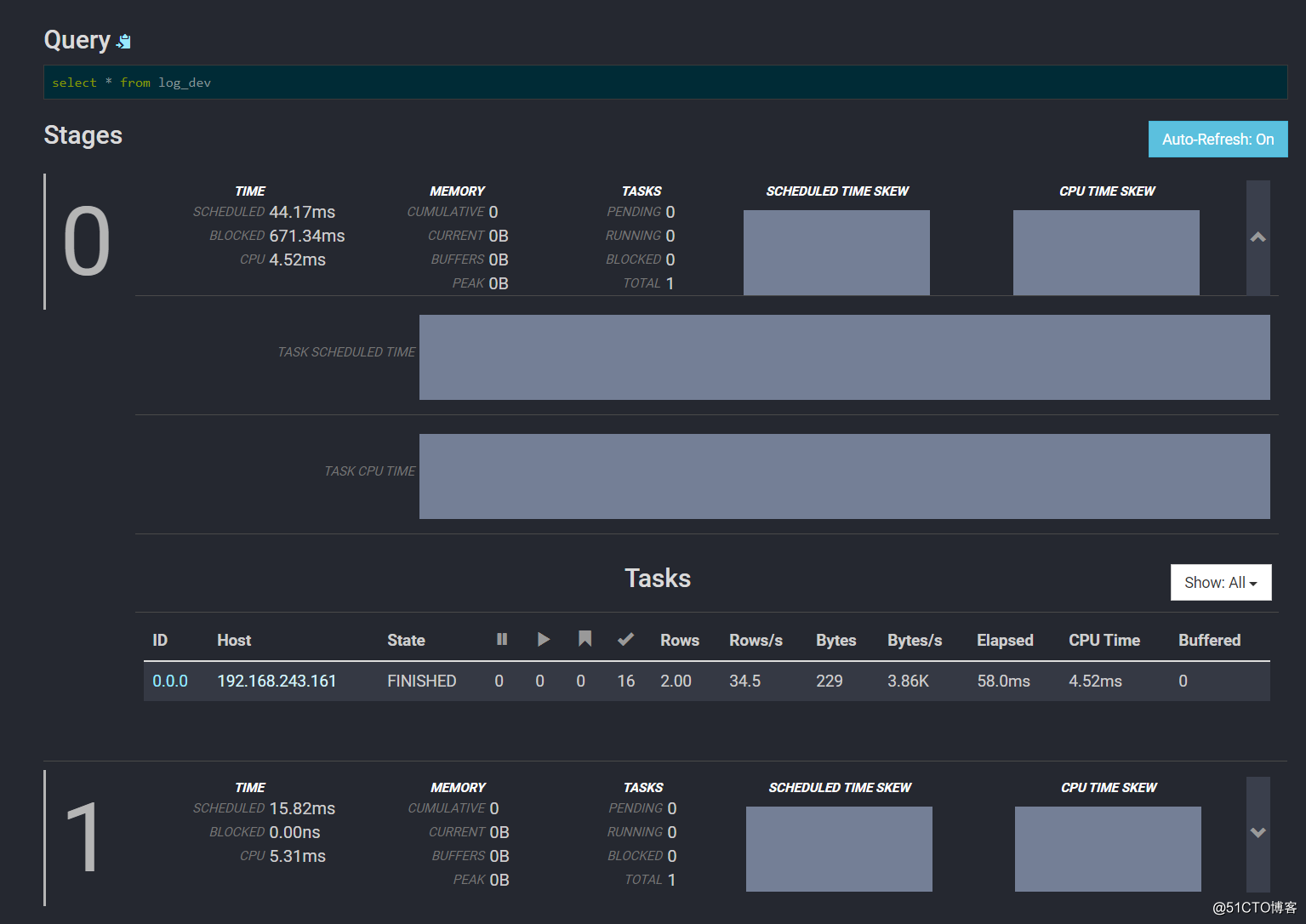
点击“Live Plan”可以查看执行计划: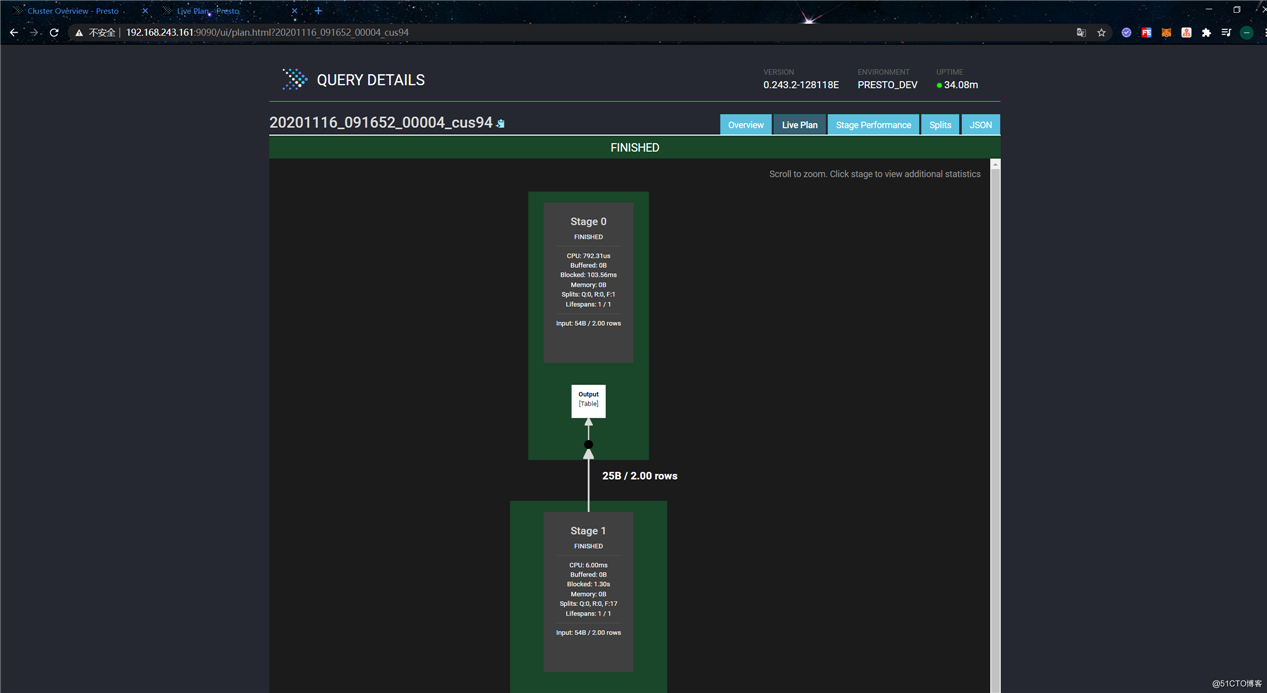
通过Jdbc操作Presto
在上一小节中,简单演示了使用presto-client操作presto-server,本小节则演示下如何通过编写代码以JDBC的方式操作presto-server。首先,创建Maven项目,pom文件的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>presto-test</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-jdbc</artifactId>
<version>0.243.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>编写JDBC代码如下:
package com.example.presto.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
/**
* 使用JDBC操作Presto
*
* @author 01
* @date 2020-11-16
**/
public class JdbcTest {
public static void main(String[] args) throws Exception {
Class.forName("com.facebook.presto.jdbc.PrestoDriver");
Connection connection = DriverManager.getConnection(
"jdbc:presto://192.168.243.161:9090/hive/db01",
"root", null
);
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("select * from log_dev");
while (resultSet.next()) {
for (int i = 1; i <= resultSet.getMetaData().getColumnCount(); i++) {
System.out.print(resultSet.getString(i) + " ");
}
System.out.println();
}
resultSet.close();
connection.close();
}
}执行结果如下: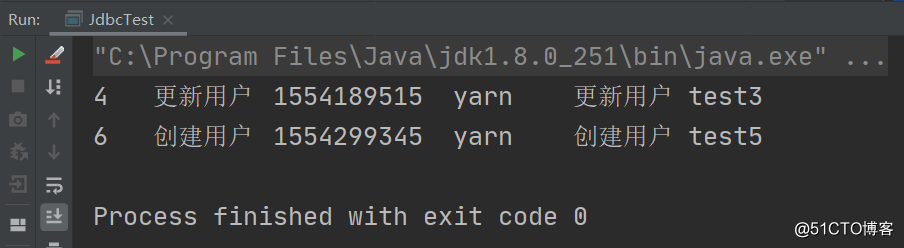
Presto UDF开发之Scalar函数
与Hive和Spark SQL一样,Presto也支持用户自定义函数(UDF)。Presto UDF:
- 在Presto中,函数大体分为三种:scalar、aggregation和window
- Scalar就是标量函数,简单来说就是Java中的一个静态方法,本身没有任何状态
- Aggregation函数,就是需要累积状态的函数,例如COUNT、AVG等
Scalar函数的开发步骤:
- 定义一个Java类,用
@ScalarFunction注解标记实现业务逻辑的静态方法 - 使用
@Description描述函数的作用,这里的内容会在SHOW FUNCTIONS中显示 - 使用
@SqlType标记函数的返回值类型
在pom文件中,添加如下依赖:
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-spi</artifactId>
<version>0.243</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>开发一个scalar类型函数,实现为字符串添加一个前缀,代码示例:
package com.example.presto.demo.udf;
import com.facebook.presto.common.type.StandardTypes;
import com.facebook.presto.spi.function.Description;
import com.facebook.presto.spi.function.ScalarFunction;
import com.facebook.presto.spi.function.SqlType;
import io.airlift.slice.Slice;
import io.airlift.slice.Slices;
public class PrefixFunction {
/**
* 为字符串添加一个前缀
* presto中没有String类型,使用Slice代替
*/
@ScalarFunction("Prefix")
@Description("prefix string")
@SqlType(StandardTypes.VARCHAR)
public static Slice prefix(@SqlType(StandardTypes.VARCHAR) Slice value) {
return Slices.utf8Slice("presto_udf_" + value.toStringUtf8());
}
}scalar类型函数支持传入多个值,例如可以实现一个根据传入的数据生成json字符串的函数,代码示例:
package com.example.presto.demo.udf;
import com.facebook.presto.common.type.StandardTypes;
import com.facebook.presto.spi.function.Description;
import com.facebook.presto.spi.function.ScalarFunction;
import com.facebook.presto.spi.function.SqlNullable;
import com.facebook.presto.spi.function.SqlType;
import io.airlift.slice.Slice;
import io.airlift.slice.Slices;
public class GenJson {
/**
* 根据传入的数据生成json字符串
*/
@ScalarFunction("GenJson")
@Description("gen json string")
@SqlType(StandardTypes.VARCHAR)
public static Slice genJson(@SqlType(StandardTypes.VARCHAR) Slice key,
@SqlType(StandardTypes.VARCHAR) Slice value) {
return Slices.utf8Slice(
String.format("{"%s":"%s"}", key.toStringUtf8(),
value == null ? "" : value.toStringUtf8())
);
}
}编写一个Plugin的实现类,在getFunctions方法中添加我们开发的UDF函数。代码如下:
package com.example.presto.demo.udf;
import com.facebook.presto.spi.Plugin;
import com.google.common.collect.ImmutableSet;
import java.util.Set;
public class ExampleFunctionsPlugin implements Plugin {
@Override
public Set<Class<?>> getFunctions() {
return ImmutableSet.<Class<?>>builder()
.add(PrefixFunction.class)
.add(GenJson.class)
.build();
}
}最后还需要在项目的resources目录下创建如下目录文件:
文件内容如下:
com.example.presto.demo.udf.ExampleFunctionsPlugin将项目编译并打包上传到服务器:
[root@hadoop ~/jars]# ls
presto-test-1.0-SNAPSHOT.jar
[root@hadoop ~/jars]# 将jar包拷贝到presto-server的plugin目录下:
[root@hadoop ~]# mkdir /usr/local/presto-server/plugin/example-functions
[root@hadoop ~]# cp jars/presto-test-1.0-SNAPSHOT.jar /usr/local/presto-server/plugin/example-functions
[root@hadoop ~]# cp /usr/local/presto-server/plugin/hive-hadoop2/guava-26.0-jre.jar /usr/local/presto-server/plugin/example-functions # 项目中依赖了guava,所以需要一并拷贝
[root@hadoop ~]# ls /usr/local/presto-server/plugin/example-functions
guava-26.0-jre.jar presto-test-1.0-SNAPSHOT.jar重启presto-server:
[root@hadoop ~]# /usr/local/presto-server/bin/launcher restart使用presto-cli进入交互命令行,验证一下我们开发的UDF函数是否生效:
[root@hadoop /usr/local/presto-server]# bin/presto-cli.jar --server localhost:9090 --catalog hive --user root
presto> use db01;
USE
presto:db01> select Prefix(name) from log_dev;
_col0
---------------------
presto_udf_更新用户
presto_udf_创建用户
(2 rows)
Query 20201116_121815_00002_upy9p, FINISHED, 1 node
Splits: 17 total, 17 done (100.00%)
0:01 [2 rows, 84B] [1 rows/s, 63B/s]
presto:db01> select GenJson(creator, name) from log_dev;
_col0
---------------------
{"yarn":"更新用户"}
{"yarn":"创建用户"}
(2 rows)
Query 20201116_121905_00003_upy9p, FINISHED, 1 node
Splits: 17 total, 17 done (100.00%)
0:00 [2 rows, 84B] [8 rows/s, 336B/s]
presto:db01> Presto UDF开发之Aggregation函数
Aggregation函数中的几个概念:
input(state, data):针对每条数据,执行input函数,在每个有数据的节点都会执行,最终得到多个累积的状态数据combine(state1, state2):将所有节点的状态数据聚合起来,直至所有状态数据被聚合成一个最终状态,即Aggregation函数的输出结果output(final_state, out):最终输出结果到一个BlockBuilder
Aggregation函数的开发步骤:
- 定义一个Java类,用
@AggregationFunction标记为Aggregation函数 - 使用
@InputFunction、@CombineFunction、@OutputFunction分别标记计算函数、合并结果函数和最终输出函数 - 实现相关函数逻辑
首先,定义一个接口,继承AccumulatorState,声明用于提供和获取值的方法:
package com.example.presto.demo.udf;
import com.facebook.presto.spi.function.AccumulatorState;
import io.airlift.slice.Slice;
public interface StringValueState extends AccumulatorState {
Slice getStringValue();
void setStringValue(Slice value);
}然后定义一个Java类,实现Aggregation函数的核心逻辑:
package com.example.presto.demo.udf;
import com.facebook.presto.common.block.BlockBuilder;
import com.facebook.presto.common.type.StandardTypes;
import com.facebook.presto.common.type.VarcharType;
import com.facebook.presto.spi.function.*;
import io.airlift.slice.Slice;
import io.airlift.slice.Slices;
/**
* Aggregation函数 - 实现字符串连接功能
*
* @author 01
*/
@AggregationFunction("ConcatStr")
public class ConCatFunction {
@InputFunction
public static void input(StringValueState state,
@SqlType(StandardTypes.VARCHAR) Slice value) {
state.setStringValue(Slices.utf8Slice(
checkNull(state.getStringValue()) + "|" +
value.toStringUtf8()
));
}
@CombineFunction
public static void combine(StringValueState state,
StringValueState otherState) {
state.setStringValue(Slices.utf8Slice(
checkNull(state.getStringValue()) + "|" +
checkNull(otherState.getStringValue())
));
}
@OutputFunction(StandardTypes.VARCHAR)
public static void output(StringValueState state,
BlockBuilder blockBuilder) {
VarcharType.VARCHAR.writeSlice(blockBuilder, state.getStringValue());
}
private static String checkNull(Slice slice) {
return slice == null ? "" : slice.toStringUtf8();
}
}然后还需要在ExampleFunctionsPlugin中添加该函数:
public class ExampleFunctionsPlugin implements Plugin {
@Override
public Set<Class<?>> getFunctions() {
return ImmutableSet.<Class<?>>builder()
...
.add(ConCatFunction.class)
.build();
}
}将项目编译打包并上传到服务器:
[root@hadoop ~]# ls jars/
presto-test-1.0-SNAPSHOT.jar
[root@hadoop ~]# 覆盖之前的jar包:
[root@hadoop ~]# cp jars/presto-test-1.0-SNAPSHOT.jar /usr/local/presto-server/plugin/example-functions/
cp:是否覆盖"/usr/local/presto-server/plugin/example-functions/presto-test-1.0-SNAPSHOT.jar"? yes
[root@hadoop ~]# 重启presto-server:
[root@hadoop ~]# /usr/local/presto-server/bin/launcher restart使用presto-cli进入交互命令行,验证一下我们开发的UDF函数是否生效:
[root@hadoop /usr/local/presto-server]# bin/presto-cli.jar --server localhost:9090 --catalog hive --user root
presto> use db01;
USE
presto:db01> select ConcatStr(creator) from log_dev2;
_col0
---------------------------------
||hdfs|yarn|hdfs|yarn|hdfs|yarn
(1 row)
Query 20201116_124714_00001_inrgm, FINISHED, 1 node
Splits: 18 total, 18 done (100.00%)
0:01 [6 rows, 825B] [4 rows/s, 571B/s]
presto:db01> Presto EventListener开发
Event Listener是Presto提供的事件监听机制,我们可以通过开发自己的Event Listener来监听Presto中发生的一些事件,例如建立查询、查询成功/失败等事件。总体来说,Event Listener有点类似于Hive中的Hook。Presto提供了三种Event Listener:
- Query Creation:Presto查询建立相关信息
- Query completion:查询执行相关信息,包含成功查询的细节信息,失败查询的错误码等信息
- Split completion:split执行信息,同理包含成功和失败的细节信息
Event Listener的开发步骤:
- 实现Presto的
EventListener和EventListenerFactory接口 - 基于服务提供者接口(SPI)正确的打包我们的jar
- 部署,放到Presto指定目录,修改配置文件并重启服务
接下来演示一下开发一个EventListener,实现监听事件并将事件信息写入日志文件。首先,编写EventListener的实现类,核心逻辑都在该类中。代码如下:
package com.example.presto.demo.eventlistener;
import com.facebook.presto.spi.eventlistener.EventListener;
import com.facebook.presto.spi.eventlistener.QueryCompletedEvent;
import com.facebook.presto.spi.eventlistener.QueryCreatedEvent;
import com.facebook.presto.spi.eventlistener.SplitCompletedEvent;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.time.Instant;
import java.util.Map;
public class QueryEventListener implements EventListener {
private final String logPath;
public QueryEventListener(Map<String, String> config) {
logPath = config.get("log.path");
System.out.println(logPath);
}
/**
* 监听创建查询事件
*/
@Override
public void queryCreated(QueryCreatedEvent queryCreatedEvent) {
String queryId = queryCreatedEvent.getMetadata().getQueryId();
String query = queryCreatedEvent.getMetadata().getQuery();
String user = queryCreatedEvent.getContext().getUser();
String fileName = logPath + File.separator + queryId;
File logFile = new File(fileName);
if (!logFile.exists()) {
try {
boolean result = logFile.createNewFile();
System.out.println(result);
} catch (IOException e) {
e.printStackTrace();
}
}
try (FileWriter fw = new FileWriter(fileName, true)) {
fw.append(String.format("User:%s Id:%s Query:%s%n", user, queryId, query));
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 监听查询完成事件
*/
@Override
public void queryCompleted(QueryCompletedEvent queryCompletedEvent) {
String queryId = queryCompletedEvent.getMetadata().getQueryId();
long createTime = queryCompletedEvent.getCreateTime().toEpochMilli();
long endTime = queryCompletedEvent.getEndTime().toEpochMilli();
long totalBytes = queryCompletedEvent.getStatistics().getTotalBytes();
String queryState = queryCompletedEvent.getMetadata().getQueryState();
queryCompletedEvent.getFailureInfo().ifPresent(queryFailureInfo -> {
int errCode = queryFailureInfo.getErrorCode().getCode();
String failureType = queryFailureInfo.getFailureType().orElse("").toUpperCase();
String failureHost = queryFailureInfo.getFailureHost().orElse("");
String failureMessage = queryFailureInfo.getFailureMessage().orElse("");
});
String fileName = logPath + File.separator + queryId;
try (FileWriter fw = new FileWriter(fileName, true)) {
fw.append(String.format("Id:%s StartTime:%s EndTime:%s State:%s%n",
queryId, createTime, endTime, queryState));
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 监听split完成事件
*/
@Override
public void splitCompleted(SplitCompletedEvent splitCompletedEvent) {
long createTime = splitCompletedEvent.getCreateTime().toEpochMilli();
long endTime = splitCompletedEvent.getEndTime().orElse(Instant.MAX).toEpochMilli();
String queryId = splitCompletedEvent.getQueryId();
String stageId = splitCompletedEvent.getStageId();
String taskId = splitCompletedEvent.getTaskId();
String fileName = logPath + File.separator + queryId;
try (FileWriter fw = new FileWriter(fileName, true)) {
fw.append(String.format("Id:%s StartTime:%s EndTime:%s StageId:%s TaskId:%s%n",
queryId, createTime, endTime, stageId, taskId));
} catch (IOException e) {
e.printStackTrace();
}
}
}然后编写一个工厂类实现EventListenerFactory接口,用于创建我们自定义的QueryEventListener:
package com.example.presto.demo.eventlistener;
import com.facebook.presto.spi.eventlistener.EventListener;
import com.facebook.presto.spi.eventlistener.EventListenerFactory;
import java.util.Map;
public class QueryEventListenerFactory implements EventListenerFactory {
@Override
public String getName() {
// EventListener的名称
return "query-event-listener";
}
@Override
public EventListener create(Map<String, String> config) {
if (!config.containsKey("log.path")) {
throw new RuntimeException("missing log.path conf");
}
return new QueryEventListener(config);
}
}编写Plugin的实现类,在getEventListenerFactories方法中添加我们自定义的EventListener创建工厂:
package com.example.presto.demo.eventlistener;
import com.facebook.presto.spi.Plugin;
import com.facebook.presto.spi.eventlistener.EventListenerFactory;
import java.util.Collections;
public class QueryEventPlugin implements Plugin {
@Override
public Iterable<EventListenerFactory> getEventListenerFactories() {
QueryEventListenerFactory queryEventListenerFactory = new QueryEventListenerFactory();
return Collections.singletonList(queryEventListenerFactory);
}
}最后还需要在com.facebook.presto.spi.Plugin文件中,添加QueryEventPlugin类的包路径:
com.example.presto.demo.eventlistener.QueryEventPlugin将项目编译打包并上传到服务器:
[root@hadoop ~]# ls jars/
presto-test-1.0-SNAPSHOT.jar
[root@hadoop ~]# 将jar包拷贝到presto-server的plugin目录下:
[root@hadoop ~]# mkdir /usr/local/presto-server/plugin/event-listener
[root@hadoop ~]# cp jars/presto-test-1.0-SNAPSHOT.jar /usr/local/presto-server/plugin/event-listener
[root@hadoop ~]# cp /usr/local/presto-server/plugin/hive-hadoop2/guava-26.0-jre.jar /usr/local/presto-server/plugin/event-listener # 项目中依赖了guava,所以需要一并拷贝
[root@hadoop ~]# ls /usr/local/presto-server/plugin/event-listener
guava-26.0-jre.jar presto-test-1.0-SNAPSHOT.jar删除example-functions目录,否则会在启动presto-server时因为重复注册UDF而报错:
[root@hadoop ~]# rm -rf /usr/local/presto-server/plugin/example-functions/然后还需要配置一下presto的event-listener:
[root@hadoop ~]# vim /usr/local/presto-server/etc/event-listener.properties
event-listener.name=query-event-listener
log.path=/data/presto/log
[root@hadoop ~]# mkdir -p /data/presto/log重启presto-server:
[root@hadoop ~]# /usr/local/presto-server/bin/launcher restart使用presto-cli进入交互命令行,随便执行一些查询语句:
[root@hadoop /usr/local/presto-server]# bin/presto-cli.jar --server localhost:9090 --catalog hive --user root
presto> use db01;
USE
presto:db01> select * from log_dev;
id | name | create_time | creator | info
----+----------+-------------+---------+----------------
4 | 更新用户 | 1554189515 | yarn | 更新用户 test3
6 | 创建用户 | 1554299345 | yarn | 创建用户 test5
(2 rows)
Query 20201116_132643_00001_tvyva, FINISHED, 1 node
Splits: 17 total, 17 done (100.00%)
0:01 [2 rows, 84B] [1 rows/s, 58B/s]
presto:db01> select * from log_dev2 limit 1;
id | name | create_time | creator | info
----+----------+-------------+---------+---------------
1 | 创建用户 | 1554099545 | hdfs | 创建用户 test
(1 row)
Query 20201116_132652_00002_tvyva, FINISHED, 1 node
Splits: 18 total, 18 done (100.00%)
0:00 [1 rows, 825B] [3 rows/s, 2.48KB/s]
presto:db01> 然后验证一下我们开发的EventListener是否生效,查看是否有记录相应的事件日志信息即可:
[root@hadoop ~]# ls /data/presto/log/
20201116_132435_00000_tvyva 20201116_132643_00001_tvyva 20201116_132652_00002_tvyva
[root@hadoop ~]# cat /data/presto/log/20201116_132435_00000_tvyva
User:root Id:20201116_132435_00000_tvyva Query:use db01
Id:20201116_132435_00000_tvyva StartTime:1605533075986 EndTime:1605533076000 State:FINISHED
[root@hadoop ~]# cat /data/presto/log/20201116_132643_00001_tvyva
User:root Id:20201116_132643_00001_tvyva Query:select * from log_dev
Id:20201116_132643_00001_tvyva StartTime:1605533204999 EndTime:1605533205193 StageId:20201116_132643_00001_tvyva.1 TaskId:0
...
Id:20201116_132643_00001_tvyva StartTime:1605533203889 EndTime:1605533205297 State:FINISHED
[root@hadoop ~]# cat /data/presto/log/20201116_132652_00002_tvyva
User:root Id:20201116_132652_00002_tvyva Query:select * from log_dev2 limit 1
Id:20201116_132652_00002_tvyva StartTime:1605533212541 EndTime:1605533212644 StageId:20201116_132652_00002_tvyva.1 TaskId:0
...
Id:20201116_132652_00002_tvyva StartTime:1605533212413 EndTime:1605533212688 State:FINISHED
[root@hadoop ~]# Presto配置优化
Presto架构:
- Presto采用典型的Master - Slave架构模型
- Coordinator和Worker依赖Discovery Server进行相互通信
- Coordinator和DiscoveryServer在设计上是单点的,存在单点问题
Presto高可用方案之绑定虚拟IP:
Presto高可用方案之独立部署Discovery Server: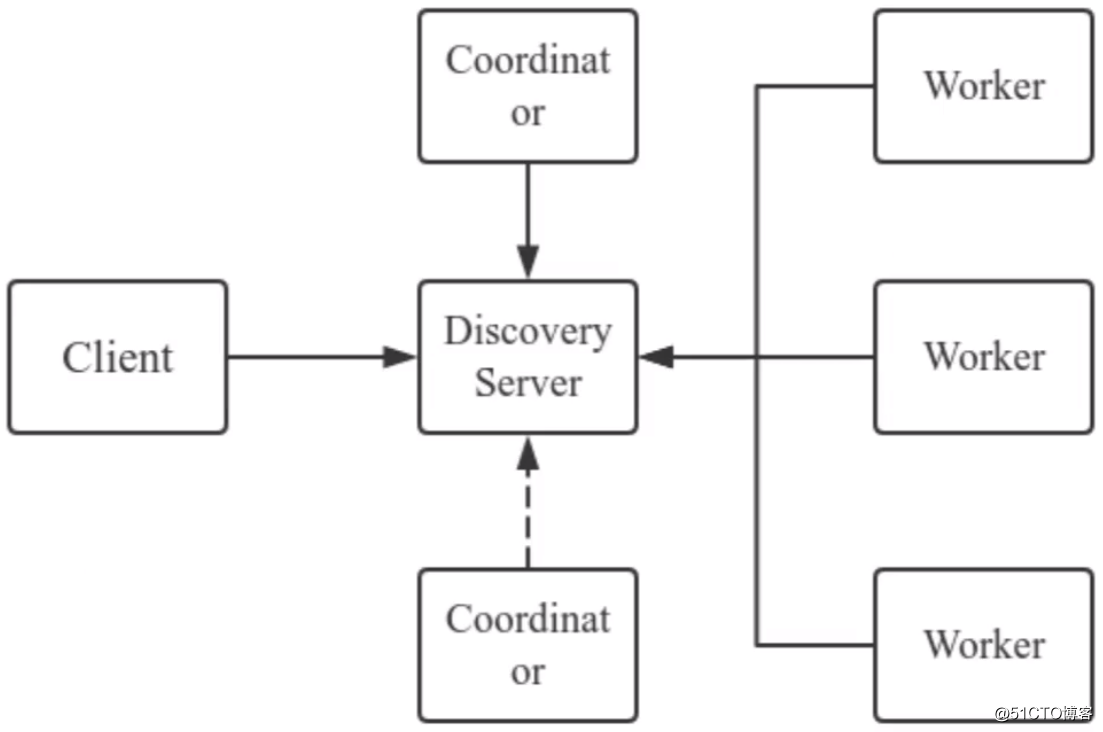
Presto内存模型:
- Presto采用逻辑的内存池,来管理不同类型的内存需求
- Presto把整个内存划分成三个内存池,分别是System Pool,ReservedPool,General Pool
- Presto 0.201+版本之后,默认不启用SystemPool,只保留ReservedPool和General Pool
- System Pool是用来保留给系统使用的,默认为40%的内存空间留给系统使用,0.201+版本,SystemPool合并到GeneralPool
- Reserved Pool和General Pool用来分配query运行时内存
- 大部分的query使用General Pool,当General Pool满了之后,将使用内存最大的SQL放到Reserved Pool执行
Presto内存管理:
- Query内存管理:query划分成很多task,每个task会有一个线程循环获取task的状态,包括task所用内存。汇总成query所用内存
- 机器内存管理:Coordinator有一个线程,定时的轮询每台机器,查看当前的机器内存状态
Presto通过两点判断集群是否达到了内存的上限:
- General Pool出现阻塞节点(Block node)
- Reserved Pool已经被使用
通过设置query.low-memory-killer.policy配置参数,可以指定kill查询的策略。该参数取值:total-reservation-on-blocked-nodes(kill在阻塞节点上使用内存最多的查询)或者total-reservation(kill最耗费内存的查询)
在了解了Presto的内存模型和内存管理后,以下列举一些在Presto中可以优化的配置参数:
query.max-memory:单个query在整个集群中允许占用的最大user memoryquery.max-total-memory:单个query在整个集群中允许占用的最大(user + system) memoryquery.max-memory-per-node:一个query在单个worker上允许的最大user memory,即ReservedPool,默认为heapSize的0.1query.max-total-memory-per-node:一个query在单个worker上允许的最大(user + system) memory
用户查询数据量/复杂性,决定了ReservedPool大小;用户查询并发度,决定了jvm heapSize的大小
以上是关于大数据平台建设 —— SQL查询引擎之Presto的主要内容,如果未能解决你的问题,请参考以下文章
SQL查询引擎对峙:Spark VS Impala VS Hive VS Presto