赵强老师大数据分析引擎:Presto
Posted 赵强老师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了赵强老师大数据分析引擎:Presto相关的知识,希望对你有一定的参考价值。
一、什么是Presto?
- 背景知识:Hive的缺点和Presto的背景
Hive使用MapReduce作为底层计算框架,是专为批处理设计的。但随着数据越来越多,使用Hive进行一个简单的数据查询可能要花费几分到几小时,显然不能满足交互式查询的需求。Presto是一个分布式SQL查询引擎,它被设计为用来专门进行高速、实时的数据分析。它支持标准的ANSI SQL,包括复杂查询、聚合(aggregation)、连接(join)和窗口函数(window functions)。这其中有两点就值得探究,首先是架构,其次自然是怎么做到低延迟来支持及时交互。
- PRESTO是什么?
Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。Presto的设计和编写完全是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。
- 它可以做什么?
Presto支持在线数据查询,包括Hive, Cassandra, 关系数据库以及专有数据存储。 一条Presto查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。Presto以分析师的需求作为目标,他们期望响应时间小于1秒到几分钟。 Presto终结了数据分析的两难选择,要么使用速度快的昂贵的商业方案,要么使用消耗大量硬件的慢速的“免费”方案。
- 谁在使用它?
Facebook使用Presto进行交互式查询,用于多个内部数据存储,包括300PB的数据仓库。 每天有1000多名Facebook员工使用Presto,执行查询次数超过30000次,扫描数据总量超过1PB。领先的互联网公司包括Airbnb和Dropbox都在使用Presto。
二、Presto的体系架构
Presto是一个运行在多台服务器上的分布式系统。 完整安装包括一个coordinator和多个worker。 由客户端提交查询,从Presto命令行CLI提交到coordinator。 coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker。
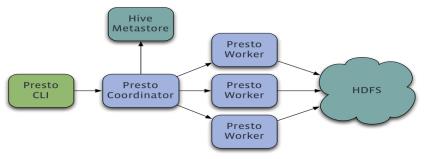
Presto查询引擎是一个Master-Slave的架构,由一个Coordinator节点,一个Discovery Server节点,多个Worker节点组成,Discovery Server通常内嵌于Coordinator节点中。Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。Worker节点负责实际执行查询任务。Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。
三、安装Presto Server
- 安装介质
presto-cli-0.217-executable.jar presto-server-0.217.tar.gz
- 安装配置Presto Server
1、解压安装包
tar -zxvf presto-server-0.217.tar.gz -C ~/training/
2、创建etc目录
cd ~/training/presto-server-0.217/ mkdir etc
3、需要在etc目录下包含以下配置文件
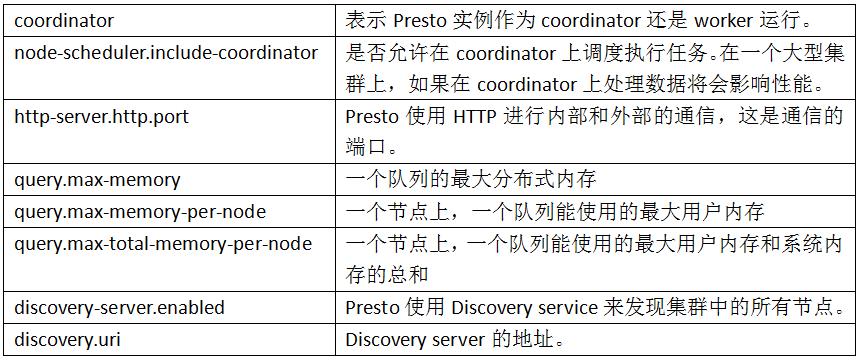
Node Properties: 节点的配置信息 JVM Config: 命令行工具的JVM配置参数 Config Properties: Presto Server的配置参数 Catalog Properties: 数据源(Connectors)的配置参数 Log Properties:日志参数配置
- 编辑node.properties
#集群名称。所有在同一个集群中的Presto节点必须拥有相同的集群名称。 node.environment=production #每个Presto节点的唯一标示。每个节点的node.id都必须是唯一的。在Presto进行重启或者升级过程中每个节点的node.id必须保持不变。如果在一个节点上安装多个Presto实例(例如:在同一台机器上安装多个Presto节点),那么每个Presto节点必须拥有唯一的node.id。 node.id=ffffffff-ffff-ffff-ffff-ffffffffffff # 数据存储目录的位置(操作系统上的路径)。Presto将会把日期和数据存储在这个目录下。 node.data-dir=/root/training/presto-server-0.217/data
- 编辑jvm.config
由于OutOfMemoryError将会导致JVM处于不一致状态,所以遇到这种错误的时候我们一般的处理措施就是收集dump headp中的信息(用于debugging),然后强制终止进程。Presto会将查询编译成字节码文件,因此Presto会生成很多class,因此我们我们应该增大Perm区的大小(在Perm中主要存储class)并且要允许Jvm class unloading。
-server -Xmx16G -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+UseGCOverheadLimit -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:+ExitOnOutOfMemoryError
- 编辑config.properties
coordinator的配置
coordinator=true node-scheduler.include-coordinator=false http-server.http.port=8080 query.max-memory=5GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery-server.enabled=true discovery.uri=http://192.168.157.226:8080
workers的配置
coordinator=false http-server.http.port=8080 query.max-memory=5GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery.uri=http://192.168.157.226:8080
如果我们想在单机上进行测试,同时配置coordinator和worker,请使用下面的配置:
coordinator=true node-scheduler.include-coordinator=true http-server.http.port=8080 query.max-memory=5GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery-server.enabled=true discovery.uri=http://192.168.157.226:8080
参数说明:
- 编辑log.properties
配置日志级别。
com.facebook.presto=INFO
- 配置Catalog Properties
Presto通过connectors访问数据。这些connectors挂载在catalogs上。 connector可以提供一个catalog中所有的schema和表。例如:Hive connector 将每个hive的database都映射成为一个schema,所以如果hive connector挂载到了名为hive的catalog, 并且在hive的web有一张名为clicks的表, 那么在Presto中可以通过hive.web.clicks来访问这张表。通过在etc/catalog目录下创建catalog属性文件来完成catalogs的注册。 如果要创建hive数据源的连接器,可以创建一个etc/catalog/hive.properties文件,文件中的内容如下,完成在hivecatalog上挂载一个hiveconnector。
#注明hadoop的版本 connector.name=hive-hadoop2 #hive-site中配置的地址 hive.metastore.uri=thrift://192.168.157.226:9083 #hadoop的配置文件路径 hive.config.resources=/root/training/hadoop-2.7.3/etc/hadoop/core-site.xml,/root/training/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
注意:要访问Hive的话,需要将Hive的MetaStore启动:hive --service metastore

四、启动Presto Server
./launcher start
五、运行presto-cli
- 下载:presto-cli-0.217-executable.jar
- 重命名jar包,并增加执行权限
cp presto-cli-0.217-executable.jar presto chmod a+x presto
- 连接Presto Server
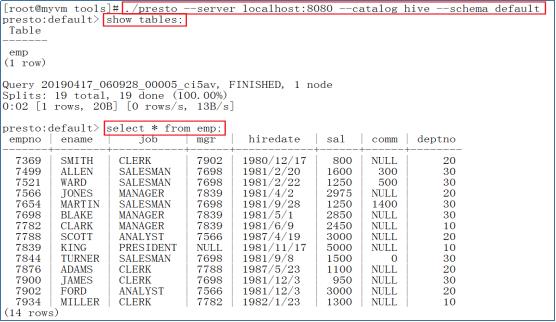
./presto --server localhost:8080 --catalog hive --schema default
六、使用Presto
- 使用Presto操作Hive
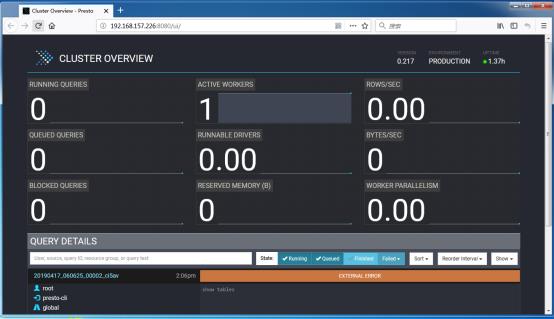
- 使用Presto的Web Console:端口:8080
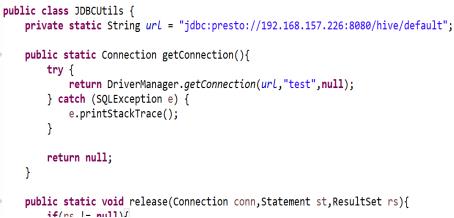
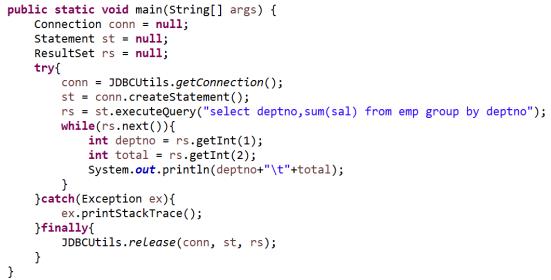
- 使用JDBC操作Presto
1、需要包含的Maven依赖
<dependency> <groupId>com.facebook.presto</groupId> <artifactId>presto-jdbc</artifactId> <version>0.217</version> </dependency>
2、JDBC代码
*******************************************************************************************

以上是关于赵强老师大数据分析引擎:Presto的主要内容,如果未能解决你的问题,请参考以下文章