Yarn环境搭建
Posted 敏叔的技术札记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Yarn环境搭建相关的知识,希望对你有一定的参考价值。
Hadoop在2.x的版本中引入了Yarn,我最开始从事大数据方面工作的时公司还是用着原有的那套Jobtracker和Tasktracker,所以还是蛮有印象的。印象很深的就是那个时候为了说yarn好,然后就要批斗一番之前的多么不好,颇有革命的味道,实际上那个时候大部分公司的作业量其实不大,尤其中小公司很多都是建立hadoop小集群探索的阶段,问题也没那么夸张 。
图一:那些年批斗的样子
纵观这几年大数据生态圈的高速迭代,新的特性不断引入,旧的问题不断解决,对每一次新版本的出现,都是满怀期待。Yarn是新引入计算平台,主要工作负责分布式环境上面的资源协作,从名字Yet Another Resource Negotiator可以看出来,yarn就是管理资源的。嗯,对 就是收租子那种。
之前同组的小伙伴拿了我的Yarn的书啃了一个礼拜, 然后那几天吃饭一直说:“敏叔,那个yarn到底是个啥?”,我当时是这样说的 “Yarn有点像教室,老师要上课就要申请教室,但是里面上课内容是自己管的”,我现在更感觉有点像商铺,房东是拥有资产的人,而我们去租商铺要付月租,里面什么店子才是我们管的。 管理资源的角色在Yarn中叫做ResourceManager,具体的商铺里面的房间呢叫做NodeManager,中间通过若干通信达到申请->资源执行作业的流程,具体官网给出简明图:
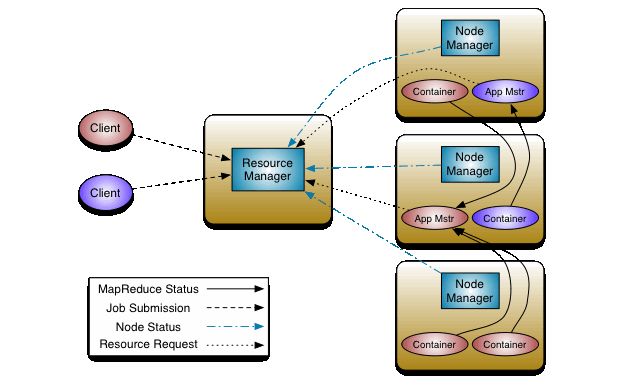
图二:官网上的Yarn结构
ResourceManager和NodeManager构成了我们集群上面的主从关系节点,我们现在来把这种结构环境搭建起来。
有了我们之前的基础,我们基本可以猜到yarn这种主从结构启动的套路了,在我们/usr/local/svr/hadoop/sbin目录下面已经安静躺着若干带关键yarn关键字的脚本了,根据之前启动hdfs的脚本命名习惯我们找到start-yarn.sh,执行一下,然后缺啥补啥。
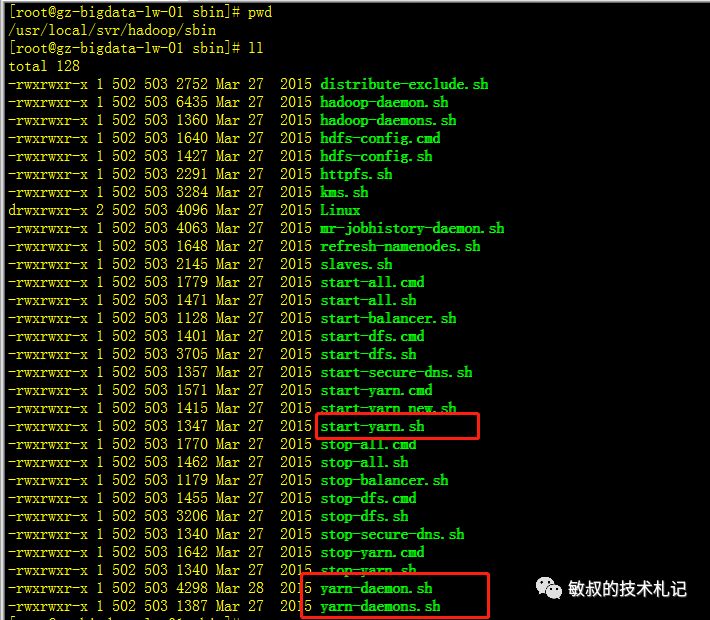
图三:yarn脚本
我们停掉我们的hdfs,停掉其他的东西,专注研究yarn。
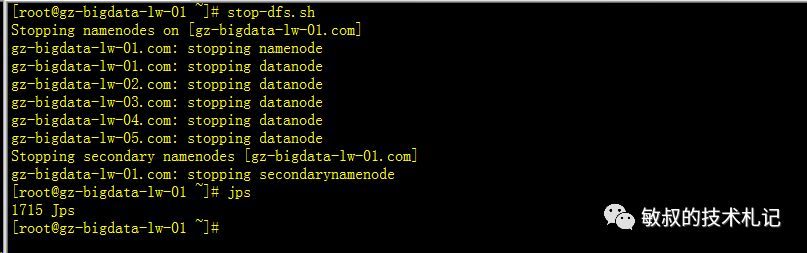
图四:停止hdfs集群
我们尝试启动一下yarn,并查看进程:
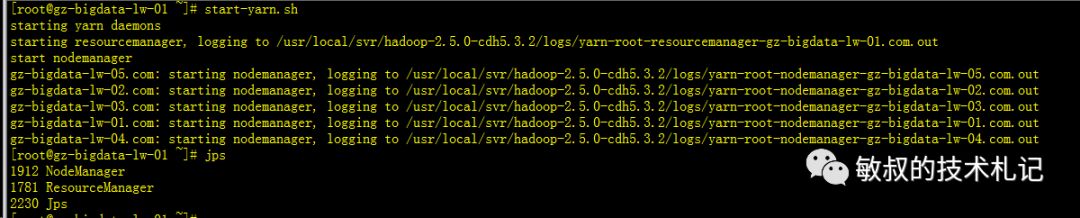
图五:进程结构
再去从节点上面看下进程结构
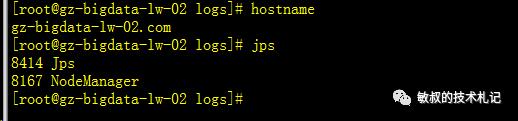
图六:从节点上进程结构
我们要的结构已经有了,我们去UI上面看看,默认resource访问是8080:
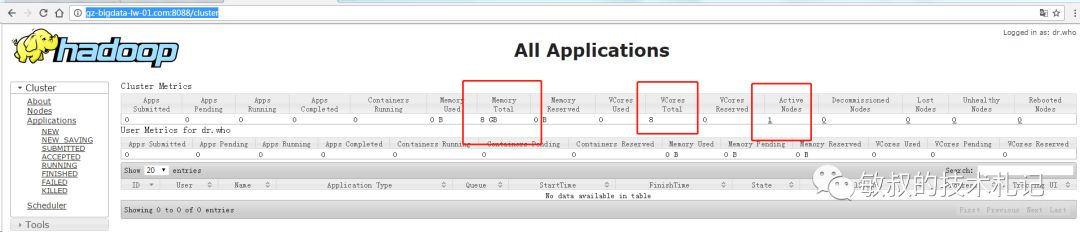
图七:ui信息
可以看到只有一个节点,上面分配的内存写了8G,cpu核心数是8核心。
首先是节点问题,我们可以在其他从节点上看到NodeManager,我们查看一下从节点上面的日志:

图八:ui上面的错误信息
这里为了配置方便我/root目录下面下面增加了软链接:
ln -s /usr/local/svr/hadoop/etc/hadoop hdp_etc我们修改好我们的配置文件:
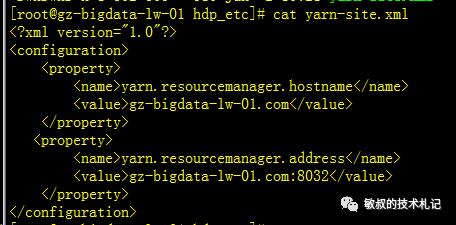
图九:为从节点添加上老大
同步配置,重启Yarn:
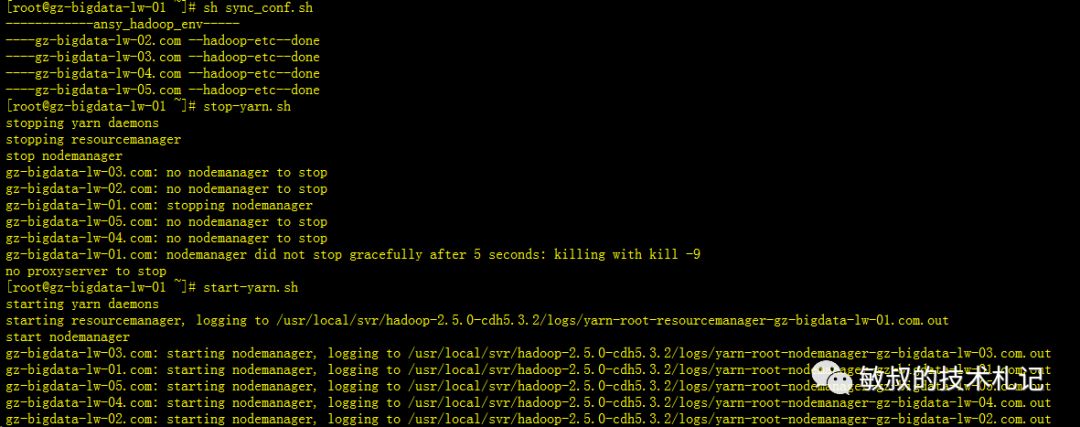
图十:重启
再次查看yarn
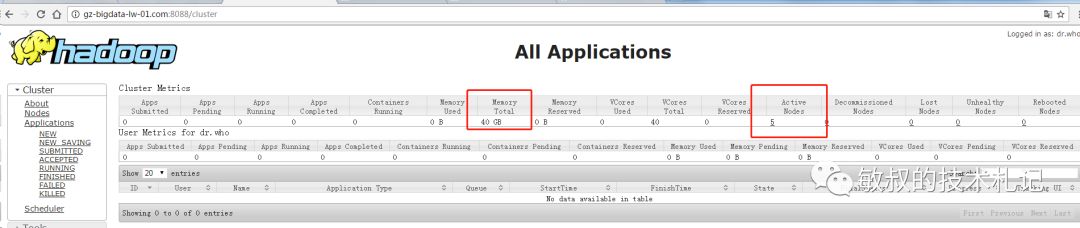
图十一:ui上面的效果
下面是内存和cpu的问题,我们没有做其他配置,这里显示和我们机器不一致,我们每台机器都是内存4G、CPU的双核。所以我们可以了解到,这个不是真正的计算机cpu和内存,而是需要我们主动设置的参数,我们查询官网找到我们的配置并且修改:
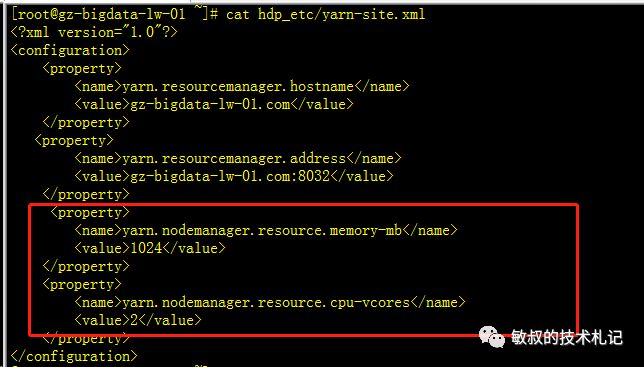
图十二:修改资源的配置
最后看到效果:
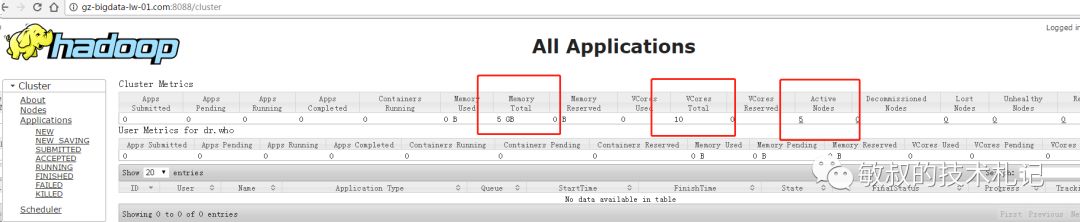
图十三:ui的效果
到这里我们的迷你小Yarn已经完全搭建好了,然后呢,跑上去开店呀,我们的hadoop开发大神早就知道这个事情,他们为我们准备了一个HelloWord版本的Yarn程序,果断我们也用来跑一波。这个程序叫做hadoop-yarn-applications-distributedshell,解决我们很兴奋搭建完成之后不知道做啥的尴尬^^。这里有一个事情就是,之前为了截图效果,把hdfs停了,yarn本身是不依赖hdfs的,但是在程序里面用到了hdfs的操作的话需要启动起来,依次执行以下命令:

图十四:启动hdfs 执行yarn程序
我们可以在ui上面看到这个程序的运行情况:

图十五:ui中记录了执行情况
解读一下这个程序的功能,这个程序运行之后会在每个分配到的container中执行一下我们传入的shell脚本,这两个参数
-shell_command '/bin/date' -num_containers 2表示要执行的脚本内容,里面的containsers 表示执行的容器数量,我们去追寻一波这个yarn程序的脚步,依次点开面板中的history->logs在container中我们可以看到被分配container的容器信息:
十六:history
图十七:logs
图十八:container的记录
我们可以读到,在02和04节点中,分配了两个容器,我们根据日志的结果直接登录节点机器查看执行的内容:
图十九:date运行的结果
这就是我们这个程序执行的最后结果!!
下一篇我们一起研究一下这个yarn程序, 捋一捋里面的过程~~
以上是关于Yarn环境搭建的主要内容,如果未能解决你的问题,请参考以下文章
(超详细) Spark环境搭建(Local模式 StandAlone模式Spark On Yarn模式)