:Spark环境搭建-Local
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:Spark环境搭建-Local相关的知识,希望对你有一定的参考价值。
一、课程服务器环境
本次课程使用三台Linux虚拟机服务器来学习, 三台虚拟机的功能分配是:
- node1: Master(HDFS\\YARN\\Spark) 和 Worker(HDFS\\ YARN\\ Spark)
- node2: Worker(HDFS\\ YARN\\ Spark)
- node3: Worker(HDFS\\ YARN\\ Spark) 和 Hive
集群环境的搭建, 同学们有2种选择:
方式1: 自行搭建
同学们可以自行创建三台Linux虚拟机
服务器集群即可, 满足如下要求即可跟着课程操作:
- 已部署好Hadoop集群(HDFS\\YARN), 要求版本Hadoop3以上
- JDK 1.8
- 操作系统CentOS 7 (建议7.6)
方式2: 使用课程中提供的虚拟机
课程资料中提供了3台虚拟机的压缩包, 同学们解压后导入 VMWare即可, 要求:
- VMWare WorkStation 要求版本 15或更高
- VMWare的网段设置为 192.168.88.0网段
二、基本原理
本质:启动一个JVM Process进程(一个进程里面有多个线程),执行任务Task
Local模式可以限制模拟Spark集群环境的线程数量, 即Local[N] 或 Local[*]
其中N代表可以使用N个线程,每个线程拥有一个cpucore。如果不指定N , 则默认是1个线程(该线程有1个core)。 通常Cpu有几个Core,就指定几个 线程,最大化利用计算能力.
如果是local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine.按照Cpu最多的Cores设置线程数。
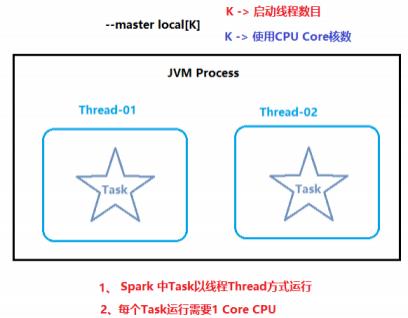
Local 下的角色分布:
资源管理:
Master: Local进程本身
Worker: Local进程本身
任务执行:
Driver: Local进程本身
Executor:不存在,没有独立的Executor角色, 由Local进程(也就是Driver)内的线程提供计算能力
PS: Driver也算一种特殊的Executor, 只不过多数时候, 我们将Executor当做纯Worker对待, 这样和Driver好区分(一类是管理 一类是工人)
注意: Local模式只能运行一个Spark程序, 如果执行多个Spark程序, 那就是由多个相互独立的Local进程在执行。
三、搭建
搭建操作, 可参考资料提供的部署文档<< spark部署文档.doc >> 中关于Local模式搭建操作
- 开箱即用:直接启动bin目录下的spark-shell:
/export/server/spark/bin/spark-shell
●运行成功以后,有如下提示信息:
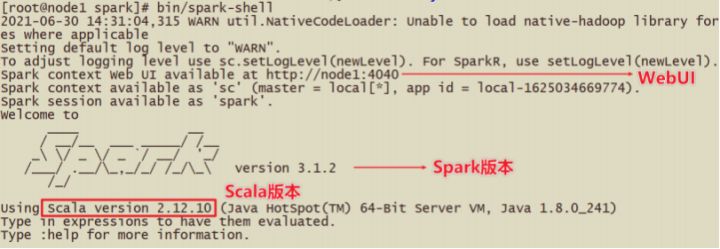
- sc :SparkContext实例对象:
- spark :SparkSession实例对象
- 4040 :Web监控页面端口号
四、测试 - 基于bin/pyspark
bin/pyspark 程序, 可以提供一个 交互式的 Python解释器环境, 在这里面可以用Python语言调用Spark API 进行计算。
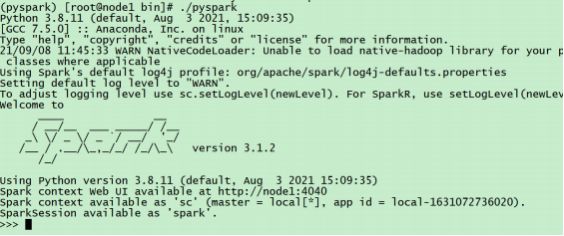
示例代码, 将数组内容都+1进行计算:
sc.parallelize([1,2,3,4,5]).map(lambda x: x + 1).collect()
五、测试 - 4040监控端口
每一个Spark程序在运行的时候, 会绑定到Driver所在机器的4040端口上.
如果4040端口被占用, 会顺延到4041 ... 4042...

4040端口是一个WEBUI端口, 可以在浏览器内打开, 输入:服务器ip:4040 即可打开:
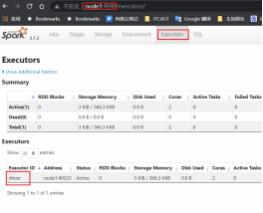
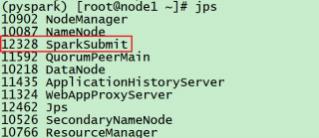
打开监控页面后, 可以发现 在程序内仅有一个Driver,因为我们是Local模式, Driver即管理 又 干活.同时, 输入jps
可以看到local模式下的唯一进程存在,这个进程 即是master也是worker。
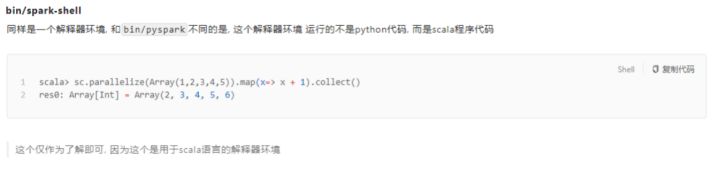
六、基于bin/spark-shell测试 - 了解(此项需Scala语言操作)
bin/spark-submit程序, 作用: 提交指定的Spark代码到Spark环境中运行

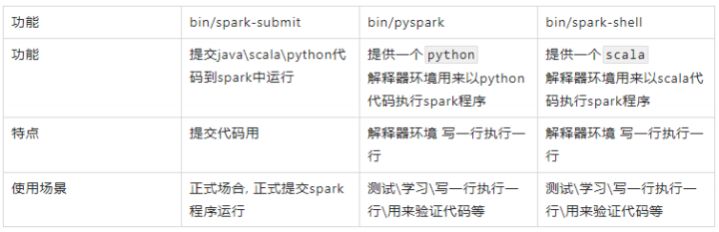
pyspark/spark-shell/spark-submit 对比
以上是关于:Spark环境搭建-Local的主要内容,如果未能解决你的问题,请参考以下文章
大数据分析Hadoop + Spark 10分钟搭建Hadoop(伪分布式 )+ Spark(Local模式)环境