Spark单机伪分布式环境搭建完全分布式环境搭建Spark-on-yarn模式搭建
Posted 遇安.YuAn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark单机伪分布式环境搭建完全分布式环境搭建Spark-on-yarn模式搭建相关的知识,希望对你有一定的参考价值。
搭建Spark需要先配置好scala环境。三种Spark环境搭建互不关联,都是从零开始搭建。
如果将文章中的配置文件修改内容复制粘贴的话,所有配置文件添加的内容后面的注释记得删除,可能会报错。保险一点删除最好。
Scala环境搭建
上传安装包解压并重命名
rz上传
如果没有安装rz可以使用命令安装:
yum install -y lrzsz
这里我将scala解压到/opt/module目录下:
tar -zxvf /opt/tars/scala-2.12.0.tgz -C /opt/module
重命名:
mv scala-2.12.0 scala
2、vi /etc/profile
在最后添加:
export SCALA_HOME=/opt/module/scala
export PATH=$PATH:$SCALA_HOME/bin
刷新使文件生效:
source /etc/profile
搭建单机伪分布式环境(单机)
spark单机伪分布是在一台机器上既有Master,又有Worker进程。spark单机伪分布式环境可以在hadoop伪分布式的基础上进行搭建
上传安装包解压并重命名
rz上传
解压:
tar -zxvf /opt/tars/spark-3.1.1-bin-hadoop3.2.tgz -C /opt/module
重命名:
mv spark-3.1.1-bin-hadoop3.2 spark
进入spark/conf,将spark-env.sh.template 重命名为spark-env.sh
cd /opt/module/spark/conf
mv spark-env.sh.template spark-env.sh
打开spark-env.sh:
vi spark-env.sh
在末尾添加:
export JAVA_HOME=/opt/module/jdk # java的安装路径
export HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop # hadoop的安装路径
export HADOOP_HOME=/opt/module/hadoop # hadoop配置文件的路径
export SPARK_MASTER_IP=master # spark主节点的ip或机器名
export SPARK_LOCAL_IP=master # spark本地的ip或机器名
4、vi /etc/profile
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
刷新:
source /etc/profile
5、切换到/sbin目录下,启动集群:
cd /opt/module/spark/sbin
./start-all.sh
6、通过jps查看进程,既有Master进程又有Worker进程
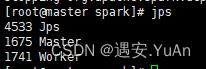
搭建完全分布式环境
搭建Spark完全分布式环境的前提是已经搭建好了hadoop完全分布式,如果没有搭建hadoop完全分布式且不会搭建,可以前往博主主页寻找hadoop完全分布式搭建的文章进行搭建。
博主的三台机器名:主节点:master,从节点:slave1,slave2
1、上传安装包解压并重命名(前面已经讲解过,就不多说了)
2、进入spark/conf,将spark-env.sh.template 重命名 spark-env.sh
cd /opt/module/spark/conf
mv spark-env.sh.template spark-env.sh
3、vi spark-env.sh,在末尾添加:
export JAVA_HOME=/opt/module/jdk # java的安装路径
export HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop # hadoop配置文件的路径
export SPARK_MASTER_IP=master # spark主节点的ip或机器名
export SPARK_MASTER_PORT=7077 # spark主节点的端口号
export SPARK_WORKER_MEMORY=512m # Worker节点能给予Executors的内存数
export SPARK_WORKER_CORES=1 # 每台节点机器使用核数
export SPARK_EXECUTOR_MEMORY=512m # 每个Executors的内存
export SPARK_EXCUTOR_CORES=1 # Executors的核数
export SPARK_WORKER_INSTANCES=1 # 每个节点的Worker进程数
4、spark2.x是配置slaves文件,将slaves.template重命名为slaves
mv slaves.template slaves
添加三个节点的机器名(如果只要两个work的话可以不写master):
vi slaves
master
slave1
slave2
spark3.x是配置works文件:
mv works.template works
vi works
master
slave1
slave2
5、配置spark-default.conf文件,将spark-defaults.conf.template重命名为spark-default.conf:
mv spark-defaults.conf.template spark-default.conf
修改配置文件:
vi /opt/module/spark/conf/spark-default.conf
spark.master spark://master:7077 <!--spark主节点所在机器及端口,默认写法是spark://-->
spark.eventLog.enabled true <!--是否打开任务日志功能,默认为false,即打不开-->
spark.eventLog.dir hdfs://master:8020/spark-logs <!--任务日志默认存放位置,配置一个HDFS路径即可-->
spark.history.fs.logDirectory hdfs://master:8020/spark-logs <!--存放历史应用日志文件的目录-->
注意:8020是HDFS的连接端口,需要填自己的,可以去hadoop的webui查看,hadoop2.x端口是50070,hadoop3.x端口是9870
6、分发:
scp -r /opt/module/spark slave1:/opt/module
scp -r /opt/module/spark slave2:/opt/module
7、创建spark-logs目录
hdfs dfs -mkdir /spark-logs
8、vi /etc/profile
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
刷新:
source /etc/profile
9、分发:
scp -r /etc/profile slave1:/etc
scp -r /etc/profile slave2:/etc
刷新使文件生效:
source /etc/profile
进入Spark的/sbin目录下,启动Spark独立集群
cd /opt/module/spark/sbin
sbin/start-all.sh
启动历史服务器(可以不启动,不启动则没有HistoryServer进程)
sbin/start-history-server.sh
通过jps查看进程:
master节点:
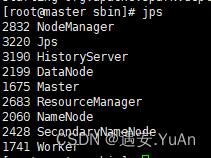
slave1/slave2节点:
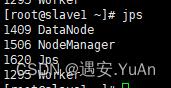
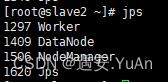
完成以上步骤,Spark环境则搭建完成。
可以通过http://master:8080访问主节点,可以看到webui的监控画面
http://master:18080可以看到历史任务
启动Spark交互页面:
bin/spark-shell
启动YARN客户端模式:bin/spark-shell --master yarn-client
启动YARN集群模式:bin/spark-shell --master yarn-cluster
Spark on Yarn模式
1、解压并重命名:
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-yarn
2、修改hadoop配置文件yarn-site.xml并分发
vi /opt/module/hadoop/etc/hadoop/yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,
如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,
如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
分发:
scp -r /opt/module/hadoop/etc/hadoop/yarn-site.xml slave1:/opt/module/hadoop/etc/hadoop/
scp -r /opt/module/hadoop/etc/hadoop/yarn-site.xml slave2:/opt/module/hadoop/etc/hadoop/
3、修改spark-yarn/conf/spark-env.sh配置文件:
vi /opt/module/spark-yarn/conf/spark-env.sh
export JAVA_HOME=/opt/module/jdk
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
4、vi /etc/profile
export SPARK_HOME=/opt/module/spark-yarn
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
刷新:
source /etc/profile
5、分发:
scp -r /etc/profile slave1:/etc
scp -r /etc/profile slave2:/etc
刷新使文件生效:
source /etc/profile
完成以上步骤,Spark-on-yarn便搭建完成了
时间同步
在跑任务时可能会报错:
Note: System times on machines may be out of sync. Check system time and time zones.
这个是因为三台机子时间不同步的原因
安装NTP服务(三个机子都要):
yum install ntp
手动同步时间(三个机子都要):
ntpdate -u ntp1.aliyun.com
以上是关于Spark单机伪分布式环境搭建完全分布式环境搭建Spark-on-yarn模式搭建的主要内容,如果未能解决你的问题,请参考以下文章