大数据相关组件
Posted 池佳齐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据相关组件相关的知识,希望对你有一定的参考价值。
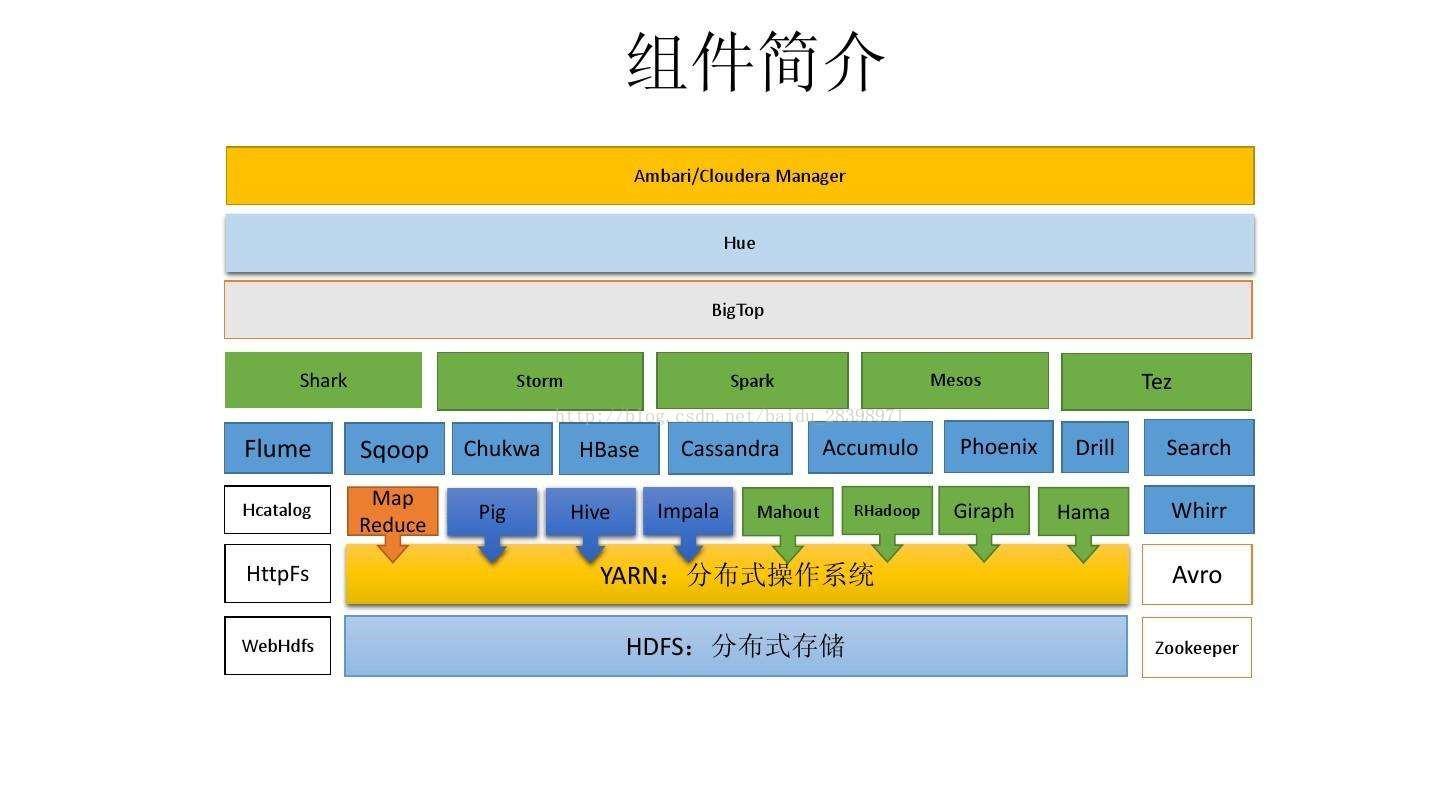
一、 HDFS
HDFS是hadoop的核心组件,HDFS上的文件被分成块进行存储,默认块的大小是64M,块是文件存储处理的逻辑单元。
HDFS是Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,管理数据块映射,处理客户端的读写请求,配置副本策略,管理HDFS的名称空间;
SecondaryNameNode:是NameNode的冷备份,分担NameNode的工作量,合并fsimage和fsedits然后再发给NameNode,定期同步元数据映像文件和修改日志,当NameNode发生故障时,备份转正。
DataNode:是Slave节点,负责存储client发来的数据块block,执行数据块的读写操作,定期向NameNode发送心跳信息。
特点:
数据冗余,硬件容错,每个数据块有三个备份;
流式的数据访问,数据写入不易修改;
适合存储大文件,小文件会增加NameNode的压力。
适合数据批量读写,吞吐量高;
不适合做交互式应用,低延迟很难满足;
适合一次写入多次读取,顺序读写;
不支持多用户并发写相同文件。
二、 MapReduce
MapReduce的工作原理用一句话概括就是,分而治之,然后归约,即将一个大任务分解为多个小任务(map),并行执行后,合并结果(reduce)。
整个MapReduce的过程大致分为Map-->Shuffle(排序)-->Combine(组合)-->Reduce。
三、 YARN
YARN是Hadoop 2.0中的资源管理系统,它的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:
全局的资源管理器ResourceManager,负责整个系统的资源管理和分配
每个应用程序特有的ApplicationMaster,负责单个应用程序的管理。
四、 Hive
Hive是构建在Hadoop HDFS上的一个数据仓库,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能,其本质是将SQL转换为MapReduce程序。
Hive的表其实就是HDFS的目录/文件。
五、Hbase
是一个领先的No-SQL数据库,它在HDFS上存储数据,是面向列的数据库
六、Spark
是一个快速、通用的大规模数据处理引擎 (基于scala开发)
1、spark rdd:弹性分布式数据集
2、spark sql:Spark中结构化数据处理模块。使用Spark SQL提供的接口
3、spark streaming:spark实时计算引擎
4、spark graphx: spark图形数据库
5、spark mLlib:spark机器学习
七、Flink
Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架
以上是关于大数据相关组件的主要内容,如果未能解决你的问题,请参考以下文章