图文详解一文全面彻底搞懂HBaseLevelDBRocksDB等NoSQL背后的存储原理:LSM-tree日志结构合并树...
Posted 禅与计算机程序设计艺术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图文详解一文全面彻底搞懂HBaseLevelDBRocksDB等NoSQL背后的存储原理:LSM-tree日志结构合并树...相关的知识,希望对你有一定的参考价值。

LSM 树广泛用于数据存储,例如 RocksDB、Apache AsterixDB、Bigtable、HBase、LevelDB、Apache Accumulo、SQLite4、Tarantool、WiredTiger、Apache Cassandra、InfluxDB和ScyllaDB等。
在这篇文章中,我们将深入探讨 Log Structured Merge Tree ,又名 LSM 树:许多高度可扩展的 NoSQL 分布式键值类型数据库(如 Amazon 的 DynamoDB、Cassandra 和 ScyllaDB)的数据结构。
众所周知,这些数据库在设计上支持的写入速率远远超过传统关系数据库所能提供的。
These databases by design are known to support write rates far more than what traditional relational databases can offer.
我们将看到 LSM 树如何使他们能够实现他们声称的写入速度,以及它们如何促进读取。
We'll see how LSM Tree enables them to allow the write speeds that they claim, as well as how they facilitate reads.
什么是 LSM 树?
典型的数据库管理系统(简称 DBMS)由多个组件组成,每个组件负责处理数据存储、检索和管理的不同方面。
A typical Database Management System (DBMS in short) consists of multiple components, each responsible for handling different aspects of data storage, retrieval and management.
一个这样的组件是存储引擎,它负责提供可靠的接口,以便从底层存储设备高效地读取和写入数据。
One such component is the storage engine which is responsible for providing a reliable interface for reading and writing data efficiently from/to the underlying storage device.
它是实现数据库四大要求中的两个的组件,即 ACID 属性:A tomicity 和D耐用性。
It's the component that implements the two among the four big asks of databases ie, the ACID properties: A tomicity and D urability
除此之外,存储引擎的性能在选择数据库时也很重要,因为它是最接近正在使用的存储设备的组件。
In addition to that, the performance of a storage engine matters a lot in the choice of a database as it's the component that's closest to the storage device in use.
实现存储引擎的两种流行的数据结构是 B+ 树和 LSM 树。
Two popular data structures for implementing storage engines are B+ Trees and LSM Trees.
几乎所有 NoSQL 数据库都使用 LSM Tree 的变体作为其底层存储引擎,因为它允许它们实现快速的写入吞吐量和对主键的快速查找。
Almost all NoSQL databases use a variant of LSM Tree as their underlying storage engine, because it allows them to achieve fast write throughput and fast lookups on the primary key.
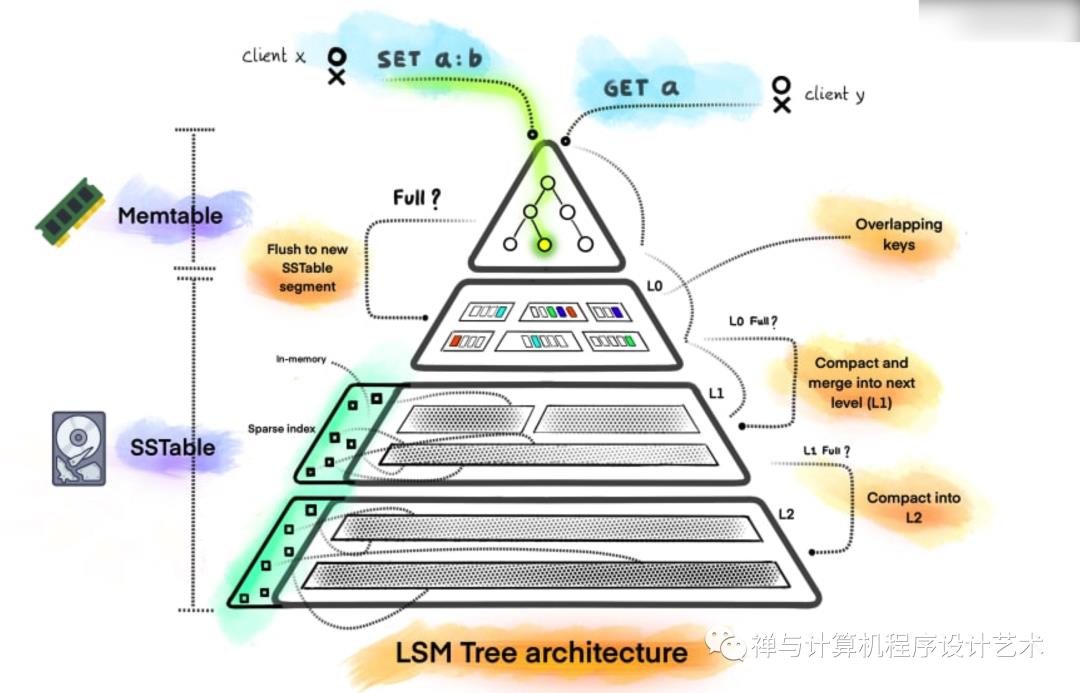
LSM 树也越来越受欢迎,因为存储设备的物理设计从旋转磁盘到 NAND 闪存 SSD 和最近的 NVDIMM,如英特尔傲腾。传统的存储引擎(基于 B+ 树)是为旋转磁盘设计的,写入速度很慢,并且只提供基于块的寻址。然而,今天的应用程序是写入密集型的,并且会生成大量数据。因此,需要重新考虑 DBMS 中现有存储引擎的设计。英特尔傲腾和其他 NVM 等新存储设备提供字节寻址能力并且比 SSD 更快。这导致了诸如Nova之类的探索,它是一个用于持久内存的日志结构文件系统。
LSM Trees are also gaining popularity as storage devices advance in their physical design from spinning disks to NAND flash SSDs and recently NVDIMMs such as Intel Optane. Traditional storage engines (based on B+ Trees) are designed for spinning disks, are slow in writes and offer only block based addressing. Today's applications, however, are write intensive and generate high volumes of data. As a result, there's a need to rethink the design of existing storage engines in DBMSs. New storage devices such as Intel Optane and other NVMs offer byte addressibility and are faster than SSDs. This has led to explorations such as Nova which is a log structured file system for persistant memory.
除此之外,学习 LSM 树是进入复杂的数据库存储引擎内部世界的最快方法。它们在设计上比基于 B+ 树的存储引擎非常简单。因此,如果您对 NoSQL 数据库如何存储数据感兴趣,或者正在尝试实现存储引擎,请继续阅读!
In addition to that, learning about LSM Trees is the fastest way to get into the complicated world of database storage engine internals. They are very simple in design than B+ Tree based storage engines. So if you're someone interested in how NoSQL databases store your data, or are trying to implement a storage engine, continue reading!
B tree 与 B+ tree
B-Tree: B-Tree 被称为自平衡树,因为它的节点在中序遍历中排序。在 B-tree 中,一个节点可以有两个以上的子节点。B-tree 的高度为 logM N(其中“M”是树的顺序,N 是节点数)。每次更新都会自动调整高度。在 B-tree 中,数据按特定顺序排序,最小值在左侧,最大值在右侧。在 B-tree 中插入数据或键比二叉树更复杂。B-Tree必须满足一些条件:
B树的所有叶子节点必须在同一层级。
在 B 树的叶子节点之上,不应该有空的子树。
B-树的高度应该尽可能低。
B+ 树,通过仅在树的叶节点处存储数据指针,消除了 B-树用于索引的缺点。因此,B+树的叶子节点的结构与B树的内部节点的结构有很大的不同。这里可以注意到,由于数据指针只存在于叶节点,叶节点必须将所有的键值连同它们对应的指向磁盘文件块的数据指针一起存储,以访问它们。此外,叶节点被链接以提供对记录的有序访问。因此,叶节点形成索引的第一级,内部节点形成多级索引的其他级别。叶节点的一些键值也出现在内部节点中,只是作为一种媒介来控制记录的搜索。
让我们看看B-tree和B+树的区别:
| 比较项 | B树 | B+树 |
|---|---|---|
| 指针 | 所有内部和叶节点都有数据指针 | 只有叶节点有数据指针 |
| 搜索 | 由于并非所有键都在叶中可用,因此搜索通常需要更多时间。 | 所有的键都在叶节点,因此搜索更快更准确。 |
| 冗余键 | 树中没有保留键的副本。 | 保留密钥的副本,并且所有节点都存在于叶子中。 |
| 插入 | 插入需要更多时间,而且有时无法预测。 | 插入更容易,结果始终相同。 |
| 删除 | 内部节点的删除非常复杂,树必须经历很多变换。 | 删除任何节点都很容易,因为所有节点都在叶子上找到。 |
| 叶节点 | 叶节点不存储为结构链表。 | 叶节点存储为结构链表。 |
| 使用权 | 无法顺序访问节点 | 可以像链表一样顺序访问 |
| 高度 | 对于特定数量的节点高度较大 | 对于相同数量的节点,高度小于 B 树 |
| 应用 | 用于数据库、搜索引擎的 B 树 | B+ 树用于多级索引、数据库索引 |
| 节点数 | 任何中间层 'l' 的节点数是 2 l。 | 每个中间节点可以有 n/2 到 n 个子节点。 |
LSM tree 问题场景
传统关系型数据库使用b+ tree或一些变体作为存储结构,能高效进行查找。
但保存在磁盘中时它也有一个明显的缺陷,那就是逻辑上相离很近但物理却可能相隔很远,这就可能造成大量的磁盘随机读写。
随机读写比顺序读写慢很多,为了提升IO性能,我们需要一种能将随机操作变为顺序操作的机制,于是便有了LSM树。LSM树能让我们进行顺序写磁盘,从而大幅提升写操作,作为代价的是牺牲了一些读性能。
关于磁盘IO
磁盘读写时涉及到磁盘上数据查找,地址一般由柱面号、盘面号和块号三者构成。也就是说移动臂先根据柱面号移动到指定柱面,然后根据盘面号确定盘面的磁道,最后根据块号将指定的磁道段移动到磁头下,便可开始读写。
整个过程主要有三部分时间消耗,查找时间(seek time) +等待时间(latency time)+传输时间(transmission time) 。分别表示定位柱面的耗时、将块号指定磁道段移到磁头的耗时、将数据传到内存的耗时。整个磁盘IO最耗时的地方在查找时间,所以减少查找时间能大幅提升性能。
关于磁盘IO这一部分,其实要区别看待。如果采用的是ssd,那么对于任意地址而言,其实寻址时间可以认为是固定的,它与最传统的chs以及lba寻址方式不一样。如果是ssd的话,随机读写和顺序读写,开销差距大吗?
性能比较-机械硬盘
机械硬盘在顺序读写场景下有相当出色的性能表现,但一遇到随机读写性能则直线下降。
顺序读是随机读性能的400倍以上。顺序读能达到84MB/S。
顺序写是随机读性能的100倍以上。顺序写性能能达到79M/S。
原因:是因为机械硬盘采用传统的磁头探针结构,随机读写时需要频繁寻道,也就需要磁头和探针频繁的转动,而机械结构的磁头和探针的位置调整是十分费时的,这就严重影响到硬盘的寻址速度,进而影响到随机写入速度。
性能比较-固态硬盘
顺序读:220.7MB/s。随机读:24.654MB/s。
顺序写:77.2MB/s。随机写:68.910MB/s。
总结:对于固态硬盘,顺序读的速度仍然能达到随机读的10倍左右。但是随机写还是顺序写,差别不大。
LSM tree 特性
LSM树的核心特点是利用 “顺序写” 来提高写性能。
LSM数据存储分为内存和文件两部分。这样的设计,是通过牺牲小部分读性能换来高性能写。LSM树的核心就是放弃部分读能力,换取写入的最大化能力,放弃磁盘读性能来换取写的顺序性。极端的说,基于LSM树实现的HBase的写性能比mysql高了一个数量级,读性能低了一个数量级。
LSM树由Patrick O'Neil等人在论文《The Log-Structured Merge Tree》:https://www.cs.umb.edu/~poneil/lsmtree.pdf , 提出,它实际上不是一棵树,而是2个或者多个树或类似树的结构(注意这点)的集合。下图示出最简单的有2个结构的LSM树。
在LSM树中,最低一级也是最小的C0树位于内存里,而更高级的C1、C2...树都位于磁盘里。数据会先写入内存中的C0树,当它的大小达到一定阈值之后,C0树中的全部或部分数据就会刷入磁盘中的C1树,如下图所示。
由于内存的读写速率都比外存要快非常多,因此数据写入C0树的效率很高。并且数据从内存刷入磁盘时是预排序的,也就是说,LSM树将原本的随机写操作转化成了顺序写操作,写性能大幅提升。不过,它的tradeoff就是牺牲了一部分读性能,因为读取时需要将内存中的数据和磁盘中的数据合并。总体上来讲这种tradeoff还是值得的,因为:
可以先读取内存中C0树的缓存数据。内存的效率很高,并且根据局部性原理,最近写入的数据命中率也高。
写入数据未刷到磁盘时不会占用磁盘的I/O,不会与读取竞争。读取操作就能取得更长的磁盘时间,变相地弥补了读性能差距。
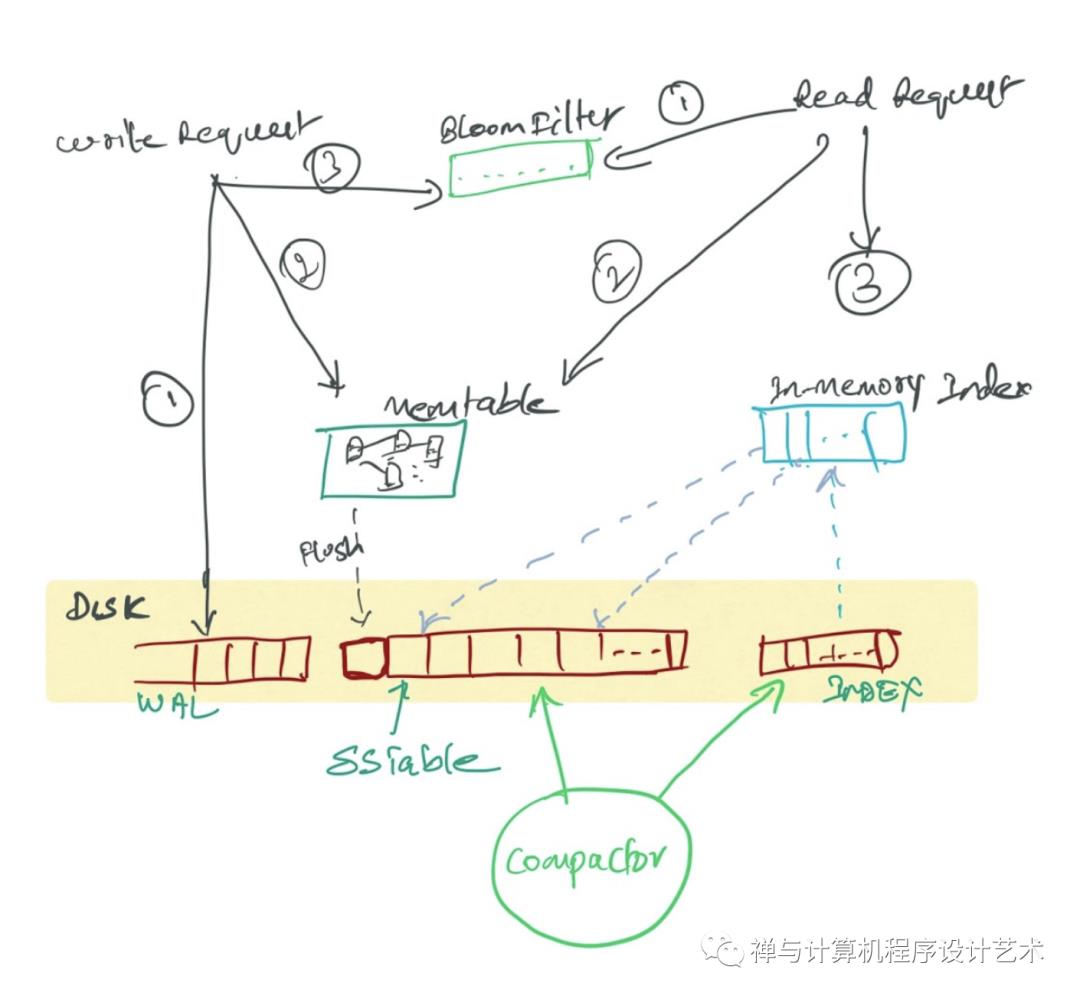
在实际应用中,为了防止内存因断电等原因丢失数据,写入内存的数据同时会顺序在磁盘上写日志,类似于我们常见的预写日志(WAL),这就是LSM这个词中Log一词的来历。另外,如果有多级树的话,低级的树在达到大小阈值后也会在磁盘中进行合并,如下图所示。
RocksDB 的架构图:
LSM树有以下三个重要组成部分:
1) MemTable
MemTable是在内存中的数据结构,用于保存最近更新的数据,会按照Key有序地组织这些数据,LSM树对于具体如何组织有序地组织数据并没有明确的数据结构定义,例如Hbase使跳跃表来保证内存中key的有序。
因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过WAL(Write-ahead logging,预写式日志)的方式来保证数据的可靠性。
2) Immutable MemTable
当 MemTable达到一定大小后,会转化成Immutable MemTable。Immutable MemTable是将转MemTable变为SSTable的一种中间状态。写操作由新的MemTable处理,在转存过程中不阻塞数据更新操作。
3) SSTable (Sorted String Table,排序字符串表)
Sorted Strings Table (borrowed from google) is a file of key/value string pairs, sorted by keys.
"An SSTable provides a persistent,ordered immutable map from keys to values, where both keys and values are arbitrary byte strings. Operations are provided to look up the value associated with a specified key, and to iterate over all key/value pairs in a specified key range. Internally, each SSTable contains a sequence of blocks (typically each block is 64KB in size, but this is configurable). A block index (stored at the end of the SSTable) is used to locate blocks; the index is loaded into memory when the SSTable is opened. A lookup can be performed with a single disk seek: we first find the appropriate block by performing a binary search in the in-memory index, and then reading the appropriate block from disk. Optionally, an SSTable can be completely mapped into memory, which allows us to perform lookups and scans without touching disk."
SSTable (directly mapped to GFS) is key-value based immutable storage. It stores chunks of data, each is of 64KB.
SSTable Definitions:
Index of the keys: key and starting location
Chunk is a storage unit in GFS, replica management are by chunk
有序键值对集合,是LSM树组在磁盘中的数据结构。为了加快SSTable的读取,可以通过建立key的索引以及布隆过滤器来加快key的查找。
https://www.mauriciopoppe.com/notes/computer-science/data-structures/memtable-sstable/
Memtable
In-memory data structure that holds data before it’s flushed into an SStable, the implementation may use a RB Tree, a skiplist, a HashLinkList
SSTable
An immutable data structure that stores a large number of key:value pairs sorted by key
Advantages over simple hash indexes
Merging SSTables is similar to doing a merge sort
To find if a key exists we don’t need an index of all the keys in memory, instead we can keep an index for every few kilobytes and then perform a scan (sparse index)
range queries can be compressed before writing to disk, the sparse index would only need to find the starting position of the compressed segment
References
https://github.com/facebook/rocksdb/wiki/MemTable
https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/
这里需要关注一个重点,LSM树(Log-Structured-Merge-Tree)正如它的名字一样,LSM树会将所有的数据插入、修改、删除等操作记录(注意是操作记录)保存在内存之中,当此类操作达到一定的数据量后,再批量地顺序写入到磁盘当中。这与B+树不同,B+树数据的更新会直接在原数据所在处修改对应的值,但是LSM数的数据更新是日志式的,当一条数据更新是直接append一条更新记录完成的。这样设计的目的就是为了顺序写,不断地将Immutable MemTable flush到持久化存储即可,而不用去修改之前的SSTable中的key,保证了顺序写。
因此当MemTable达到一定大小flush到持久化存储变成SSTable后,在不同的SSTable中,可能存在相同Key的记录,当然最新的那条记录才是准确的。这样设计的虽然大大提高了写性能,但同时也会带来一些问题:
1)冗余存储,对于某个key,实际上除了最新的那条记录外,其他的记录都是冗余无用的,但是仍然占用了存储空间。因此需要进行Compact操作(合并多个SSTable)来清除冗余的记录。
2)读取时需要从最新的倒着查询,直到找到某个key的记录。最坏情况需要查询完所有的SSTable,这里可以通过前面提到的索引/布隆过滤器来优化查找速度。
SSTable 数据模型
SSTable 中的数据按主键排序后存放在连续的数据块(Block)中,块之间也有序。接着,存放数据块索引,由每个 Block 最后一行的主键组成,由于数据查询中的Block定位。接着,存放布隆过滤器和表格的 Schema 信息。最后,存放固定大小的 Trailer 以及 Trailer 的偏移位置。
查找 SSTable 时,首先从子表的索引信息中读取 SSTable Trailer 的偏移位置,接着获取 Trailer 信息。根据 Trailer 中记录的信息,可以获取块索引的大小和偏移,从而将整个块索引加载到内存中。根据块索引记录的每个 Block 的最后一行的主键,可以通过二分查找定位到查找的 Block。最后将 Block 加载到内存中,通过二分查找 Block 中记录的行索引查找到具体某一行。本质上看,SSTable 是一个两级索引结构:块索引以及行索引;而整个 ChunkServer 是一个三级索引结构:子表索引、块索引以及行索引。
SSTable 分为两种格式:稀疏格式和稠密格式。对于稀疏格式,某些列可能存在,也可能不存在,因此,每一行只存储包含实际值的列,每一列存储的内容为:<列ID,列值>(<Column ID, Column Value>); 而稠密格式中每一行都需要存储所有列,每一列只需要存储列值,不需要存储列 ID,这是因为列 ID 可以从表格 Schema 中获取。
SSTable 文件的内容分为 5 个部分,Footer、IndexBlock、MetaIndexBlock、FilterBlock 和 DataBlock。其中存储了键值对内容的就是 DataBlock,存储了布隆过滤器二进制数据的是 FilterBlock,DataBlock 有多个,FilterBlock 也可以有多个,但是通常最多只有 1 个,之所以设计成多个是考虑到扩展性,也许未来会支持其它类型的过滤器。另外 3 个部分为管理块,其中 IndexBlock 记录了 DataBlock 相关的元信息,MetaIndexBlock 记录了过滤器相关的元信息,而 Footer 则指出 IndexBlock 和 MetaIndexBlock 在文件中的偏移量信息,它是元信息的元信息,它位于 sstable 文件的尾部。下面我们至顶向下挨个分析每个结构
Footer 结构
它的占用空间很小只有 48 字节,内部只存了几个字段。下面我们用伪代码来描述一下它的结构
// 定义了数据块的位置和大小
struct BlockHandler
varint offset;
varint size;
struct Footer
BlockHandler metaIndexHandler; // MetaIndexBlock的文件偏移量和长度
BlockHandler indexHandler; // IndexBlock的文件偏移量和长度
byte[n] padding; // 内存垫片
int32 magicHighBits; // 魔数后32位
int32 magicLowBits; // 魔数前32位
复制代码Footer 结构的中间部分增加了内存垫片,其作用就是将 Footer 的空间撑到 48 字节。结构的尾部还有一个 64位的魔术数字 0xdb4775248b80fb57,如果文件尾部的 8 字节不是这个数字说明文件已经损坏。这个魔术数字的来源很有意思,它是下面返回的字符串的前64bit。
$ echo http://code.google.com/p/leveldb/ | sha1sum
db4775248b80fb57d0ce0768d85bcee39c230b61
复制代码IndexBlock 和 MetaIndexBlock 都只有唯一的一个,所以分别使用一个 BlockHandler 结构来存储偏移量和长度。
Block 结构
除了 Footer 之外,其它部分都是 Block 结构,在名称上也都是以 Block 结尾。所谓的 Block 结构是指除了内部的有效数据外,还会有额外的压缩类型字段和校验码字段。
struct Block
byte[] data;
int8 compressType;
int32 crcValue;
每一个 Block 尾部都会有压缩类型和循环冗余校验码(crcValue),这会要占去 5 字节。如果是压缩类型,块内的数据 data 会被压缩。校验码会针对压缩和的数据和压缩类型字段一起计算循环冗余校验和。压缩算法默认是 snappy ,校验算法是 crc32。
crcValue = crc32(data, compressType)在下面介绍的所有 Block 结构中,我们不再提及压缩和校验码。
DataBlock 结构
DataBlock 的大小默认是 4K 字节(压缩前),里面存储了一系列键值对。前面提到 sst 文件里面的 Key 是有序的,这意味着相邻的 Key 会有很大的概率有共同的前缀部分。正是考虑到这一点,DataBlock 在结构上做了优化,这个优化可以显著减少存储空间。
Key = sharedKey + unsharedKeyKey 会划分为两个部分,一个是 sharedKey,一个是 unsharedKey。前者表示相对基准 Key 的共同前缀内容,后者表示相对基准 Key 的不同后缀部分。
比如基准 Key 是 helloworld,那么 hellouniverse 这个 Key 相对于基准 Key 来说,它的 sharedKey 就是 hello,unsharedKey 就是 universe。
DataBlock 中存储的是连续的一系列键值对,它会每隔若干个 Key 设置一个基准 Key。基准 Key 的特点就是它的 sharedKey 部分是空串。基准 Key 的位置,也就是它在块中的偏移量我们称之为「重启点」RestartPoint,在 DataBlock 中会记录所有「重启点」位置。第一个「重启点」的位置是零,也就是 DataBlock 中的第一个 Key。
struct Entry
varint sharedKeyLength;
varint unsharedKeyLength;
varint valueLength;
byte[] unsharedKeyContent;
byte[] valueContent;
struct DataBlock
Entry[] entries;
int32 [] restartPointOffsets;
int32 restartPointCount;
DataBlock 中基准 Key 是默认每隔 16 个 Key 设置一个。从节省空间的角度来说,这并不是一个智能的策略。比如连续 26 个 Key 仅仅是最后一个字母不同,DataBlock 却每隔 16 个 Key 强制「重启」,这明显不是最优的。这同时也意味着 sharedKey 是空串的 Key 未必就是基准 Key。
一个 DataBlock 的默认大小只有 4K 字节,所以里面包含的键值对数量通常只有几十个。如果单个键值对的内容太大一个 DataBlock 装不下咋整?
这里就必须纠正一下,DataBlock 的大小是 4K 字节,并不是说它的严格大小,而是在追加完最后一条记录之后发现超出了 4K 字节,这时就会再开启一个 DataBlock。这意味着一个 DataBlock 可以大于 4K 字节,如果 value 值非常大,那么相应的 DataBlock 也会非常大。DataBlock 并不会将同一个 Value 值分块存储。
FilterBlock 结构
如果没有开启布隆过滤器,FilterBlock 这个块就是不存在的。FilterBlock 在一个 SSTable 文件中可以存在多个,每个块存放一个过滤器数据。不过就目前 LevelDB 的实现来说它最多只能有一个过滤器,那就是布隆过滤器。
布隆过滤器用于加快 SSTable 磁盘文件的 Key 定位效率。如果没有布隆过滤器,它需要对 SSTable 进行二分查找,Key 如果不在里面,就需要进行多次 IO 读才能确定,查完了才发现原来是一场空。布隆过滤器的作用就是避免在 Key 不存在的时候浪费 IO 操作。通过查询布隆过滤器可以一次性知道 Key 有没有可能在里面。
单个布隆过滤器中存放的是一个定长的位图数组,该位图数组中存放了若干个 Key 的指纹信息。这若干个 Key 来源于 DataBlock 中连续的一个范围。FilterBlock 块中存在多个连续的布隆过滤器位图数组,每个数组负责指纹化 SSTable 中的一部分数据。
struct FilterEntry
byte[] rawbits;
struct FilterBlock
FilterEntry[n] filterEntries;
int32[n] filterEntryOffsets;
int32 offsetArrayOffset;
int8 baseLg; // 分割系数
其中 baseLg 默认 11,表示每隔 2K 字节(2<<11)的 DataBlock 数据(压缩后),就开启一个布隆过滤器来容纳这一段数据中 Key 值的指纹。如果某个 Value 值过大,以至于超出了 2K 字节,那么相应的布隆过滤器里面就只有 1 个 Key 值的指纹。每个 Key 对应的指纹空间在打开数据库时指定。
// 每个 Key 占用 10bit 存放指纹信息
options.SetFilterPolicy(levigo.NewBloomFilter(10))这里的 2K 字节的间隔是严格的间隔,这样才可以通过 DataBlock 的偏移量和大小来快速定位到相应的布隆过滤器的位置 FilterOffset,再进一步获得相应的布隆过滤器位图数据。
至于为什么 LevelDB 的布隆过滤器数据不是整个块而是分成一段一段的,这个原因笔者也没有完全整明白。期待有读者可以提供思路。
MetaIndexBlock 结构
MetaIndexBlock 存储了前面一系列 FilterBlock 的元信息,它在结构上和 DataBlock 是一样的,只不过里面 Entry 存储的 Key 是带固定前缀的过滤器名称,Value 是对应的 FilterBlock 在文件中的偏移量和长度。
key = "filter." + filterName
// value 定义了数据块的位置和大小
struct BlockHandler
varint offset;
varint size;
就目前的 LevelDB,这里面最多只有一个 Entry,那么它的结构非常简单,如下图所示
IndexBlock 结构
它和 MetaIndexBlock 结构一样,也存储了一系列键值对,每一个键值对存储的是 DataBlock 的元信息,SSTable 中有几个 DataBlock,IndexBlock 中就有几个键值对。键值对的 Key 是对应 DataBlock 内部最大的 Key,Value 是 DataBlock 的偏移量和长度。不考虑 Key 之间的前缀共享,不考虑「重启点」,它的结构如下图所示
SSTable in Apache Cassandra
SSTable 的组件:
在 Cassandra 中,SSTable 具有多个组件,这些组件存储在多个文件中,如下所示。
LSM树的Compact策略
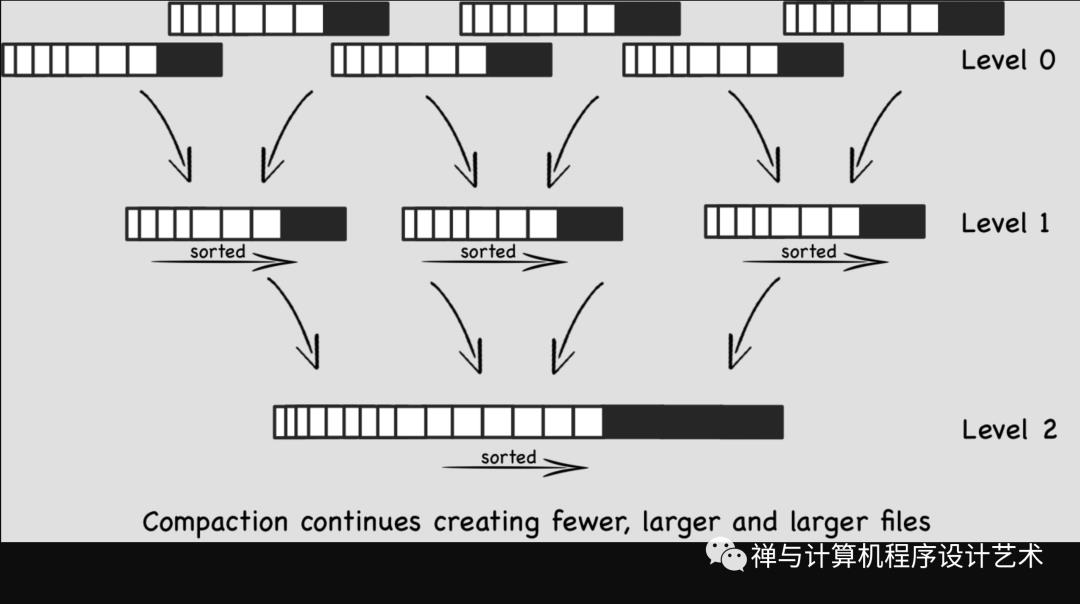
Compact 操作是十分关键的操作,否则SSTable数量会不断膨胀。在Compact策略上,主要介绍两种基本策略:size-tiered和leveled。
不过在介绍这两种策略之前,先介绍三个比较重要的概念,事实上不同的策略就是围绕这三个概念之间做出权衡和取舍。
1)读放大:读取数据时实际读取的数据量大于真正的数据量。例如在LSM树中需要先在MemTable查看当前key是否存在,不存在继续从SSTable中寻找。
2)写放大:写入数据时实际写入的数据量大于真正的数据量。例如在LSM树中写入时可能触发Compact操作,导致实际写入的数据量远大于该key的数据量。
3)空间放大:数据实际占用的磁盘空间比数据的真正大小更多。上面提到的冗余存储,对于一个key来说,只有最新的那条记录是有效的,而之前的记录都是可以被清理回收的。
下面先粗略看看RocksDB的读写流程,其实与HBase是很像的。
RocksDB读写简介
直接上图说明。
RocksDB的写缓存(即LSM树的最低一级)名为memtable,对应HBase的MemStore;读缓存名为block cache,对应HBase的同名组件。
执行写操作时,先同时写memtable与预写日志WAL。memtable写满后会自动转换成不可变的(immutable)memtable,并flush到磁盘,形成L0级sstable文件。sstable即有序字符串表(sorted string table),其内部存储的数据是按key来排序的,后文将其简称为SST。
执行读操作时,会首先读取内存中的数据(根据局部性原理,刚写入的数据很有可能被马上读取),即active memtable→immutable memtable→block cache。如果内存无法命中,就会遍历L0层sstable来查找。如果仍未命中,就通过二分查找法在L1层及以上的sstable来定位对应的key。
随着sstable的不断写入,系统打开的文件就会越来越多,并且对于同一个key积累的数据改变(更新、删除)操作也就越多。由于sstable是不可变的,为了减少文件数并及时清理无效数据,就要进行compaction操作,将多个key区间有重合的sstable进行合并。本文暂无法给出"compaction"这个词的翻译,个人认为把它翻译成“压缩”(compression?)或者“合并”(merge?)都是片面的。
通过上面的简介,我们会更加认识到,LSM树是一种以读性能作为trade-off换取写性能的结构,并且RocksDB中的flush和compaction操作正是LSM思想的核心。下面来介绍LSM-based存储中通用的两种compaction策略,即size-tiered compaction和leveled compaction。
通用compaction策略
size-tiered compaction与空间放大
size-tiered compaction的思路非常直接:每层允许的SST文件最大数量都有个相同的阈值,随着memtable不断flush成SST,某层的SST数达到阈值时,就把该层所有SST全部合并成一个大的新SST,并放到较高一层去。下图是阈值为4的示例。
size-tiered compaction的优点是简单且易于实现,并且SST数目少,定位到文件的速度快。当然,单个SST的大小有可能会很大,较高的层级出现数百GB甚至TB级别的SST文件都是常见的。它的缺点是空间放大比较严重,下面详细说说。
所谓空间放大(space amplification),就是指存储引擎中的数据实际占用的磁盘空间比数据的真正大小偏多的情况。例如,数据的真正大小是10MB,但实际存储时耗掉了25MB空间,那么空间放大因子(space amplification factor)就是2.5。
为什么会出现空间放大呢?很显然,LSM-based存储引擎中数据的增删改都不是in-place的,而是需要等待compaction执行到对应的key才算完。也就是说,一个key可能会同时对应多个value(删除标记算作特殊的value),而只有一个value是真正有效的,其余那些就算做空间放大。另外,在compaction过程中,原始数据在执行完成之前是不能删除的(防止出现意外无法恢复),所以同一份被compaction的数据最多可能膨胀成原来的两倍,这也算作空间放大的范畴。
下面用Cassandra的size-tiered compaction策略举两个例子,以方便理解。每层SST个数的阈值仍然采用默认值4。
以约3MB/s的速度持续插入新数据(保证unique key),时间与磁盘占用的曲线图如下。
图中清晰可见有不少毛刺,这就是compaction过程造成的空间放大。注意在2000s~2500s之间还有一个很高的尖峰,原数据量为6GB,但在一瞬间增长到了12GB,说明Cassandra在做大SST之间的compaction,大SST的缺陷就显现出来了。尽管这只是暂时的,但是也要求我们必须预留出很多不必要的空闲空间,增加成本。
重复写入一个400万条数据的集合(约1.2GB大,保证unique key),共重复写入15次来模拟数据更新,时间与磁盘占用的曲线图如下。
这种情况更厉害,最高会占用多达9.3GB磁盘空间,放大因子为7.75。虽然中途也会触发compaction,但是最低只能压缩到3.5GB左右,仍然有近3倍的放大。这是因为重复key过多,就算每层compaction过后消除了本层的空间放大,但key重复的数据仍然存在于较低层中,始终有冗余。只有手动触发了full compaction(即图中2500秒过后的最后一小段),才能完全消除空间放大,但我们也知道full compaction是极耗费性能的。
接下来介绍leveled compaction,看看它是否能解决size-tiered compaction的空间放大问题。
leveled compaction与写放大
leveled compaction的思路是:对于L1层及以上的数据,将size-tiered compaction中原本的大SST拆开,成为多个key互不相交的小SST的序列,这样的序列叫做“run”。L0层是从memtable flush过来的新SST,该层各个SST的key是可以相交的,并且其数量阈值单独控制(如4)。从L1层开始,每层都包含恰好一个run,并且run内包含的数据量阈值呈指数增长。
下图是假设从L1层开始,每个小SST的大小都相同(在实际操作中不会强制要求这点),且数据量阈值按10倍增长的示例。即L1最多可以有10个SST,L2最多可以有100个,以此类推。
随着SST不断写入,L1的数据量会超过阈值。这时就会选择L1中的至少一个SST,将其数据合并到L2层与其key有交集的那些文件中,并从L1删除这些数据。仍然以上图为例,一个L1层SST的key区间大致能够对应到10个L2层的SST,所以一次compaction会影响到11个文件。该次compaction完成后,L2的数据量又有可能超过阈值,进而触发L2到L3的compaction,如此往复,就可以完成Ln层到Ln+1层的compaction了。
可见,leveled compaction与size-tiered compaction相比,每次做compaction时不必再选取一层内所有的数据,并且每层中SST的key区间都是不相交的,重复key减少了,所以很大程度上缓解了空间放大的问题。重复一遍上一节做的两个实验,曲线图分别如下。
持续写入实验,尖峰消失了。
持续更新实验,磁盘占用量的峰值大幅降低,从原来的9.3GB缩减到了不到4GB。
但是鱼与熊掌不可兼得,空间放大并不是唯一掣肘的因素。仍然以size-tiered compaction的第一个实验为例,写入的总数据量约为9GB大,但是查看磁盘的实际写入量,会发现写入了50个G的数据。这就叫写放大(write amplification)问题。
写放大又是怎么产生的呢?下面的图能够说明。
可见,这是由compaction的本质决定的:同一份数据会不断地随着compaction过程向更高的层级重复写入,有多少层就会写多少次。但是,我们的leveled compaction的写放大要严重得多,同等条件下实际写入量会达到110GB,是size-tiered compaction的两倍有余。这是因为Ln层SST在合并到Ln+1层时是一对多的,故重复写入的次数会更多。在极端情况下,我们甚至可以观测到数十倍的写放大。
写放大会带来两个风险:一是更多的磁盘带宽耗费在了无意义的写操作上,会影响读操作的效率;二是对于闪存存储(SSD),会造成存储介质的寿命更快消耗,因为闪存颗粒的擦写次数是有限制的。在实际使用时,必须权衡好空间放大、写放大、读放大三者的优先级。
RocksDB的混合compaction策略
由于上述两种compaction策略都有各自的优缺点,所以RocksDB在L1层及以上采用leveled compaction,而在L0层采用size-tiered compaction。下面分别来看看。
leveled compaction
当L0层的文件数目达到level0_file_num_compaction_trigger阈值时,就会触发L0层SST合并到L1。
L1层及以后的compaction过程完全符合前文所述的leveled compaction逻辑,如下图所示,很容易理解。
多个compaction过程是可以并行进行的,如下图所示。最大并行数由max_background_compactions参数来指定。
前面说过,leveled compaction策略中每一层的数据量是有阈值的,那么在RocksDB中这个阈值该如何确定呢?需要分两种情况来讨论。
参数
level_compaction_dynamic_level_bytes为false
这种情况下,L1层的大小阈值直接由参数max_bytes_for_level_base决定,单位是字节。各层的大小阈值会满足如下的递推关系:
target_size(Lk+1) = target_size(Lk) * max_bytes_for_level_multiplier * max_bytes_for_level_multiplier_additional[k]
其中,max_bytes_for_level_multiplier是固定的倍数因子,max_bytes_for_level_multiplier_additional[k]是第k层对应的可变倍数因子。举个例子,假设max_bytes_for_level_base = 314572800,max_bytes_for_level_multiplier = 10,所有max_bytes_for_level_multiplier_additional[k]都为1,那么就会形成如下图所示的各层阈值。
可见,这与上文讲leveled compaction时的示例是一个意思。
参数
level_compaction_dynamic_level_bytes为true
这种情况比较特殊。最高一层的大小不设阈值限制,亦即target_size(Ln)就是Ln层的实际大小,而更低层的大小阈值会满足如下的倒推关系:
target_size(Lk-1) = target_size(Lk) / max_bytes_for_level_multiplier
可见,max_bytes_for_level_multiplier的作用从乘法因子变成了除法因子。特别地,如果出现了target_size(Lk) < max_bytes_for_level_base / max_bytes_for_level_multiplier的情况,那么这一层及比它低的层就都不会再存储任何数据。
举个例子,假设现在有7层(包括L0),L6层已经存储了276GB的数据,并且max_bytes_for_level_base = 1073741824,max_bytes_for_level_multiplier = 10,那么就会形成如下图所示的各层阈值,亦即L5~L1的阈值分别是27.6GB、2.76GB、0.276GB、0、0。
可见,有90%的数据都落在了最高一层,9%的数据落在了次高一层。由于每个run包含的key都是不重复的,所以这种情况比上一种更能减少空间放大。
universal compaction
universal compaction是RocksDB中size-tiered compaction的别名,专门用于L0层的compaction,因为L0层的SST的key区间是几乎肯定有重合的。
前文已经说过,当L0层的文件数目达到level0_file_num_compaction_trigger阈值时,就会触发L0层SST合并到L1。universal compaction还会检查以下条件。
空间放大比例
假设L0层现有的SST文件为(R1, R1, R2, ..., Rn),其中R1是最新写入的SST,Rn是较旧的SST。所谓空间放大比例,就是指R1~Rn-1文件的总大小除以Rn的大小,如果这个比值比max_size_amplification_percent / 100要大,那么就会将L0层所有SST做compaction。相邻文件大小比例
有一个参数size_ratio用于控制相邻文件大小比例的阈值。如果size(R2) / size(R1)的比值小于1 + size_ratio / 100,就表示R1和R2两个SST可以做compaction。接下来继续检查size(R3) / size(R1 + R2)是否小于1 + size_ratio / 100,若仍满足,就将R3也加入待compaction的SST里来。如此往复,直到不再满足上述比例条件为止。
当然,如果上述两个条件都没能触发compaction,该策略就会线性地从R1开始合并,直到L0层的文件数目小于level0_file_num_compaction_trigger阈值。
重新审视 B+ tree 与 LSM tree
作为最广泛使用的索引数据结构之一,B + -tree [3] 为当今几乎所有的关系数据库管理系统 (RDBM) 提供支持。最近,日志结构合并树(LSM-tree)[5] 作为 B + -tree的竞争者引起了极大的兴趣,因为它的数据结构可以实现更好的存储空间使用效率和更低的写入放大。由于这两个广为人知的优势,LSM-trees 已被许多 NoSQL 产品(例如,Google 的 BigTable、Cassandra 和 RocksDB)采用。我们研究了 LSM-tree 相对于 B + -tree的这两个优势是否仍然存在于具有内置透明压缩的新存储硬件的存在下。
透明压缩
基于硬件的数据压缩能力在现代存储设备和基础设施上变得越来越广泛,例如,具有内置透明压缩功能的商用固态驱动器 (SSD) 正在兴起 [8],大多数全闪存阵列 (AFA) [2 , 4, 6] 透明地压缩他们的数据,并且云供应商已经开始将基于硬件的压缩能力集成到他们的存储基础设施中(例如,Microsoft Corsia [1])。图 1 展示了内置透明压缩的 SSD:其控制器芯片对 I/O 路径上的每个 4KB LBA(逻辑块地址)块进行压缩或解压缩,这对于正常访问 SSD 的主机是透明的块设备通过标准接口(例如,NVMe)。
为了让主机实现存储内透明压缩的好处,此类 SSD 可能会暴露比其内部物理存储容量大得多的稀疏 LBA 空间。此外,由于可以高度压缩重复的数据模式(例如,全零或全一),主机可以在每个 4KB LBA 块中存储稀疏数据内容(即任意数量的有效数据),而不会浪费物理存储空间,如图 2 所示。因此,当使用内置透明压缩的 SSD 时,我们可以在不牺牲真实物理存储成本的情况下采用稀疏的磁盘数据结构,这为数据管理系统创造了新的设计空间范围 [ 9]。
B+ 树与 LSM 树:存储成本
我们首先研究 B + -tree 和 LSM-tree的存储成本比较。B + -tree 以页为单位管理其数据存储。为了降低数据存储成本,B + -tree 可以应用块压缩算法(例如,lz4、zlib 和 ZSTD)来压缩每个存储页面(例如,MySQL 和 MongoDB/WiredTiger 中的页面压缩功能)。除了明显的 CPU 开销外,B + -tree 页面压缩还会因为 4KB-alignment 约束而遭受压缩比损失,这可以解释如下:存储设备以 4 KB LBA 块为单位服务 I/O 请求。结果,每个 B +-树页面(无论压缩或未压缩)必须完全占据存储设备上的一个或多个 4 KB LBA 块。当 B + -tree 应用页面压缩时,4KB 对齐约束可能会导致明显的存储空间浪费。这可以在图3中进一步说明:假设一个16KB的B + -tree页面被压缩到5KB,压缩后的页面必须占用存储设备上的两个LBA块(即8KB),浪费了3KB的存储空间。因此,由于 4 KB-alignment 约束带来的 CPU 开销和存储空间浪费,B + -tree 页面压缩在生产环境中并没有被广泛使用。同时,在随机写入的工作负载下,B + -tree 页面往往只有 50%∼80% 满 [3]。因此,B +-tree 通常具有较低的存储空间使用效率。
与 B + -tree 相比,LSM-tree 具有更高的存储空间使用效率,可以解释如下:一个 LSM-tree 由多个不可变的 SSTable 文件组成,每个文件包含多个块(典型块大小为 4 KB )。由于是不可变的,所有块都可以 100% 填满(即,完全填满用户数据)。在应用压缩以降低存储成本时,LSM-tree 单独压缩每个块并将压缩块紧密地打包在 SSTable 文件中(即,压缩块不受 4 KB 对齐约束)。出于演示的目的,我们使用 RocksDB 和 WiredTiger 作为 LSM-tree 和 B + -tree 的代表,并在 150 GB 数据集上运行具有 128 字节记录大小的随机只写工作负载。对于 WiredTiger,我们设置它的 B+ - 树叶页面大小为 8 KB。结果显示,RocksDB 和 WiredTiger 分别在存储设备上占用了 218GB 和 280GB。它清楚地展示了 LSM-tree 更好的存储空间使用效率。
然而,当在内置透明压缩的存储硬件上运行时,LSM-tree 与 B + -tree 的存储成本优势将大大减弱。如图 4 所示,只要 B + - 树页面用全零等高度可压缩的内容填充未使用的空间,存储内透明压缩将消除不太紧凑的 B + -树页面数据结构的存储成本损失. 此外,in-storage 透明压缩不受 4 KB-alignment 约束,即所有压缩数据块都紧密打包在 NAND 闪存中,如图 4 所示。因此,in-storage 透明压缩无缝地缓解了存储B +的使用效率缺点-tree,缩小了 B + -tree 和 LSM-tree之间的存储成本差距。例如,我们在与上述配置相同的内置透明压缩 [8] 的 SSD 上运行 RocksDB 和 WiredTiger,结果表明,存储内透明压缩可以将 RocksDB 的存储成本从 218 GB 降低到 129 GB ,并将WiredTiger的存储成本从280GB降低到104GB。SSD 可以在 WiredTiger 上实现更高的压缩比,因为其不太紧凑的 B +树页面数据结构导致更高的数据压缩率。RocksDB 具有较高的压缩后存储成本主要是因为其固有的空间放大。结果表明,存储内透明压缩有效缩小了 B +之间的存储成本差距-tree 和 LSM-tree。
B+ 树 vs. LSM-tree:写放大
在写入放大方面比较 B + -tree 和 LSM-tree 更加复杂,并且很大程度上取决于运行时工作负载的特征。当 (i) B + -tree 具有非常大的高速缓存内存(例如,足以容纳大部分或整个数据集)并使用非常大的重做日志文件时,B + -tree的写入放大率可能比 LSM-tree 低得多,或 (ii) 平均记录大小很大(例如,512 B 及以上)。这解释了为什么 LSM-tree 通常被用于针对平均记录大小相对较小的内存数据集大得多的系统。
我们感兴趣的是,在那些对 LSM-tree 友好的工作负载(即,记录大小大于内存的数据集)下,存储内透明压缩是否有助于缩小 B + -tree 与 LSM-tree 的写入放大差距。在这种情况下,B + -tree 的写放大主要是由脏页刷新引起的写放大。例如,如果一个 B + -tree 在一个 8 KB 页内修改了一条 32 B 的记录,然后将该脏页从内存刷新到存储,则写入放大将为 8 KB/32 B=256。即使存储硬件可以将页面压缩为 4:1(因此将写入放大减少到 64),它仍然比 LSM-tree 的典型写入放大(例如~20)大得多。因此,关闭 B+ -tree 与 LSM-tree 写入放大差距,必须修改B + -tree 实现以更好地利用存储内透明压缩。我们在下面提出一个解决方案。
这是由一个简单的观察引起的:对于 B + -树页面,让 Δ 表示其内存中图像和存储图像之间的差异。如果差异显着小于页面大小,我们可以通过记录页面修改Δ来大大减少写入放大,而不是将整个内存页面映像写入存储设备。不幸的是,当一个 B +-tree 在没有内置透明压缩的普通存储设备上运行,由于显着的操作开销,这种方法不实用:给定 4 KB 块 IO 接口,我们必须将来自不同页面的多个 Δ 合并为一个 4 KB LBA 块,以便实现写放大减少。为了提高增益,我们应该对每个页面多次应用页面修改日志记录,然后再重置此过程以构建最新的存储页面图像。因此,与同一页面相关联的多个Δ将分布在存储设备上的多个 4 KB 块上,但这会增加数据管理的复杂性和页面读取延迟。结果,这个简单的设计理念并没有被现实世界的B +使用公开文献中报告的树实现。
首次内置透明压缩的存储硬件使上述简单的想法切实可行。通过应用这种存储硬件支持的稀疏数据结构,我们不再需要将来自不同页面的多个 Δ 合并到同一个 4 KB LBA 块中。如图 5 所示,每个 B + -tree 页面关联一个专用的 4 KB LBA 块作为其修改日志空间来存储自己的 Δ,称为本地化页面修改日志。4KB I/O接口下,实现对每页建议的页面修改日志,B +-tree 将 D = [Δ,O](其中 O 表示全零向量,|D| 为 4 KB)写入与页面关联的 4 KB 修改日志块。在存储设备内部,D 中的所有零都将被压缩掉,仅物理存储 Δ 的压缩版本。与传统做法相比,这显然导致写入放大要低得多,传统做法是,无论页面中有多少字节真正改变,每个脏页都完全写入存储。通过为每个 B +树页面专用一个 4 KB 修改日志空间,我们不会产生额外的 B +树存储管理复杂性。当然,这种设计方法会受到较长的页面加载延迟的影响,幸运的是,这并不重要,原因有两个:(i)一个 B +-tree 只需要额外读取一个与 LBA 空间中的页面相邻的 4 KB LBA 块。因此,B + -tree 只向存储设备发出单个读取请求。(ii) 与从存储设备获取数据相比,从 Δ 构建更新的内存页面所需的时间要少得多。
定量结果
出于演示目的,我们实现了一个 B +树,它结合了上述用于减少写入放大的方法。生成的实现称为 B -树。为了比较,RocksDB 和 WiredTiger 被用作 LSM-tree 和 normal B +的代表-树。在所有实验中,每条记录都是通过将其一半内容填充为全零而另一半内容填充为随机字节来生成的,以模拟运行时数据内容的可压缩性。图 6 显示了在 500 GB 数据集下测量的写入放大,其中所有情况都使用 15 GB 缓存。在每个实验中,我们使用 1、2、4、8 或 16 个客户端线程来覆盖各种运行时工作负载并发。与 RocksDB 相比,WiredTiger 的写入放大要大得多,而 B -- tree 基本上可以关闭 B +-tree 与 LSM-tree 写入放大差距。例如,在32B记录大小和4个客户端线程的情况下,RocksDB的写放大为38,而WiredTiger的写放大分别为8 KB页面大小下268和16 KB页面大小下530,为7.1比 RocksDB 大 x 和 13.9 倍。相比之下,B - tree 的写入放大在 8 KB 页面大小下为 28(仅为 RocksDB 写入放大的 73.7%),在 1 6KB 页面大小下为 36(与 RocksDB 几乎相同)。
我们进一步比较了 LBA 空间上的逻辑存储使用量(即存储内压缩之前)和闪存的物理使用量(即存储内压缩之后)的总存储使用量。使用相同的 500 GB 数据集,RocksDB、WiredTiger 和 B - tree 的逻辑存储使用量分别为 728 GB、934 GB 和 1,548 GB。入库压缩后,RocksDB、WiredTiger、B - tree的物理闪存使用量分别为431GB、347GB、452GB 。由于 LSM-tree 的数据结构比 B + -tree更紧凑,因此 RocksDB 的逻辑存储使用量比其他两种更小。由于 B --tree 为每一页分配一个 4KB 的块,以实现本地化的修改日志,其逻辑存储使用量远大于 WiredTiger。WiredTiger 消耗的物理闪存容量比 RocksDB(因为 LSM-tree 的空间放大)和 B - tree(因为页面修改日志记录引起的存储开销)要少。由于页面修改日志造成的存储空间开销,B - tree 的物理存储使用量比 RocksDB 略大。例如,RocksDB 的物理存储使用量为 431 GB,而 B -- tree 的物理存储使用量为 452 GB,仅比 RocksDB 大 5% 左右。
最后,图 7 显示了在三种不同工作负载下测量的速度性能:
(a) 随机点读取,(b) 随机范围扫描,和 (c) 随机点写入。
如图 7(a) 所示,普通的 B + -tree(即 WiredTiger)具有最好的点读 TPS(每秒事务数)性能,而 RocksDB 和 B -- tree 实现了几乎相同的随机点读 TPS 性能。比如在16个客户端线程下,WiredTiger可以达到71K TPS,而RocksDB qnd B -- tree可以达到57K TPS,比WiredTiger低19.7%左右。
图 7(b)显示了运行随机范围扫描查询时测量的 TPS,其中每次范围扫描覆盖 100 个连续记录。与随机点读取的情况相比,WiredTiger 和 B --tree 在范围扫描吞吐量性能方面的差异明显较小。这是因为 B - tree 的两个开销(即,获取额外的 4KB 和内存中的页面重建)可以在每次范围扫描覆盖的记录中分摊。相比之下,RocksDB 的范围扫描吞吐量性能明显低于其他两个,因为范围扫描调用 LSM-tree 中所有级别的读取,导致高读取放大。
图 7(c)显示了随机点写入工作负载下的性能。B + -tree 和 LSM-tree的随机写入速度性能从根本上受到写入放大的限制。因此,通过显着降低写放大,B - -树可以实现更高的写入速度性能。如图 7(C) 所示,B -- tree 的写入吞吐量比 RocksDB 高 19% ,比 WiredTiger 高约 2.1 倍。我们的 FAST'22 论文 [7] 提供了更全面的实验结果。
结论
Modern storage hardware with built-in transparent compression allows data management systems to employ sparse on-disk data structure without sacrificing the true physical data storage cost. This opens a new but largely unexplored spectrum of opportunities to innovate data management software design. As one small step towards exploring this design spectrum, we showed that B+-tree could nicely leverage such modern storage hardware to close the gap with its recent contender LSM-trees in terms of storage cost and write amplification. This work suggests that the arrival of such modern storage hardware warrants a revisit on the role and comparison of B+-tree and LSM-tree in future data management systems.
具有内置透明压缩的现代存储硬件允许数据管理系统采用稀疏的磁盘数据结构,而不会牺牲真正的物理数据存储成本。这为创新数据管理软件设计开辟了一个新的但很大程度上尚未探索的机会范围。作为探索这一设计范围的一小步,我们展示了 B +树可以很好地利用这种现代存储硬件来缩小与最近的竞争者 LSM 树在存储成本和写入放大方面的差距。这项工作表明,这种现代存储硬件的出现需要重新审视 B + -tree 和 LSM-tree 在未来数据管理系统中的作用和比较。
References:
[1] D. Chiou, E. Chung, and S. Carrie. (Cloud) Acceleration at Microsoft. Tutorial at Hot Chips, 2019
[2] Dell EMC PowerMax. https://delltechnologies.com/
[3] G. Graefe and H. Kuno. Modern B-tree techniques. In IEEE International Conference on Data Engineering, 2011
[4] HPE Nimble Storage. https://www.hpe.com/
[5] P. O’Neil, E. Cheng, D. Gawlick, and E. O’Neil. The log-structured merge-tree (LSM-tree). Acta Informatica, 1996
[6] Pure Storage FlashBlade. https://purestorage.com/
[7] Y. Qiao, X. Chen, N. Zheng, J. Li, Y. Liu, and T. Zhang. Closing the B-tree vs. LSM-tree Write Amplification Gap on Modern Storage Hardware with Built-in Transparent Compression. In USENIX Conference on File and Storage Technologies (FAST), 2022
[8] ScaleFlux Computational Storage. http://scaleflux.com
[9] N. Zheng, X. Chen, J. Li, Q. Wu, Y. Liu, Y. Peng, F. Sun, H. Zhong, and T. Zhang. Re-think data management software design upon the arrival of storage hardware with built-in transparent compression. In USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage), 2022
【更多阅读】
以上是关于图文详解一文全面彻底搞懂HBaseLevelDBRocksDB等NoSQL背后的存储原理:LSM-tree日志结构合并树...的主要内容,如果未能解决你的问题,请参考以下文章
图文详解一文全面彻底搞懂HBaseLevelDBRocksDB等NoSQL背后的存储原理:LSM-tree日志结构合并树...