一文彻底搞懂自动机器学习AutoML:EvalML
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文彻底搞懂自动机器学习AutoML:EvalML相关的知识,希望对你有一定的参考价值。
本文将系统全面的介绍自动机器学习的其中一个常用框架: EvalML,一起学习如何在 Python 中将 EvalML 用于 AutoML,并通过一个简单实例说明如何使用EvalML为二分类任务。喜欢本文记得收藏、点赞、关注。
完整版代码、数据、技术交流,文末获取
一般来说,要构建一个更好的机器学习模型,需要数据科学家具备良好的机器学习知识、编程技能、数学(线性代数)专业知识和领域知识。如果你是一个初学者,或对专业领域知识并不是很熟悉,那么要想成为掌握所有这些技能的专家并不总是那么容易。此时使用 AutoML,能够帮助你轻松构建机器学习模型全过程,ML 管道的以下组件可以针对预测建模任务进行优化。
-
数据预处理
-
特征工程/提取和特征选择
-
通过选择合适的模型族/算法进行模型训练
-
超参数调优
-
模型评估
AutoML 优势
-
帮助快速找到良好的 ML 模型管道,减少用户干预。
-
需要编写的代码量更少,这使得建模变得非常容易和快速。
-
提供排行榜以比较给定数据集的各种模型系列/算法。
-
对 ML 初学者、从业者、非专家尤其有益,并允许他们更多地关注问题而不是模型。
有许多可用的开源 AutoML 库/框架,如 Auto-Sklearn、TPOT、PyCaret、H2O AutoML、Hyperopt、Auto-Keras 等。此外,现在许多组织,如谷歌、亚马逊、微软、IBM 等,都提供 AutoML 作为只需单击几下即可下载数据集和良好 ML 模型管道的服务。

在本文中,我们将探索 AutoML大家庭中的一员: EvalML库,并学习如何将其用于二分类任务。
什么是 EvalML
EvalML是一个开源_Python_库,用于自动构建、优化和评估给定数据集的机器学习管道。与任何其他AutoML库一样,它还自动执行数据预处理、特征工程、特征选择、模型构建、超参数调整、交叉验证等。
-
EvalML减少了手动模型训练和调整的过程,这包括数据质量检查和交叉验证。
-
数据检查和预警:EvalML 可帮助你在使用或设置数据进行建模之前识别数据中的异常。
-
管道构建:EvalML 帮助你构建高度优化的管道,包括最先进的数据预处理、特征工程、特征选择和众多建模技术。
-
模型理解:就像 Shap、Eli5、Lime 和其他模型可解释性库一样,EvalML 也提供了对正在构建的模型的可解释性,用于演示目的。
-
特定领域:这是大多数 AutoML 库中缺少的链接,可以在其中定义问题的目标。确定业务目标后,可以通过定义自定义目标函数将其提供给 EvalML 以进行优化。
安装和使用
使用EvalML 时,包括了几个可选的依赖项。如xgboost 和 catboost 包支持围绕这些建模库构建的管道。plotly 和 ipywidgets 包支持 automl 搜索中的绘图功能。这些依赖项是推荐的,默认情况下包含在 EvalML 中,但在安装和使用 EvalML 时并不是必需的。
!pip install evalml
EvalML 支持多种监督学习任务/问题,例如回归、分类(二元和多元)、时间序列分析(包括时间序列回归和分类)。可以使用以下命令获取可用问题类型的完整列表。
import evalml
evalml.problem_types.problem_types.ProblemTypes.all_problem_types

ML 模型通常使用一些评估矩阵来评估。评估矩阵的选择取决于手头问题的类型、数据集、业务约束和需求。
EvalML还包括一个目标函数库(评估方法,如R-squared,precision,recall,F1-score等)。默认情况下,在EvalML实现中,目标函数是分类的log loss和回归问题的R-squared,其他方法也很容易配置。
使用以下命令获取EvalML中可用目标函数的完整列表
evalml.objectives.get_all_objective_names()
加载数据集
在 EvalMl 中加载乳腺癌数据集链接:乳腺癌数据集
import evalml
X, y = evalml.demos.load_breast_cancer()
X_train, X_test, y_train, y_test =
evalml.preprocessing.split_data(X, y, problem_type='binary')
# 这里我们将使用evalml的预处理拆分数据表" split_data”库
注意: EvalML 使用数据表作为标准数据格式,可以读取常规 .csv 数据集并使用 Woodworks进行转换。EvalML 与 pandas DataFrames 能够很好的适配。但使用 DataTable 可以更加容易地控制 EvalML,轻松设置每个特征为数值特征、分类特征、文本特征或其他类型的特征。此外,Woodwork 的 DataTable 包括诸如推断何时应将分类特征视为文本特征的功能。
type(X_train)
woodwork.datatable.DataTable
X_train.head
自动管道搜索
EvalML 有一个名为AutoMLSearch的内置工具,可以使用AutoMLSearch()自动从一系列管道中来搜索最佳管道。EvalML 使用贝叶斯优化根据定义的目标对最佳管道进行排序。
AutoMLSearch不会显式执行各种事情,例如数据预处理(缺失值插补、数据标准化、one-hot 编码等)、 模型训练、评估、超参数调整等。AutoMLSearch会自动执行这些步骤并返回最佳模型管道。
AutoMLSearch还提供大量自定义选项(如问题类型、目标、允许管道、允许模型家庭、集成等)以改进预测结果。
from evalml.automl import AutoMLSearch
automl = AutoMLSearch(X_train=X_train,
y_train=y_train,
problem_type='binary')
在这里,在实例化AutoMLSearch对象时,将训练数据、问题类型作为'binary'传递。
当你在"automl.search()"之后使用search()函数时,就会开始搜索最佳管道。在 EvalML 中不再需要数据整理,可以直接加载数据并在定义特征和结果变量后开始搜索最佳管道,接下来开始寻找最佳管道。
automl.search()
Search finished after 00:16
Best pipeline: Logistic Regression Classifier w/ Imputer + Standard Scaler
Best pipeline Log Loss Binary: 0.094015
所以从上面的代码片段中,得到了最好的管道,即“ Logistic Regression Classifier w/ Imputer + Standard Scaler,Log loss 为 0.094
AutoML 排名
搜索后,我们将根据分数对管道进行排名,为此,我们需要使用一个简单的代码automl.rankings。
automl.rankings
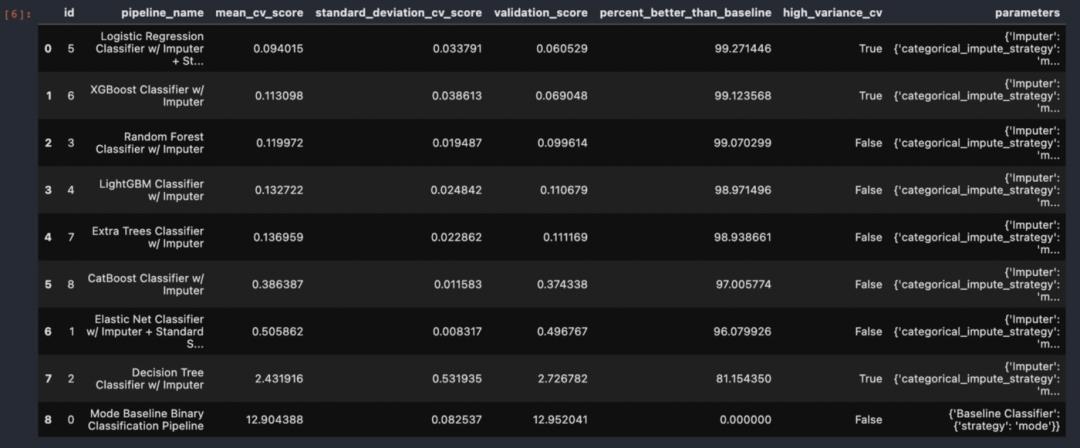
根据表 Logistic Regression 是具有较高mean_cv_score和validation_score的最佳管道,我们现在可以使用automl.describe_pipeline(5)获取管道的描述,其中“5”是管道 ID。
获取管道
检查构建模型所需的最佳管道
pipeline = automl.get_pipeline(1)
print(pipeline.name)
print(pipeline.parameters)
Elastic Net Classifier w/ Imputer + Standard Scaler
'Imputer':
'categorical_impute_strategy': 'most_frequent',
'numeric_impute_strategy': 'mean',
'categorical_fill_value': None,
'numeric_fill_value': None,
'Elastic Net Classifier':
'alpha': 0.5, 'l1_ratio': 0.5,
'n_jobs': -1, 'max_iter': 1000,
'penalty': 'elasticnet', 'loss': 'log'
还可以通过在最佳管道上调用graph()函数来获得管道组件的可视化流程。
best_pipeline = automl.best_pipeline
best_pipeline.graph()

评估测试数据的最佳管道
最佳模型管道在测试数据上的性能,以评估准确性和 F1 分数等评估指标。
通过使用测试数据来评估管道性能
best_pipeline.score(X_test, y_test,
targets=["auc","f1","Precision","Recall"])
OrderedDict([(' AUC ', 0.9933862433862434),
(' F1 ', 0.963855421686747),
(' Precision ', 0.975609756097561),
(' Recall ', 0.9523809523809523)])
更改 EvalML 构建的模型的目标
automl_auc = AutoMLSearch(
X_train=X_train, y_train=y_train,
question_type='binary',
object='auc',
additional_objectives=['f1', 'precision'],
max_batches=1,
optimize_thresholds=True)
automl_auc.search()
Search finished after 00:16
Best pipeline: Extra Trees Classifier w/ Imputer
Best pipeline AUC: 0.992791
优化的目标。用于建议和排名管道,但不用于在 fit-time 期间优化每个管道。当设置为“自动”时,选择:
-
LogLossBinary 用于二进制分类问题,
-
LogLossMulticlass 用于多类分类问题,以及
-
R² 用于回归问题。
保存模型
best_pipeline.save("model.pkl") check_model=automl.load('model.pkl')
评估模型
check_model.predict_proba(X_test).to_dataframe()

到这里我们就学习告一段落了,我们讨论了 AutoML 的框架之一:EvalML,包括它的特性和优势。并通过一个简单实例说明如何使用EvalML为二进制分类任务,并找到一个好的模型管道。
推荐文章
技术交流
欢迎转载、收藏、有所收获点赞支持一下!数据、代码可以找我获取

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

以上是关于一文彻底搞懂自动机器学习AutoML:EvalML的主要内容,如果未能解决你的问题,请参考以下文章