Flink总结之一文彻底搞懂时间和窗口
Posted 数据的小伙伴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink总结之一文彻底搞懂时间和窗口相关的知识,希望对你有一定的参考价值。
Flink总结之一文彻底搞懂时间和窗口
文章目录
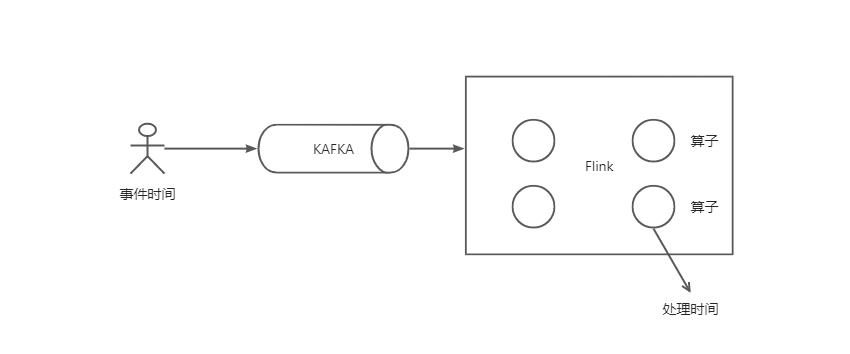
Flink中时间语义是非常丰富的,总共有三种,分别是事件时间(Event Time)、处理时间(Processing Time)和摄入时间(Ingestion Time),丰富的时间语义加上水位线( Watermarks)功能,让我们在处理流式数据更加轻松。
在Flink中窗口也定义的非常全面,有计数窗口(Count Window)和时间窗口(Time Window),在窗口切分上有份滚动窗口(Tumbling Windows)、滑动窗口(Sliding Windows)、会话窗口(Session Windows)和全局窗口全局窗口(Global Windows)。
官方文档地址:链接: Flink文档
一、Flink中时间概念
1. 事件时间(Event Time)
顾名思义,事件时间就是指数据产生的时间,是数据本身的时间属性,不依赖系统时间
2. 处理时间(Processing Time)
处理时间是指数据真正被Flink处理的时间,是服务器时间
3. 摄入时间(Ingestion Time)
它是指数据进入 Flink 数据流的时间,也就是 Source 算子读入数据的时间。摄入时间相当于是事件时间和处理时间的一个中和,它是把 Source 任务的处理时间,当作了数据的产生时间添加到数据里。
二、水位线(Watermark)
1. 什么是水位线
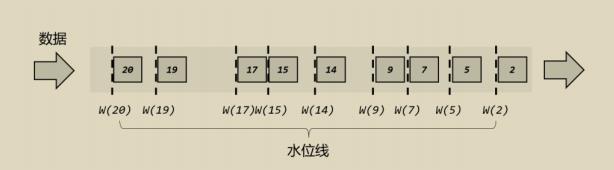
本质就是时间戳,在流式环境下,我们通常用事件时间来进行统计分析,事件时间又不属于系统时间,因此我们怎么衡量时间的进展,就是通过水位线(Watermark)。
如下图所示,Flink处理每一条数据的时候,将会把这个数据的事件时间作为水位线。
2. 水位线分类
1. 有序流中的水位线
有序流中的水位线比较容易理解,事件是按照顺序一个一个到达Flink的,那么水位线只要根据数据自身的事件时间来识别就可以了,水位线会随着时间往前推动,如下图所示:

1、如何使用
2. 乱序流中的水位线
乱序流中的水位线相比较于有序流的场景比较复杂一些,数据是源源不断到达Flink的,此时可能存在后一刻的数据比前一刻的数据先到达Flink,比如:9:00:00整的数据比8:59:59的数据来的要早,如果此时仍然使用有序流中的水位线,那么数据就会不准确,不属于8点到9点的数据被统计到了这个窗口范围,属于这个范围的数据却会丢失。乱序流中水位线如下图所示:
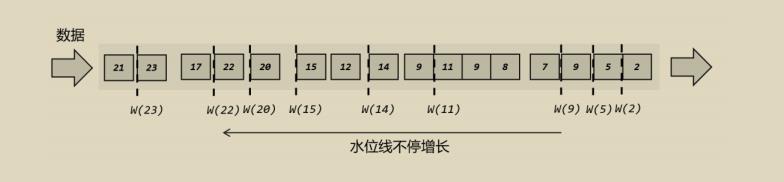
2.1 乱序流中如何保证数据的准确性
那么怎么才能保证乱序流中的水位线也是正确的呢
水位线增加延迟策略,我们设置水位线后增加一个等待时间,比如9:00:00的数据到了我们不结束这个窗口,等待2秒,9:00:02的时候结束,那么就会保证数据尽可能的都在。
至于延迟多久,这是相对的,时间越短,准确性越低,数据的时效性越高,需要根据具体情况设置。
2.2 如何使用
三、窗口
1. 什么是窗口
Flink是一种流式引擎,数据是源源不断到来的,但是我们统计周期往往是有界的,因此在处理数据的时候我们需要把源源不断的数据切分成有界的数据,这就是窗口。
在开发指标中有些定义如下:
- 每分钟的浏览量
- 每位用户每周的会话数
- 每个传感器每分钟的最高温度
每分钟、每周、每分钟的统计数据,这就是窗口。
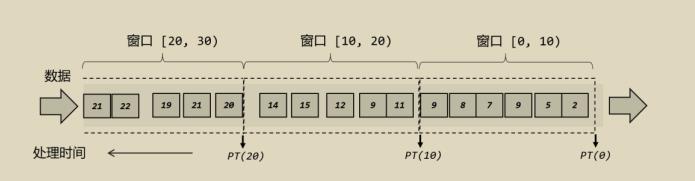
那么在乱序流中,即使数据不是有序到来的,Flink也可以正确的把数据分到对应的窗口中,在Flink中,每个窗口就类似一个桶,数据到来了放到对应的桶中,到达窗口关闭时刻,关闭对应的桶收集即可。

2. 窗口分类
1. 按照驱动类型分
1. 计数窗口(Count Window)
计数窗口就是多少个数据为一个窗口,比如10个数据为一个窗口,那么这个窗口就会等凑到10个数据后再关闭,和时间无关。实际很少用。
2. 时间窗口(Time Window)
时间窗口是根据时间划分窗口的,Flink中基本都是使用时间窗口,因为我们在统计数据的时候一般都是以时间维度来进行统计的,如上面所属,每分钟、每小时、每天等。
1. 按照分配数据规则分

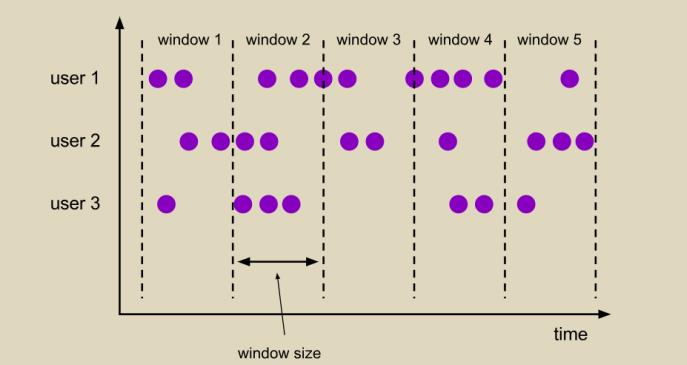
1. 滚动窗口**(Tumbling Windows)**
滚动窗口是按照固定的窗口大小设置的,对数据均匀切片,窗口之间不会重叠,也不会有间隔,每个窗口之间都是无缝衔接。比如:每分钟浏览量
如何使用:
stream.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(...)
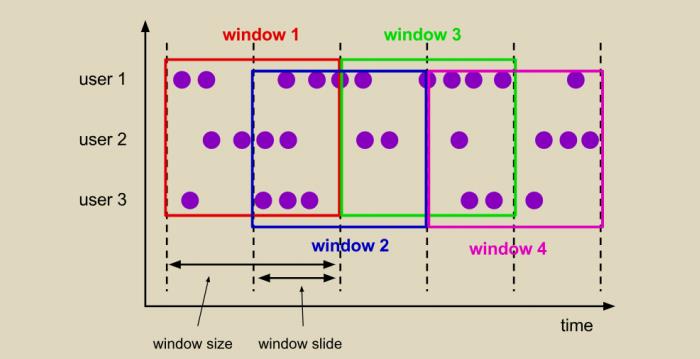
2. 滑动窗口(Sliding Windows)
滑动窗口是在每个窗口之间有个滑动步长,滚动窗口就是滑动窗口的一种特例,当窗口大小等于滑动步长的时候就是滚动窗口,适合统计输出频率比较高的指标。比如:每10秒钟计算前1分钟的页面浏览量
如何使用:
stream.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(...)
3. 会话窗口(Session Windows)
会话窗口是基于会话间隔进行切分的,会话窗口中窗口大小和窗口数量多少是不固定的,切分是根据会话间隔时间来的

如何使用:
stream.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(...)
4. 全局窗口(Global Windows)
数据没有窗口切分,全局只有一个窗口,如果需要计算数据,需要使用触发器实现。

如何使用:
stream.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(...)
四、窗口API使用
主要是对窗口API的使用说明
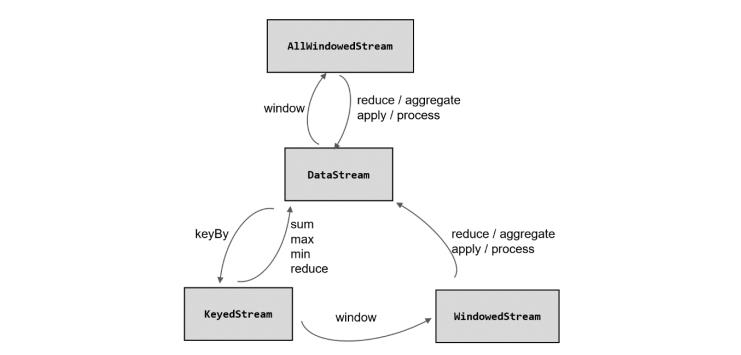
1. 按键分区(Keyed Windows)
按键分区是指对数据流进行keyby操作,数据流会按照key分为多个流,生成keyedStream,此时如果使用窗口函数,那么将会多所有key上进行**,相同的key发送到同一个并行子任务,窗口基于每一个key进行单独处理**,使用上需要使用keyby函数将数据流转换为keyedStream。
stream
.keyBy(<key selector>)
.window(<window assigner>)
.reduce|aggregate|process(<window function>);
2.非按键分区
如果实际场景中不需要使用按键分区,则可以不适用按键分区,此时我们可以调用非按键分区的API,缺点是此时的窗口不是并行处理的。窗口逻辑只能在一个任务( task)上执行,就相当于并行度变成了 1。 不推荐使用。
stream
.windowAll(<window assigner>)
.reduce|aggregate|process(<window function>);

3.窗口适配器( Window Assigners)
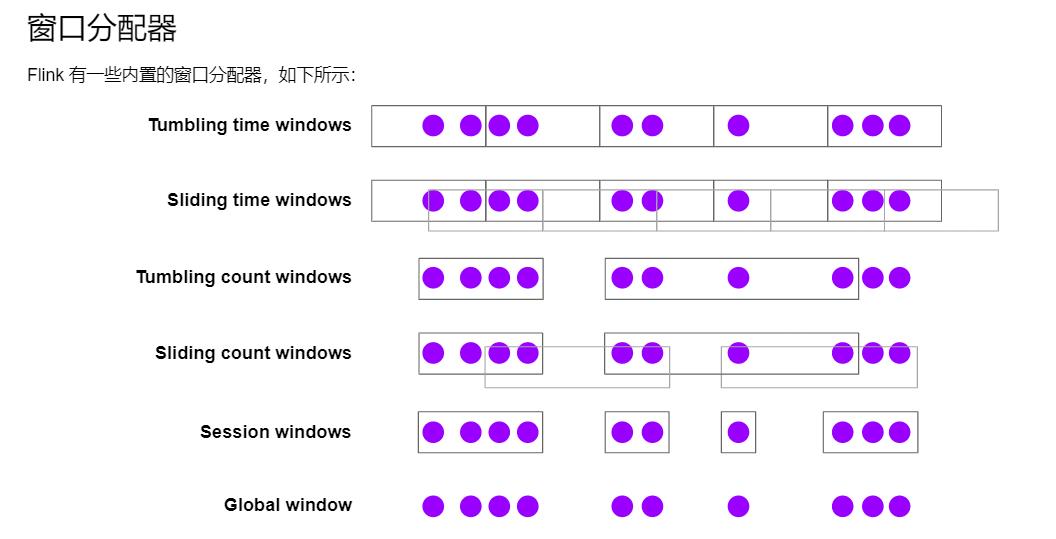
1. 窗口适配器的区分和使用:
- 滚动时间窗口
- 每分钟页面浏览量
// 滚动处理时间窗口
stream.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(...)
// 滚动事件时间窗口
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.aggregate(...)
- 滑动时间窗口
- 每10秒钟计算前1分钟的页面浏览量
// 滑动处理时间窗口
stream.keyBy(...)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
// 滑动事件时间窗口
stream.keyBy(...)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
- 会话窗口
- 每个会话的网页浏览量,其中会话之间的间隔至少为30分钟
// 会话处理时间窗口
stream.keyBy(...)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
// 会话事件时间窗口
stream.keyBy(...)
.window(EventTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
以上都是一些可以使用的间隔时间 Time.milliseconds(n), Time.seconds(n), Time.minutes(n), Time.hours(n), 和 Time.days(n)。
基于时间的窗口分配器(包括会话时间)既可以处理 事件时间,也可以处理 处理时间。这两种基于时间的处理没有哪一个更好,需要根据实际情况选择。
使用处理时间,优点是延迟较低,缺点是:
- 无法正确处理历史数据,
- 无法正确处理超过最大无序边界的数据,
- 结果将是不确定的,
使用基于计数的窗口时,只有窗口内的事件数量到达窗口要求的数值时,这些窗口才会触发计算。尽管可以使用自定义触发器自己实现该行为,但无法应对超时和处理部分窗口。
我们可能在有些场景下,想使用全局 window assigner 将每个事件(相同的 key)都分配给某一个指定的全局窗口。 很多情况下,一个比较好的建议是使用 ProcessFunction。
3.窗口函数(ProcessWindowFunction)
1. 数据流转换图
2. 增量聚合函数(incremental aggregation functions)
增量聚合函数就是我们在处理源源不断的数据的时候,并不是等窗口结束的时候一次性计算窗口内的数据,而是每个数据到来的时候我们就计算一次,只是不输出结果,等窗口结束的时候我们再进行结果的输出。
比如我们常见的规约函数(reduceFunction)和聚合函数(AggregateFunction )
聚合函数函数示例
public class WaterMarkAndWindows
public static void main(String[] args)
// 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取数据源
DataStreamSource<String> sourceStream = env.fromCollection(Arrays.asList("aa", "bb", "cc", "aa", "cc", "aa"));
// 使用keyby
KeyedStream<String, String> keyedStream = sourceStream.keyBy(data -> data);
// 基于keyedStream使用滚动窗口,窗口大小为1分钟
WindowedStream<String, String, TimeWindow> windowedStream = keyedStream.window(TumblingEventTimeWindows.of(Time.minutes(1)));
// 基于窗口函数进行聚合计算
SingleOutputStreamOperator<Long> aggregate = windowedStream.aggregate(new AggregateFunction<String, Long, Long>()
// 创建一个新的累加器,开始一个新的聚合。累加器是正在运行的聚合的状态。
@Override
public Long createAccumulator()
return 0l;
// 将给定的输入添加到给定的累加器,并返回新的累加器值。
@Override
public Long add(String str, Long aLong)
return ++aLong;
// 从累加器获取聚合结果。
@Override
public Long getResult(Long aLong)
return aLong;
// 合并两个累加器,返回合并后的累加器的状态。
@Override
public Long merge(Long aLong, Long acc1)
return aLong+acc1;
);
这里对四个方法进行总结下:
- **createAccumulator():**创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
- ** add():**将输入的元素添加到累加器中。这就是基于聚合状态,对新来的数据进行进一步聚合的过程。方法传入两个参数:当前新到的数据 value,和当前的累加器accumulator;返回一个新的累加器值,也就是对聚合状态进行更新。每条数据到来之后都会调用这个方法。
- **getResult():**从累加器中提取聚合的输出结果。也就是说,我们可以定义多个状态,然后再基于这些聚合的状态计算出一个结果进行输出。比如之前我们提到的计算平均值,就可以把 sum 和 count 作为状态放入累加器,而在调用这个方法时相除得到最终结果。这个方法只在窗口要输出结果时调用。
- **merge():**合并两个累加器,并将合并后的状态作为一个累加器返回。这个方法只在需要合并窗口的场景下才会被调用;最常见的合并窗口(Merging Window)的场景就是会话窗口(Session Windows)。
3. 全窗口函数(full window functions)
与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。 思路就是攒批处理
在 Flink 中,全窗口函数也有两种: WindowFunction 和 ProcessWindowFunction。
1. 窗口函数(WindowFunction)
我们可以基于 WindowedStream 调用.apply()方法,传入一个 WindowFunction 的实现类。 这个类中可以获取到包含窗口所有数据的可迭代集合( Iterable),还可以拿到窗口(Window)本身的信息。 当窗口到达结束时间需要触发计算时,就会调用这里的 apply 方法。我们可以从 input 集合中取出窗口收集的数据,结合 key 和 window 信息,通过收集器(Collector)输出结果。这里 Collector 的用法,与 FlatMapFunction 中相同。已被ProcessWindowFunction替代
stream
.keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction());
2. 处理窗口函数(ProcessWindowFunction)
除了可以拿到窗口中的所有数据之外, ProcessWindowFunction 还可以获取到一个“上下文对象”(Context)。这个上下文对象不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线( eventtime watermark)。这就使得 ProcessWindowFunction 更加灵活、功能更加丰富。事实上,ProcessWindowFunction 是 Flink 底层 API处理函数( process function)中的一员。ProcessWindowFunction 同样需要将所有数据缓存下来、等到窗口触发计算时才使用。它其实就是一个增强版的 WindowFunction。
4.窗口生命周期
1. 窗口的创建
窗口的类型是根据上面的窗口适配器确定的,但是窗口的实际创建是根据数据来确定的,也就是说服务器时间到了9:00:00 但是没有9:00:00的数据到来,那么9点整的窗口是不会创建的,只有9:00:00的这个窗口的数据到来了之后才会进行创建。
2. 窗口计算的触发
每个窗口都有自己的窗口函数(window process)和触发器(trigger)。**窗口函数定义了窗口的聚合逻辑。触发器定义了调用窗口函数的条件。 **
对于不同的窗口类型,触发计算条件也不同:
- 滚动事件时间窗口,应该在水位线到达窗口结束时间的时候触发计算。(**如果设置了延时时间,但还没有到达设定的最大延迟时间,这期间内到达的迟到数据也会触发窗口计算 ** )
- 计数窗口,会在窗口中元素数量达到定义大小时触发计算 。
3. 窗口的销毁
一般情况下,当时间到达了结束点就会触发计算,然后输出计算结果并销毁窗口。但是Flink中只针对时间窗口有销毁机制,计数窗口是基于全局窗口实现的,全局窗口不会清除状态,因此不会被销毁。
5.迟到数据的处理(重点)
在Flink中我们即使定义了水位线的延迟策略,那么也不能保证数据全部都能及时被统计,Flink为了保证数据的最终一致性,采用了侧输出流的机制将迟到的数据收集到侧输出流中:
OutputTag<Event> lateTag = new OutputTag<Event>("late");
SingleOutputStreamOperator<Event> result = stream
.keyBy(...)
.window(...)
.sideOutputLateData(lateTag)
.process(...);
DataStream<Event> lateStream = result.getSideOutput(lateTag);
我们还可以指定 允许的延迟(allowed lateness) 的间隔,在这个间隔时间内,延迟的事件将会继续分配给窗口(同时状态会被保留),默认状态下,每个延迟事件都会导致窗口函数被再次调用(有时也称之为 late firing )。
默认情况下,允许的延迟为 0。换句话说,watermark 之后的元素将被丢弃(或发送到侧输出流)。
举例说明:
stream.keyBy(...)
.window(...)
.allowedLateness(Time.seconds(10))
.process(...);
当允许的延迟大于零时,只有那些超过最大无序边界以至于会被丢弃的事件才会被发送到侧输出流(如果已配置)。
结束~
一文带你彻底搞懂Java和JavaScript的区别与相似之处(纯干货建议收藏)
Java 与 JavaScript 主要区别和相似之处

随着时间的推移,软件编程世界发展迅速,并提供了许多编程语言。您可能听说过 Java 和 JavaScript 的编程语言,名称听起来相似,并且可能对它们是同一种语言的不同名称还是不同感到困惑。在这个保姆级别且充满干货的文章之后,我相信你所有的困惑都会烟消云散。
什么是Java?
Java是一种OOP(面向对象的编程语言)、基于类的、具有VM(虚拟机)平台的多平台编程语言。OOP 是一种基于包含代码和数据的对象概念的编程范式。虚拟机可帮助您创建可在任何平台、任何地方灵活运行的编译程序。Java 将此概念称为一次编写,随处运行。
如何开始用 Java 编写代码
您需要遵循两个简单的设置步骤:
1.下载并设置 Java SE 开发工具包
2.选择您喜欢的任何编辑器
作为一个初学者我建议你选择记事本,因为它是最基本的。其他的编辑器或 IDE 也可以工作,只是尽量不要太花哨,因为您现在想专注于基本要素。
用Java编写一个简单的代码
让我们看看如何用 Java 简单地打印一个 hello world 程序。
// 一个用于打印简单字符串(字符输入类型,例如 HelloWorld)的 Java 程序,
class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
代码说明
- 您看到的第一行以描述我们程序的功能的通用注释语句开头。您可以看到它以
//XXX开头,它是单行注释(仅限于单行的注释)的符号表示。 - 在我们进入下一行之前,让我们探索大括号。大括号
{是指相应类或函数的开头,而大括号}是指它结束的地方。 class指的是一个对象构造函数,或者简单地说,是我们从中创建对象的蓝图。每个类都有一个名称,在我们这种情况下,我们的类名称是HelloWorld。- 现在进入我们程序的主要方法,即
public static void main(String[] args)
现在让我们把它分解成几块:
1.public 指任何人都可以从任何地方访问此方法,这意味着它在全局范围内可用。
2.static 是一个关键字,它简单地定义此方法是静态的且无法更改。
3.void 也是一个关键字,指的是不返回任何内容的方法。
4.main 指的是 Java main 方法的名称。
5.String args[]指的是传递给 main 方法的参数。args指的是字符串的名称。您可以args使用任何其他字符串名称命名,这只是用于它的标准命名。
6.System.out.println("Hello, World!");这是我们Hello, World!打印的实际输出行。单个语句和变量声明以分号结尾。
对于只在屏幕上打印单个字符串的程序来说,这听起来很复杂吗?确实如此,这也是为什么学习 JavaScript 是初学者开发者更好的选择的原因之一。
什么是 JavaScript?
JavaScript 是一种轻量级的高级脚本编程语言,通常用于使网页具有动态性和交互性。它可以将动态文本添加到 HTML 中,并以浏览器语言而闻名。我们将在与 Java 的比较中讨论它的详细特性。
如何开始使用 JavaScript 编写代码
您只需要具备以下 2 件事即可开始使用 JavaScript:
1.浏览器(谷歌浏览器、Safari、Firefox、Internet Explorer等等)
2.编辑器(记事本、VS Code、Atom等)
如何编写你的第一个JavaScript 程序
让我们看看如何用 JavaScript 编写第一个 hello world 程序。
// 一个用于打印简单字符串(字符输入类型,例如 HelloWorld)的 JavaScript 程序,
console.log('Hello World');
代码说明
- 第一行也是同一个单行注释,就像我们前面在 Java 程序中看到的那样。
- 在 JavaScript 中,我们简单地使用语句
console.log
在控制台上打印任何内容(一个提供对浏览器调试控制台的访问的对象)。简而言之,您可以在以下情况下查看它:
1.你右击鼠标
2.点击检查
3.选择控制台选项卡
4.在控制台查看记录的语句
现在告诉我,和Java相比,它要容易多少?
你是对的,它们甚至一点都不相似。
Java 和 JavaScript 之间的主要区别
我们可以注意到两种语言之间存在以下主要差异:
- 编程范式: Java 严格遵循面向对象编程范式,而 JavaScript 遵循多范式,包括面向对象编程、过程化和脚本编程语言。
- 代码执行: Java 应用程序具有在 JVM(Java 的虚拟运行时环境)上运行的灵活性,而 JavaScript仅在特定于浏览器的特定于应用程序的环境中运行。
- 对象: Java 对象纯粹是基于类的,而 JavaScript 对象是基于原型的。
- 类型检查: Java 确保在编译前对其变量和函数进行强类型检查,这使得运行或编译时运行的概率非常低。然而,JavaScript是弱类型的,变量的类型在编译之前是未知的,因此,运行或编译时错误的机会增加。
- 文件扩展名: Java 具有.java文件扩展名,而 JavaScript 具有.js文件扩展名。(顺带提一下,我们常说的Js等同于JavaScript ,只不过一个是全称,一个是缩写)
- 多线程: Java 支持多线程(同时执行两个或多个线程以最大限度地利用 CPU),而 JavaScript 不支持。
- 内存使用:由于 Java 有很多内容,所以它占用更多的空间,而 JavaScript 占用的空间更少。
- 语言依赖:两种语言都可以独立工作,也可以与其他语言配对。
- 并发方法: Java 利用其多线程能力并具有基于线程的方法,而 JavaScript 则遵循事件驱动的方法。
- 性能:由于其参与的性质,脚本语言总是比纯编程语言更有效,因此,与 JavaScript 相比,Java 效率较低且速度较慢。
Java 和 JavaScript 之间的相似之处
刚才探讨了有什么不同对吧?现在让我们也探讨一下这两者有什么共同点。
- 浏览器兼容性:两种语言都可以在浏览器上运行。
- 支持:两种语言都有很多在线支持社区。
- 语法和编程概念:
虽然两者都是两种不同的语言,但都共享相同的核心编程概念和一些语法概念,例如:
1.使用编程循环,例如 for 循环、while 循环。
2.使用条件语句,例如 if 和 else if。
3.使用 Math.pow 等数学库。
4.常见的共享语法符号,例如代码块定界符{},以分号结尾的代码语句。
- 相似名称:这个很奇怪,Java 和JavaScript 都有“Java”的共同点,尽管这两种语言完全不同。
结论
综上所述,Java和JavaScript是两种不同的不同语言。它们之间的一些相似之处主要来自核心编程原则,但除此之外,它们都是两个不同的世界,它们具有相似的名称,但主要区别在于彼此。
关注作者公众号【海拥】回复【进群】,免费下载CSDN资源和百度文库资源

最后,不要忘了❤或📑支持一下哦
以上是关于Flink总结之一文彻底搞懂时间和窗口的主要内容,如果未能解决你的问题,请参考以下文章