《重学Java高并发》disruptor在数据同步场景下的应用实战(技术方案设计实战)
Posted 中间件兴趣圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《重学Java高并发》disruptor在数据同步场景下的应用实战(技术方案设计实战)相关的知识,希望对你有一定的参考价值。
专栏特色:结合10余年的工作经验,在实践中提炼总结高并发经验,将理论落到实处,不仅助力面试,更是真正提高技能。
专栏目录:
笔者最近在负责全司数据同步产品化的设计与开发,其设计宗旨:实现任意数据源到任意目标端的数据准实时同步,其中一个非常常见的场景:mysql数据同步到ES,本文的着力点就在如何提高Binlog的拉取与解析效率设计。
1、场景描述
了解过mysql主从同步机制的童鞋们都知道是基于binlog实现,mysql增量同步的核心设计理念:将同步线程“伪装”为需要同步的mysql节点的从节点(slave),主动向mysql主节点发送dump请求即可获得主节点的binlog推送。
业界一个比较知名的 mysql bing log 解析类库为Canal,结合笔者公司实际情况,决定只使用底层的binlog解析工具,其他数据同步功能自研,本文将重点关注binlog拉取与解析。
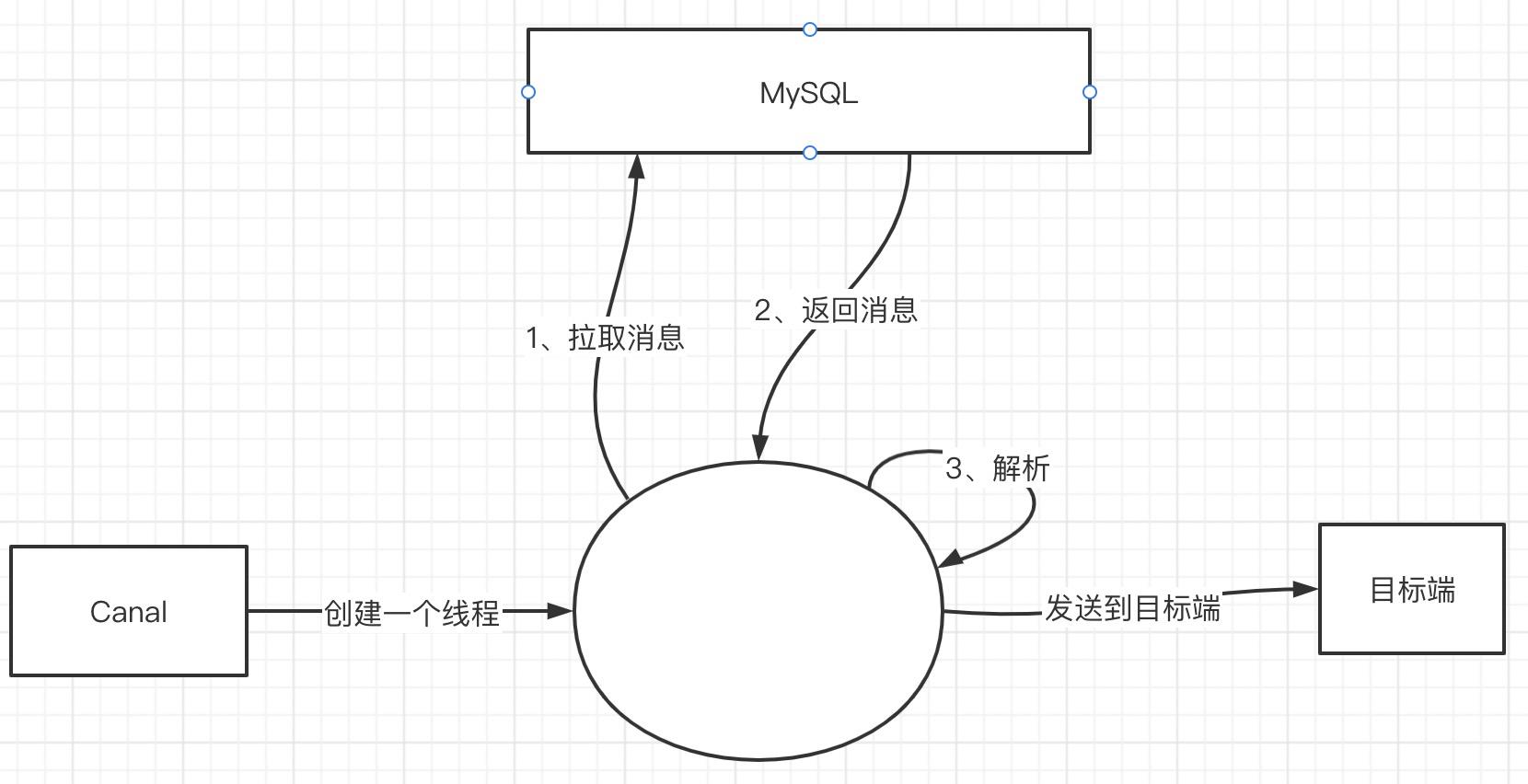
接下来将尝试优化上面的性能,逐步引出disruptor。
2、技术方案与优化
一个线程负责拉取binglog消息,然后对拉取的消息进行解析,解析出数据库相关字段后写入目标端,拉取、解析这两个操作本身就是一个比较重(慢)的操作,如果将其进行分解,一旦拉取线程拉取到数据后,解析线程在解析的过程中,拉取动作可以继续拉取,两者并发执行,可以提高执行效率,其设计理念如下:
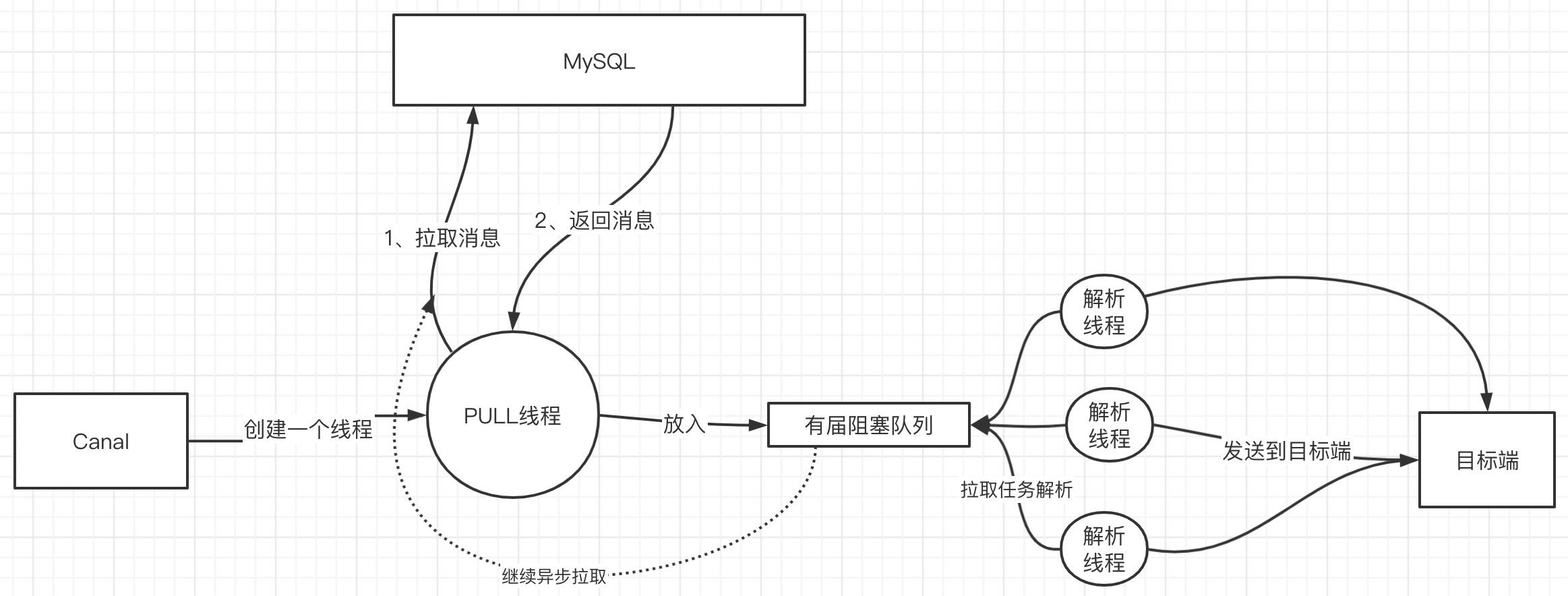
能想到的第一个优化方案肯定是引入多线程,一个进程通常只会开启一个线程与MySQL服务端拉取binlog,该线程拉取到数据后,放入到一个有界队列中,然后启动一个多线程去将拉取到的信息进行并发解析,解析完后再发送给目标端。
思路是对的,但这里有一个非常关键点:基于binlog解析进行的数据同步,必须考虑事件的顺序性。
例如在源端,对一条数据id=5的记录,出现一个INSERT、UPDATE、DELETE,如果在发给目标端先将INSERT事件发给目标端,然后再将DELETE、UPDATE事件依次发送到目标端,造成的结果就是数据的不一致。
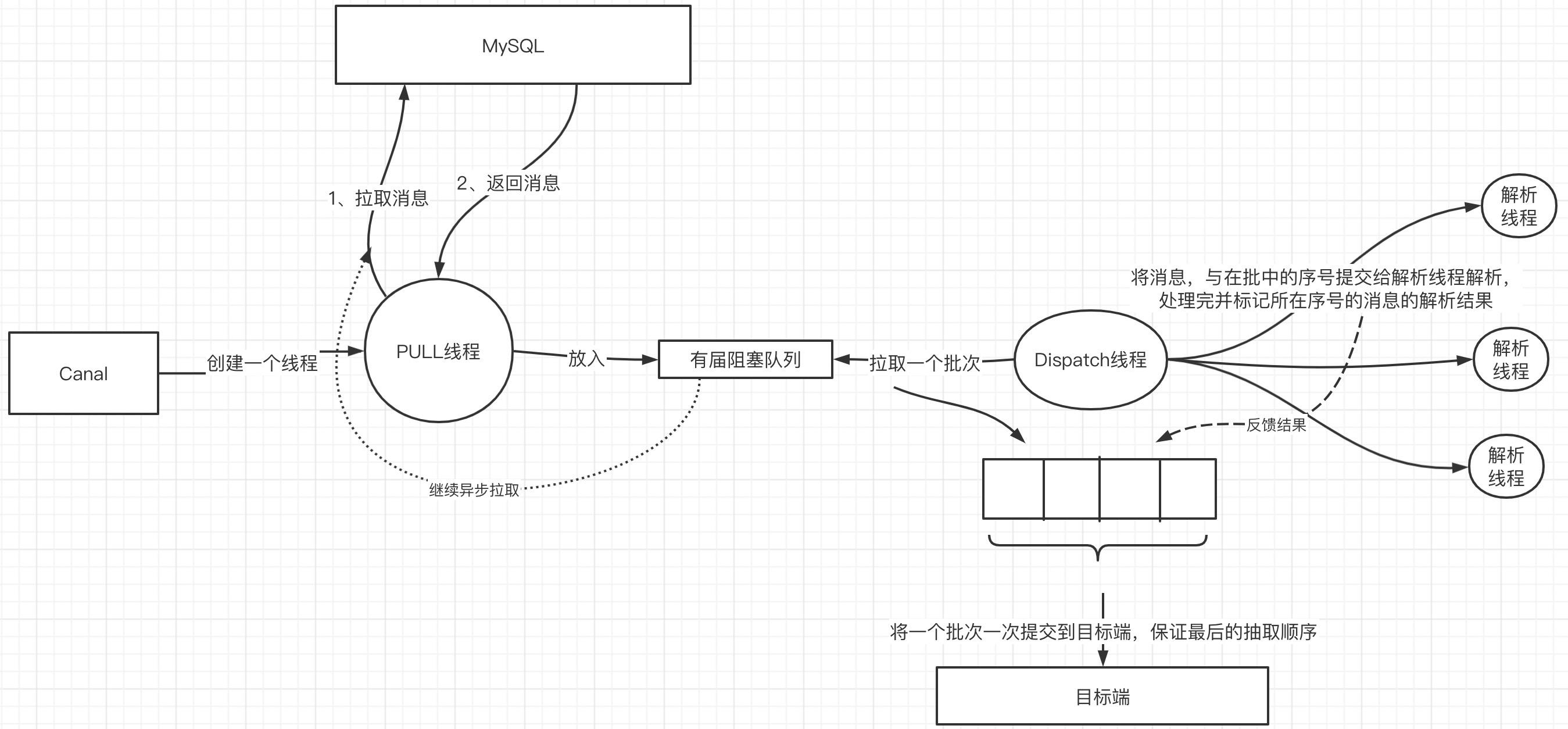
为了保证发送到目标端端顺序性,在原来的基础上引入了一个转发线程,再结合批处理的思路来实现日志解析的并发性,但不打破顺序性语义,实现关键点如下:
- 引入一个线程,一次从阻塞队列中获取多条数据,该数量可以配置,然后将该批消息转发到解析线程,但转发的时候,会将这条消息所在的批的序号告知解析线程。
- 解析线程在处理完一条任务的解析工作后,反馈给转发线程,得这个批次中所有的消息都解析完成后,然后将该批次的所有消息,按照顺序传送到目标端
此过程,该批次的解析任务是并行的,但每一批次的消息是串行,性能得到优化的前提下,兼顾来顺序语义,是不是很完美?
至少当时的我是觉得这个优化方案还是不错的,邀请团队成员进行方案评审(设计方案是架构师出没错,但不要刚愎自用,多发挥团队的智慧),当我讲完方案设计后,其中一个小伙伴说,我非常赞同这个方案,并且业界已经有了成熟的方案,那就是disruptor,内部已经提供了封装,并且内部没有使用锁,在会上我当即表示,既然已有开源类库,那我们优先采用类库,会后麻烦你提供一下示例代码。
组员也非常给力,会后“三下五除二”就提供了示例代码,截图如下:

核心关键点:
- 创建RingBuffer,环形缓存区,并且注意使用的是createSingleProducer方法,创建一个单一生产者,表示这个环形队列只会有一个生产者往里丢数据,这种模式可以提供多个消费者无锁访问RingBuffer;与此对应还提供了createMultiProducer,支持多生产者单消费者的无锁化访问。
- 使用WorkPool,线程池并发解析,多个消费者访问同一个环形队列。
- 引入SequenceBarrier,将并发解析后的结果按序抽取到一个新的队列中,即目标端。
为了方便理解上disruptor的使用,我们将上述代码与技术方案进行一个对标:
-
阻塞队列
技术方案图中的阻塞队列换成了disruptor的环形队列RingBuffer,PULL线程将拉取到的消息丢入队列中 -
解析线程
解析线程对标WorkPool,WorkPool中会创建多个WorkProcessor,多个线程不加锁的访问环形队列,并发解析。 -
顺序性输出到目标端
在disruptor中引入了SequenceBarrier,保证顺序性保证。
从实战场景来看disruptor的经典使用场景:多线程基于队列协作进行,实现百万级的性能保证。其核心要点:无锁化。由于篇幅的原因,本文不打算正式研究disruptor的实现原理,将在后续文章中深入研究disruptor的实现原理,读者朋友们也可以提前思考一下,可以关注笔者公众号,共同探讨交流。
一键三连(关注、点赞、留言)是对我最大的鼓励。
各位技术朋友们,我是《RocketMQ技术内幕》一书作者,CSDN2020博客之星TOP2,热衷于中间件领域的技术分享,维护「中间件兴趣圈」公众号,旨在成体系剖析Java主流中间件,构建完备的分布式架构体系,欢迎大家大家关注我,第一时间获得最新干货文章。

⚠️点击下方卡片,关注弹出内容,可以领取「学习资料」以及加入「中间件技术交流社群」,共同刷题进步,各大大厂内推应有尽有,抱团发展!
以上是关于《重学Java高并发》disruptor在数据同步场景下的应用实战(技术方案设计实战)的主要内容,如果未能解决你的问题,请参考以下文章
《重学Java高并发》disruptor在数据同步场景下的应用实战(技术方案设计实战)