《重学Java高并发》Disruptor使用实战
Posted 中间件兴趣圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《重学Java高并发》Disruptor使用实战相关的知识,希望对你有一定的参考价值。
上文已经详细介绍了disruptor,也体会了并发编程的奥妙,接下来将理论结合实战,本文和大家分享一下disruptor的使用,加深对disruptor工具包对理解。
1、 disruptor常用类一览
disruptor的常用类体系如下图所示:
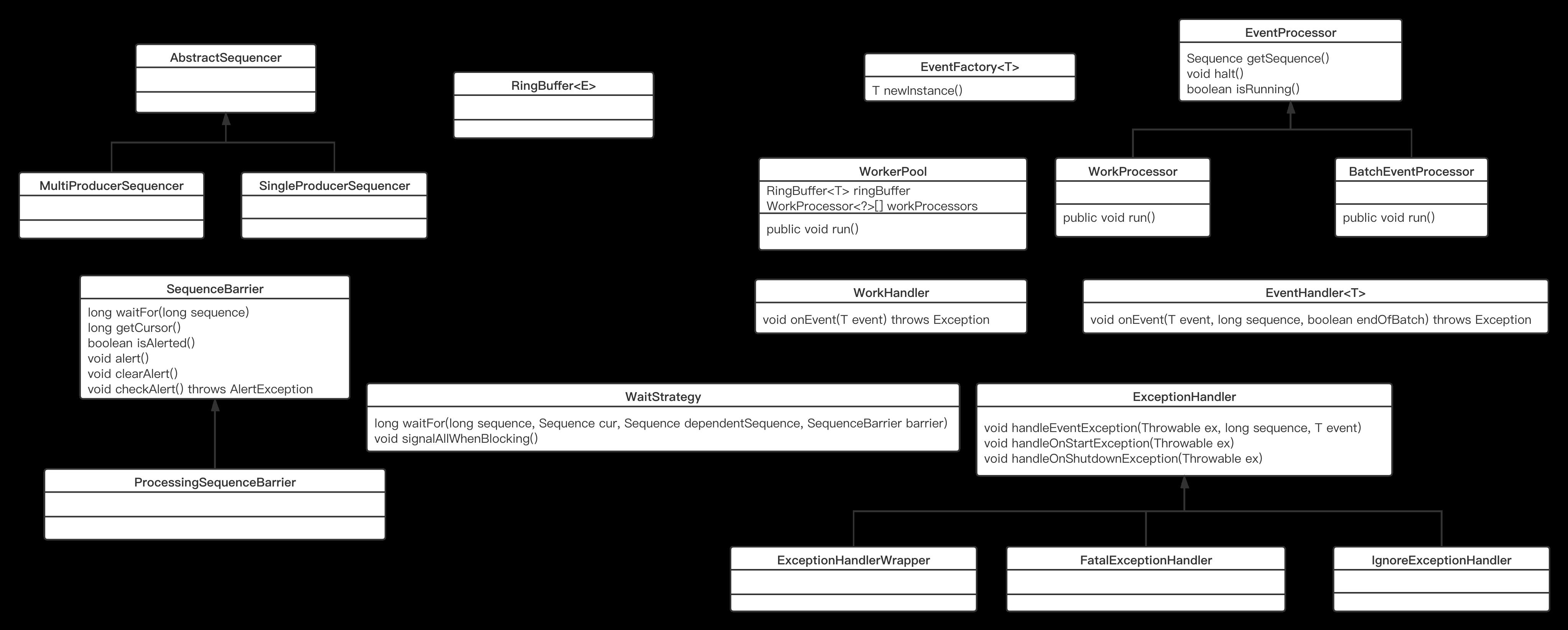
其职责说明如下:
-
RingBuffer
环形队列,disruptor中的核心存储类 -
Sequencer
序号实现器,维护发送者发送的序号生成逻辑、消费方获取可消费的序号,是无锁化访问的核心实现类,共有两个实现类,MultiProducerSequencer为多生产者实现类、SingleProducerSequencer单生产者实现类。 -
WaitStrategy
等待策略,消息发送者在容器已写满时、消费者在无消费数据时的等待策略,disruptor提供了N种实现类:- BlockingWaitStrategy
基于juc的阻塞等待。 - LiteTimeoutBlockingWaitStrategy
带超时时间的阻塞等待。 - YieldingWaitStrategy
先自旋100次,如果还不满足条件,则每次调用yield方法,让出CPU,重新参与调度。 - BusySpinWaitStrategy
自旋,直到满足条件,生产环境慎用。 - TimeoutBlockingWaitStrategy
带超时时间的阻塞等待,与LiteTimeoutBlockingWaitStrategy的区别是TimeoutBlockingWaitStrategy等待时间必须严格低于设定的值。 - SleepingWaitStrategy
前100次自旋每一次都调用yield,然后阻塞1ms ,继续重试。 - PhasedBackoffWaitStrategy
组合策略,可以指定上述策略,然后退化为 yield自旋。
WaitStrategy在创建RingBuffer时指定,默认为BlockingWaitStrategy。
- BlockingWaitStrategy
-
SequenceBarrier
序号栈栏。在流水线上有多个步骤,后一个步骤必须依赖前一个步骤的完成,栈栏的作用就在于此。 -
EventFactory
事件生成器工厂类,RingBuffer的设计为力避免频繁的垃圾回收,在RingBuffer中存储的值会预先创建,生产者获取一个Event对象,并填充具体的值,故通常事件对象通常创建的事一个包装类。
-
EventProcessor
事件处理器,disruptor中提供了两类事件处理器WorkProcessor、BatchEventProcessor(批处理),它的职责是从RingBuffer中获取可消费的事件,然后调用EventHandler的onEvent方法。 -
EventHandler
事件处理器在获取一个可处理的事件后调用EventHandler的onEvent方法,这也是用户自定处理程序的入口,即编写用户业务代码的扩展点。 -
ExceptionHandler
异常处理策略。
2、disruptor在canal中的运用
首先以笔者在工作中遇到一个经典使用场景来和大家观摩一下disruptor的基本使用。
在互联网行业中有一种经典的读写分离架构:数据异构,以物流下单为示例,通常关系型数据库只负责订单的创建业务,而关于订单查询、订单轨迹查询等查询类业务,通常会去查询es,依此来降低数据库压力,但接踵而来的问题是如何将数据库的数据准实时同步到Es呢?canal闪亮登场,其核心理念就是订阅并解析binlog,其基本的流程如下:

在示例中解析binlog的目的是提取数据的变化,即DML语句(插入、更新、删除),将这些数据变更在目标端进行重放,为了提高性能,采用disruptor框架提高性能,该如何实现呢?
- 将解析动作分解为两步,第一步判断事件是否是dml事件,即是否需要解析。
- 解析dml
为什么要这样拆分呢?一是将粒度降低,解耦,灵活提供不一样的并发度。
接下来我们看一下canal中是如何使用disruptor来解决该问题的。
2.1 创建EventFactory
首先需要创建一个EventFactory,用于填充RingBuffer中的对象,避免过多垃圾回收。

2.2 创建RingBuffer
根据bingo dump协议,mysql的解析线程创建一个,故该场景下的事件发送者只有一个,创建一个单生产者的RingBuffer,其代码如下:

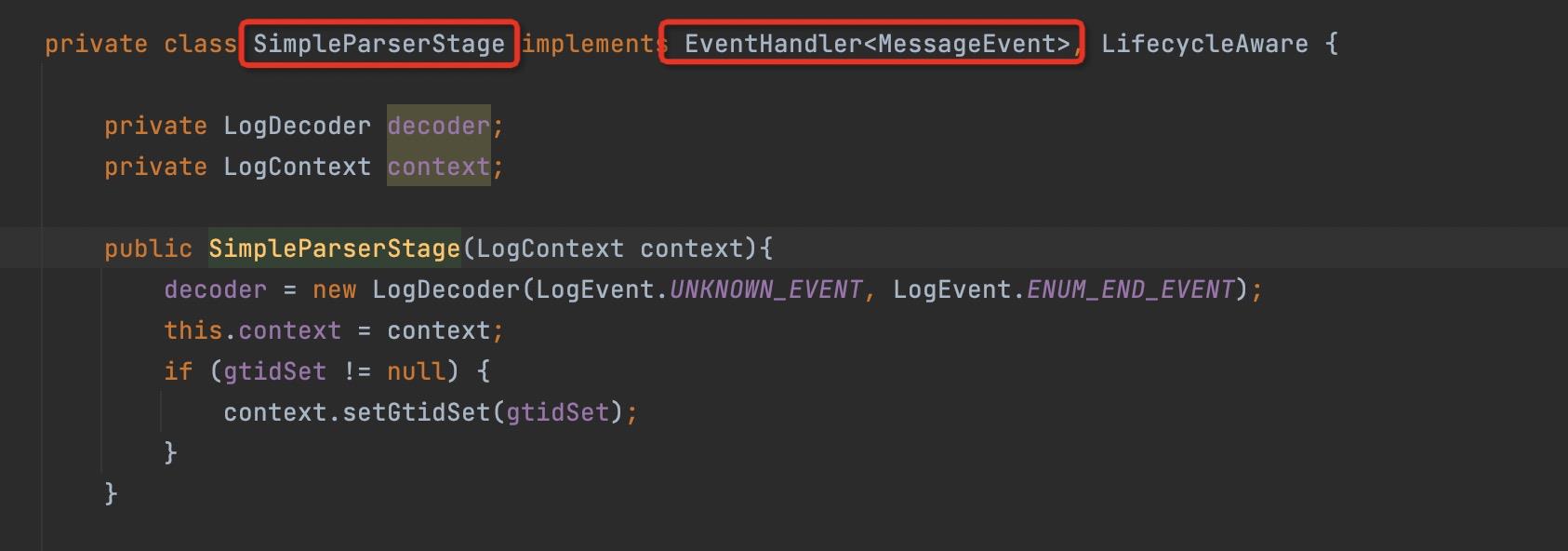
2.3 创建相关的业务Handler
在该场景中需要定义两个handler,由于是具体的业务逻辑,这里不做详细介绍,简单截图说明如下:
2.4 创建栅栏(顺序性保证)
由于binlog解析场景有一个特殊的场景:并发解析但不能破坏顺序性语义。

2.5创建事件处理器
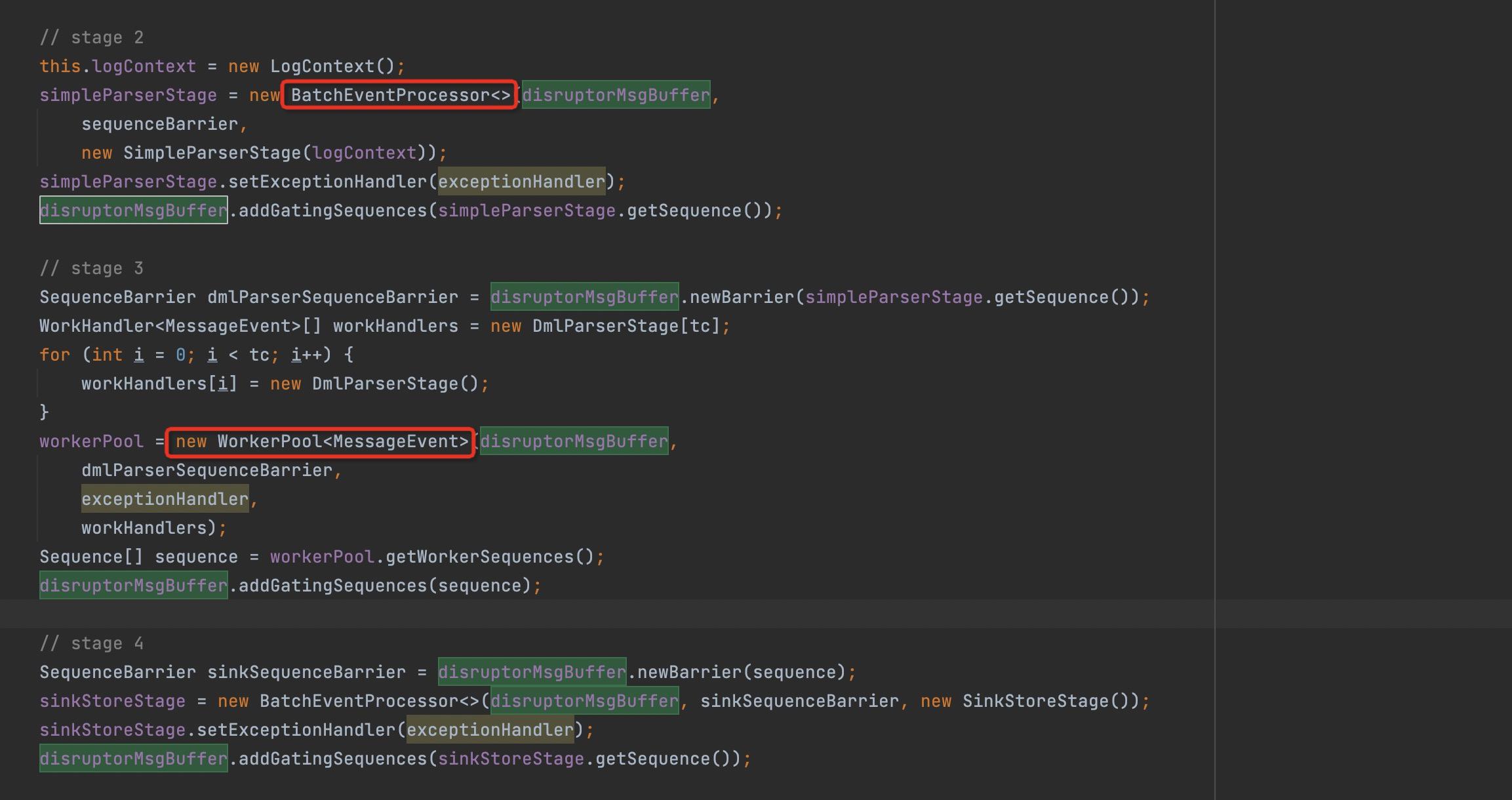
在解析事件类型、元数据时采用了BatchEventProcessor,但使用了批处理机制;而在解析dml具体数据时采用了WorkProcessor,支持多线程并发解析。
值得注意的是dml解析器必须依赖元数据解析器,故这里需要引入栈栏,具体是利用RingBuffer的addGatingSequences方法依次将自身处理器的sequences加入到RingBuffer中。
2.6 生产者端代码模板
生长者这边主要是将数据写入到RingBuffer中,从而让下游消费。
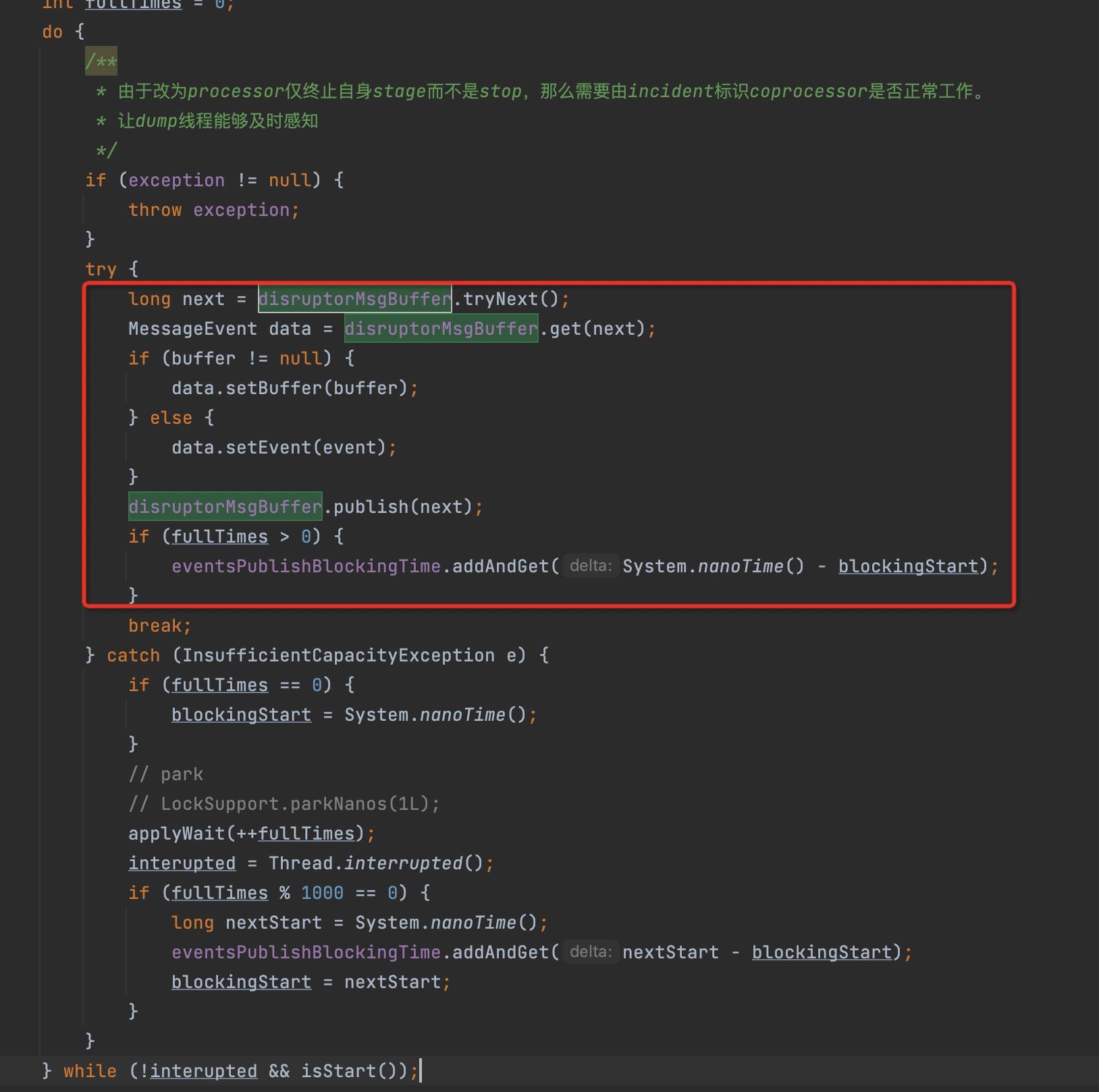
上述代码的特点:
- 使用 do while 循环,持续放入。
- 首先调用 RingBuffer的tryNext,尝试获取一个可写的序号,如果获取不到,则重试。
- 获取一个可写序号号,将值进行填充,然后调用publish方法进行发布,让消费端可感知。
如果序列器一次可以返回一批序号,则可以在一个批次处理,即降低了获取序号的次数。
本文就介绍到这里了,经过上述的讲述,大家对disruptor无锁化的实现原理应该有了一个比较全面而清晰的理解,也欢迎大家关注我的公众号,加我微信dingwpmz,共同探讨交流。
以上是关于《重学Java高并发》Disruptor使用实战的主要内容,如果未能解决你的问题,请参考以下文章