《重学Java高并发》disruptor是如何做到百万级吞吐?
Posted 中间件兴趣圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《重学Java高并发》disruptor是如何做到百万级吞吐?相关的知识,希望对你有一定的参考价值。
Disruptor是业界非常出名的单机版高性能队列,官方宣传能达到百万级吞吐,那disruptor是如何做到的呢?
其核心秘诀如下:
- 破除伪共享
- 对象池
- 无锁化设计
- 批处理
上面这些观点,网上已经提了N遍,没关系,本文将结合代码、图解的方式,与大家一起探究实现原理,希望能给读者朋友们不一样的感悟。
提到Disruptor,必然会提到RingBuffer,disruptor环形队列,是整个Disruptor是基座,本文将尝试以RingBuffer为突破口,揭晓disruptor的核心设计理念。
disruptor是如何做到百万级吞吐?
1、RingBuffer核心类图
RingBuffer是disruptor的核心,其类图如下图所示:

温馨提示:如果图看不清,可以加我微信dingwpmz,获取高清图片。
相关的类说明如下:
- Sequenced
环形缓存区与序号相关的操作,这个是环形缓存区的基本属性,不太好用语言来描述,我们通过它的核心方法来阐述:- int getBufferSize()
获取缓存区大小 - boolean hasAvailableCapacity(int requiredCapacity)
是否还有requiredCapacity个空间供写入线程写入数据 - long remainingCapacity()
当前剩余容量。 - long next()
获取下一个可写入的下标(序号) - long next(int n)
从环形队列中获取n个可用的下标,返回值为这批最大的可写入序号。 - long tryNext() throws InsufficientCapacityException
尝试从环形队列中获取一个可写入位置,如果没有空闲位置供写入则抛出异常。 - long tryNext(int n) throws InsufficientCapacityException
尝试从环形队列中获取n个可写入位置,如果没有空闲位置供写入则抛出异常。 - void publish(long sequence)
将处于下标sequence的位置“发布”,此时消费者可以从环形队列中消费。 - void publish(long lo, long hi)
将从 lo 到 hi 的下标之间的数据发布。
- int getBufferSize()
- DataProvider
数据提供者,只提供了根据下标位置获取数据。 - Cursored
游标,当前处理的下标。 - EventSink
数据 sink,主要是提供了丰富的publish方法。 - RingBufferPad、RingBufferFields
填充实现,主要解决“伪共享” - RingBuffer
环形缓存区实现类,也是本文的绝对主角。
2、RingBuffer存储结构
2.1 伪共享
在介绍RingBuffer的存储结构,就不得不先介绍CPU的缓存机制,在CPU中通常存在L1、L2、L3三级缓存,以前只有L1缓存是集成在CPU中,L2级缓存是集成在主板,随着制造工艺的提升,目前L1、L2、L3三级缓存都集成在CPU,如下图所示:

其中L1存储容量最小,但访问速度最快。CPU在执行指令时,优先从L1获取数据,如果缓存未命中,则依次访问L2、L3、最后访问主内存。
在计算机领域有一个非常著名的理论:局部性原理,在执行指令时访问到的数据,接下来80%的概率会访问到这条数据附近的数据。所以CPU在缓存数据时并不是一次只返回访问到的数据,而是会一次读取批数据(CPU一次缓存64字节数据),以读取数组为例进行阐述:

在到arrs[0]的时候,会将arrs[0]~arrs[7]这64个字节的数据,组成一个缓存行,这种机制极大的提高性能。
缓存行,但会造成“伪共享”的问题,当缓存行中一个数据发生变化,该缓存行将失效。
接下来结合环形队列为例来阐述一下伪共享。

关于队列,有两个重要的指针getIndex,writeIndex,基于cpu缓存机制,会将这些数据加载到一个缓存行,然后当一个线程更新getIndex值,另外一个线程更新writeIndex,这样任意一个线程对数据进行更新,其cpu中该缓存行就会失效,造成缓存未命中,缓存的优势也就随即消失,这就是所谓的伪共享。
解决伪共享的主要手段是填充,使用填充,我们来存在getIndex,writeIndex的梳理如下:
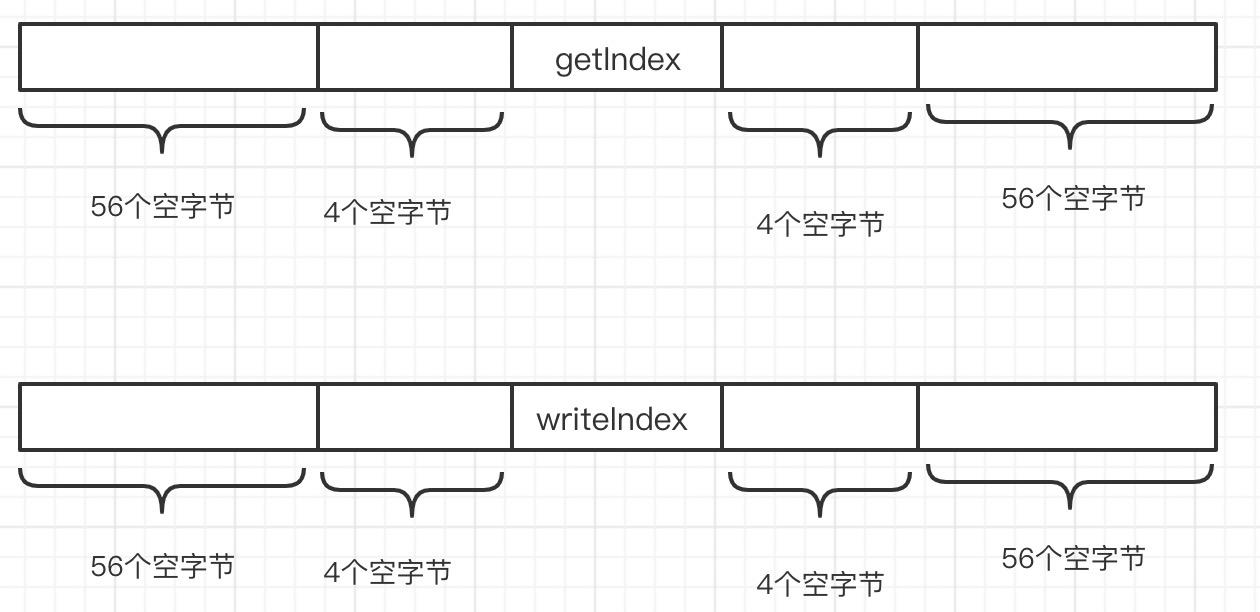
这样可以保证无论怎么将getIndex、writeIndex加载到CPU的缓存行时,可以保证一个缓存行只会包含getIndex或writeIndex,保证两个线程不会有更新竞争,确保缓存命中率,从而提升性能,这其实是典型的以空间换时间。
2.2 RingBuffer破解伪共享
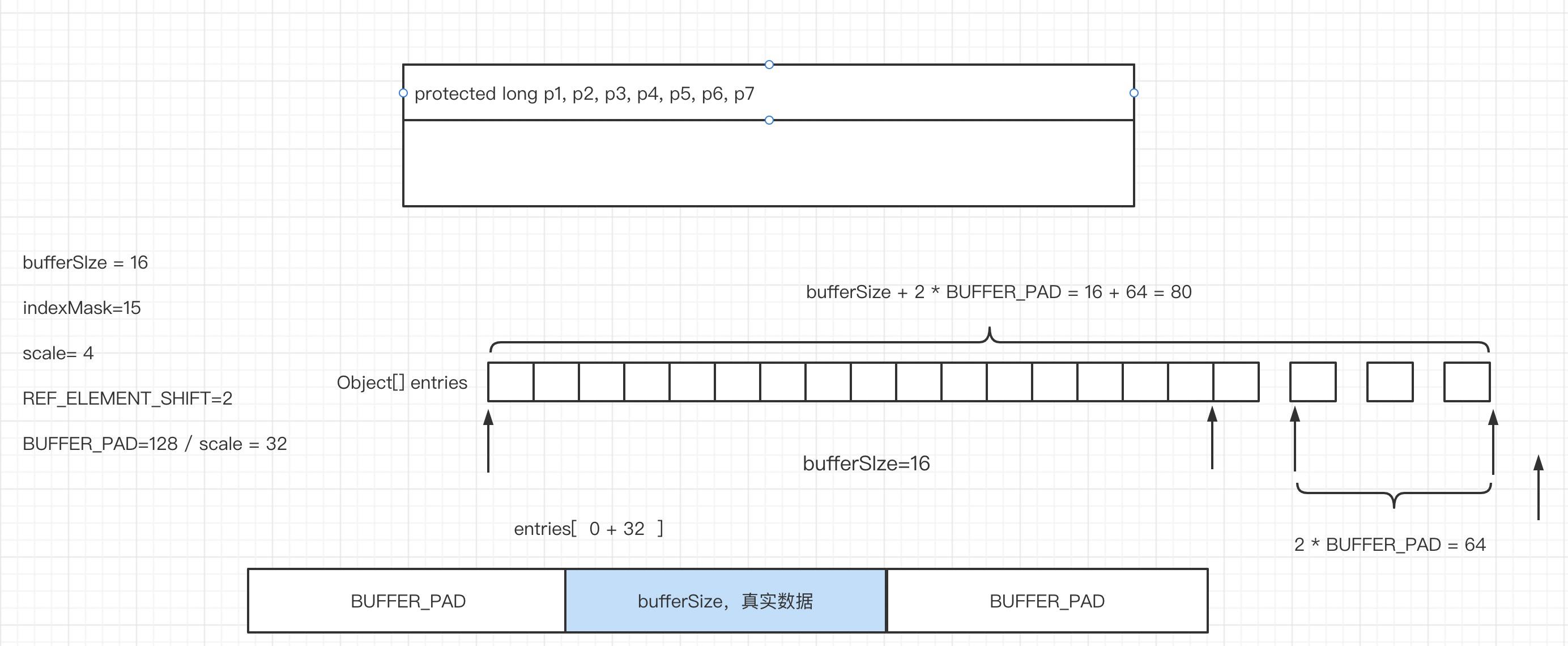
在RingBuffer中环形队列在底层需要维护一个存储数组,如何确保将这些下标不要和其他变量不要缓存在一个cpu缓存行,通常的方案是在前后数组填充128个字节(这里没有想明白,不是只需要64个字节就可以了吗?),其代码实现截图如下:

上面有几个知识点:
- UnSafe的arrayIndexScacle方法返回当前jvm中用来表示一个数组下标占用的字节数,64位操作系统开启了指针压缩将返回4,否则返回8,默认开启了指针压缩。
- UnSafe的arrayBaseOffset可以获取数组的起始位置。
- 为了避免伪共享,用户申请bufferSize长度的数组,在内部会扩大其容量,在前后都会填充,这里在前后分别填充了128字节。
RingBuffer的内存布局如下图所示:
3、无锁化实现原理
了解来数据存储结构后,接下来将分析RingBuffer的写入与读取,特别是探究多线程环境下如何实现无锁化。
3.1 多线程写入无锁化实现原理
在介绍写入数据之前我们先来看一段基于disruptor的写入模板代码:
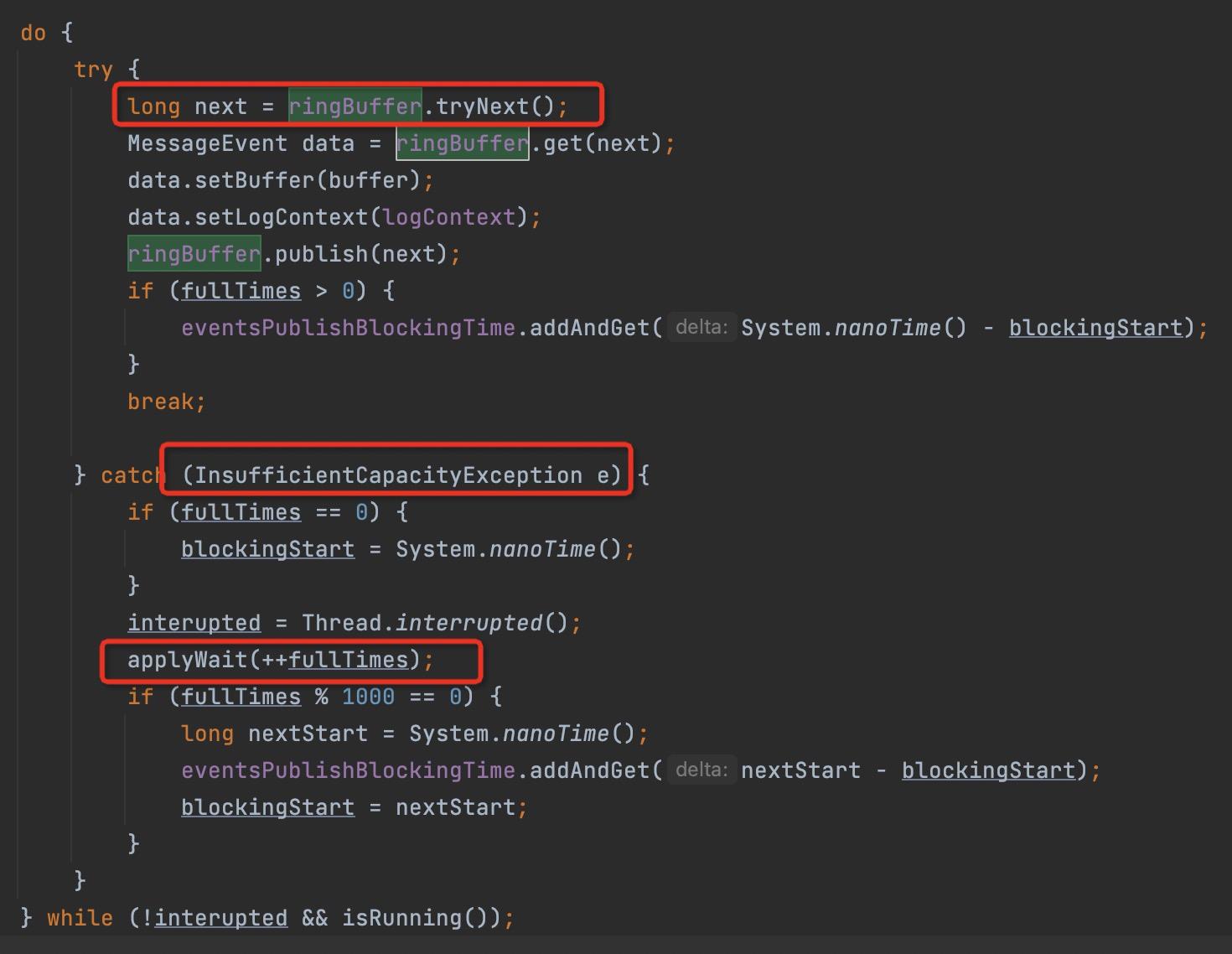
上述的关键点如下:
- 通过调用RingBuffer的tryNext方法一个写入位置,如果当前没有可用位置供写入,则抛出队列已满异常。
- 通过调用RingBuffer指定下标位置的元素,供数据填充,RingBuffer引用对象池技术,避免发生GC。
- 数据填充完毕后通过调用RingBuffer的publish方法,通知消费方可使用。
- 如果遇到队列已满异常,等待片刻,再次尝试写入。
显而易见,通过调用tryNext方法非常重要,是整个数据写入的核心,故接下来探究该方法,进入RIngBuffer无锁化设计的核心。
RingBuffer的tryNext方法的实现逻辑如下:

可见,RingBuffer直接委托给Sequencer,那Sequencer又是何许人也呢?
3.1.1 Sequencer详解
Sequencer的核心类图如下图所示:

基本的行为主要由Sequenced基类定义,也是理解该类体系职责的关键窗口,Sequenced主要定义如下行为:
-
int getBufferSize()
获取缓存区的容量 -
boolean hasAvailableCapacity(int requiredCapacity)
判断当前缓存区是否有充足的容量 -
long remainingCapacity()
当前剩余的容量 -
long next()
获取下一个可写的序号,该值会超过bufferSize,与其进行取模得出底层数组中的下标 -
long next(int n)
获取n个连续可写的位置,返回值为这批次最高的序号 -
long tryNext() throws InsufficientCapacityException
尝试获取下一个可写的序号,如果当前无可写序号,抛出空间不足异常
-
long tryNext(int n) throws InsufficientCapacityException
尝试连续获取n个可写序号,不足则抛出异常 -
void publish(long sequence)
将序号为sequence发布,消费端可消费。 -
void publish(long lo, long hi)
将序号 l0到 hi这批消息发布到消费端。
Sequencer继承Sequenced,主要增加了**栈栏(Barrier)**支持,在介绍具体实现时再重点关注。
MultiProducerSequencer、SingleProducerSequencer两个具体的实现,也是Disruptor实现无锁化的核心要点。
3.2 MultiProducerSequencer详解
从名称来看,是多生产者序号实现器。通俗的讲,就是实现多线程写入同一个队列,但无需引入锁。
关于写入序号的获取是MultiProducerSequencer的核心,具体由其next方法实现,为了更容易理解其实现原理,首先和大家介绍一下环形队列的基本特征。
环形队列的底层实现原理如下图所示:

所谓的环形队列,就是对数组进行重复利用,如上图所示,put指针移动道下标为3对时候,如果继续写,就会移动到数组下标为0到位置继续写入,故存在数据的覆盖,为了避免覆盖未处理的数据,需要满足一定的条件。
putIndex - getIndex < size ,其中getIdnex表示第一条待处理的数据。
理解来环形队列的基本特征,接下来我们来看一下MultiProducerSequencer next 方法的实现原理,其代码如下图所示:

通读这段代码,结合环形队列的实现原理,首先来解释一下几个变量的含义:
- cursor
环形队列已使用的最大序号,下一个可写序号从 cursor + 1 开始。 - gatingSequences
消费端已处理的最小序列号,即对标环形队列中的getIndex,不过这里的gatingSequences表示的是已处理的序号。
**那分支@1是什么意思呢?**判断缓存区不可写的条件,其变换过程如下图所示:

经过上述等式的变换,理解分支@1就不难了,也就是分支@1就是判断暂时不能写入序号,再次获取最新的消费序号,然后进行一次判断,如果还是不满足上述条件,则首先需要唤醒等待的消费者,因为此时有数据待消费,然后发送方进行自循。
分支@2:使用CAS命令尝试更新,如果更新成功,则返回next给发送者,允许发送方对next下标填充数据,但由于存在多个发送方,该next可能会被其他线程优先获取,故使用CAS命令,如果返回false,则自循。
编程技巧:CAS的使用技巧通常会结合while,其模板代码如下:

总结:主要是基于CAS实现无锁化,并且为了避免竞争,还提供了批处理机制,即发送方可以一次获取多个连续的序号,减少发送方端端竞争。
3.2 多线程数据消费无锁化实现原理
在disruptor中,并发消费的实现类有WorkerPool、BatchEventProcessor(批处理)。接下来将分别介绍。
3.2.1 WorkerPool多线程协作模式

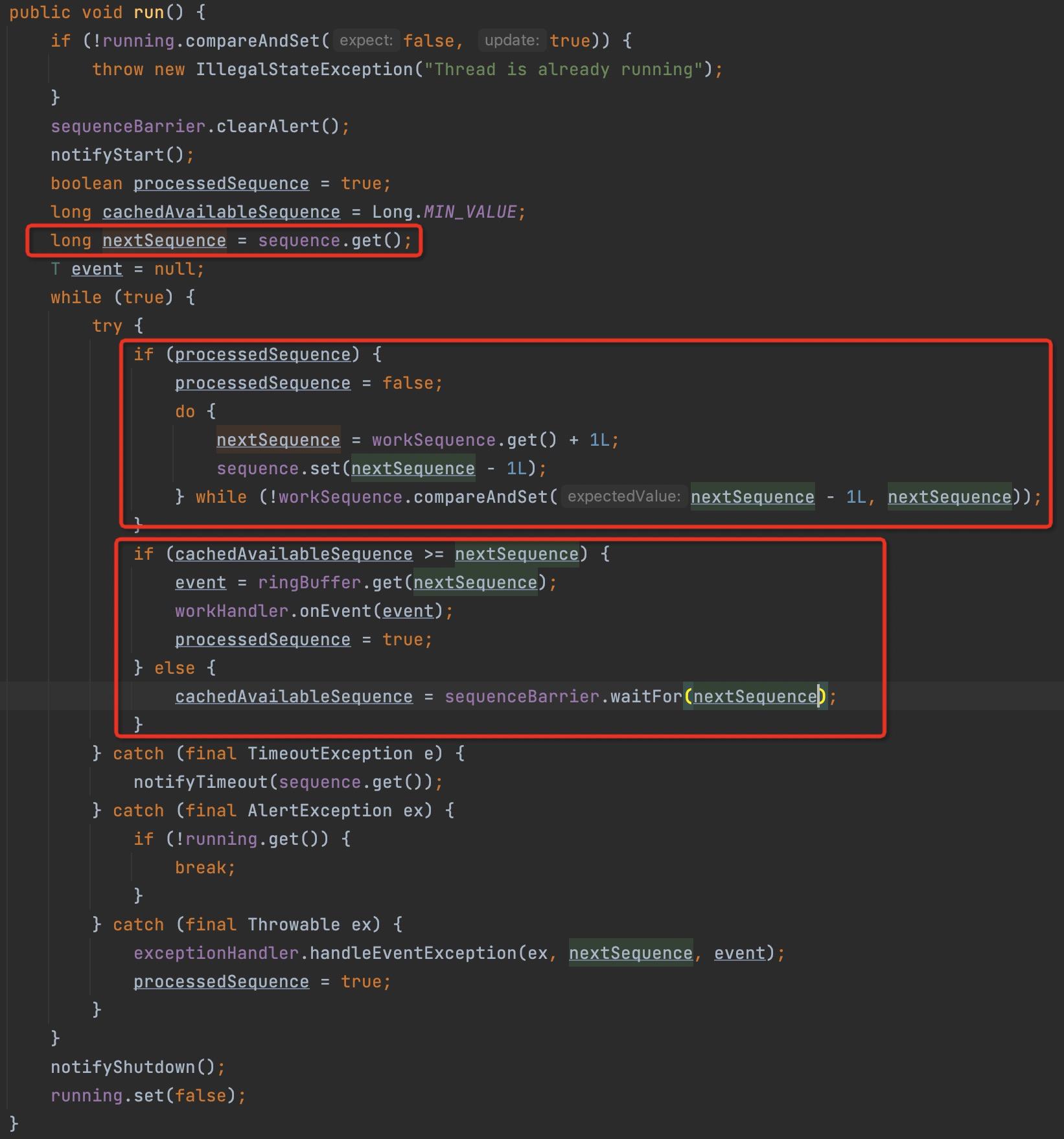
即多个WorkProcessors对同一个RingBuffer中的数据进行处理,即多消费者场景,接下来将探究WorkProcessor的run方法,其代码实现如下图所示:
介绍其实现原理之前,我们还是先对几个重要的局部变量加以说明:
- Sequence sequence
每一个WorkProcessor内部会维护一个当前已处理的序号。 - Sequence workSequence
每一个WorkerPool维护一个整体的处理进度序号,会被多个WorkProcessor共同竞争获取,故这里采用了CAS。
核心实现代码如下:
- 首先通过 while + CAS方式获取任务组(WorkPool)获取下一个待处理的下标,每成功一次,该序号将被WorkProcessor锁定,其他处理线程将尝试处理后面的序号。
- 如果当前可处理的序号大于等于nextSequence,即可处理该序号中的数据,否则通过barrier的waitFor等待待处理序号可用,即等待发送方发布该序号,其调用链如下所示:

WorkerPool的核心处理要点:每一个线程一次只处理一个序号。
3.2.2 BatchEventProcessor批处理协作模式
BatchEventProcessor的关键代码如下所示:
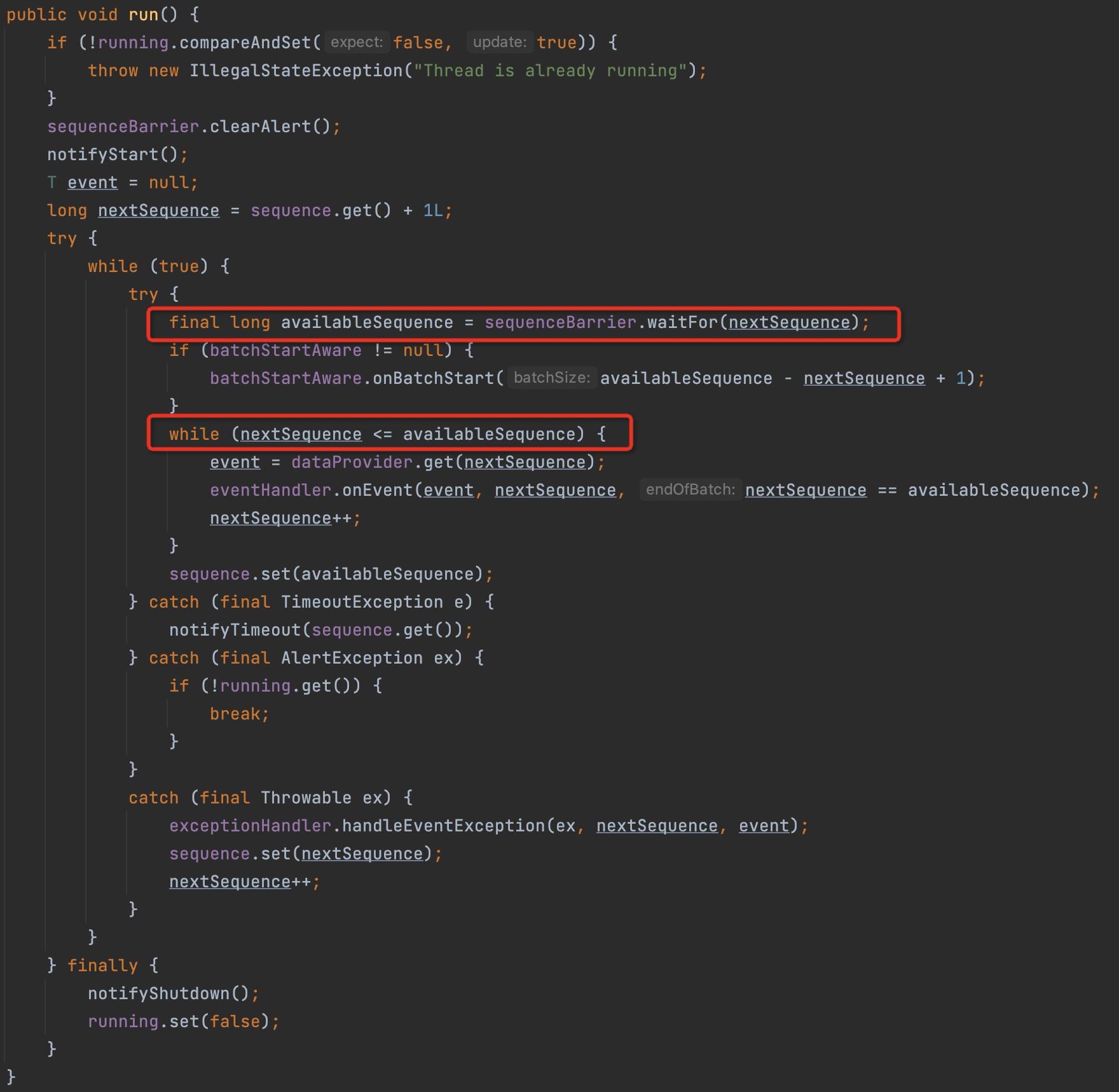
如果序列器一次可以返回一批序号,则可以在一个批次处理,即降低了获取序号的次数。
本文就介绍到这里了,经过上述的讲述,大家对disruptor无锁化的实现原理应该有了一个比较全面而清晰的理解,也欢迎大家关注我的公众号,加我微信dingwpmz,共同探讨交流。
以上是关于《重学Java高并发》disruptor是如何做到百万级吞吐?的主要内容,如果未能解决你的问题,请参考以下文章