机器学习-4.开发流程算法基本认知
Posted wyply115
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-4.开发流程算法基本认知相关的知识,希望对你有一定的参考价值。
1. 机器学习开发流程
- 我们作为机器学习的开发工程师首先要明确自己学习的定位,也就是确定学习边界。
- 大部分复杂模型的算法设计都是由算法工程师去做的,我们只需要:
- 分析很多的数据;
- 分析具体的业务;
- 应用常见的算法;
- 特征工程、调参数、优化。
- 我们学习应达到一下目的:
- 学会分析问题、使用机器学习算法的目标,想要使得算法完成什么样的任务。
- 掌握算法基本思想原理,学会对不同问题用对应的算法来解决。
- 学会利用库或框架解决问题。
- 开发流程:
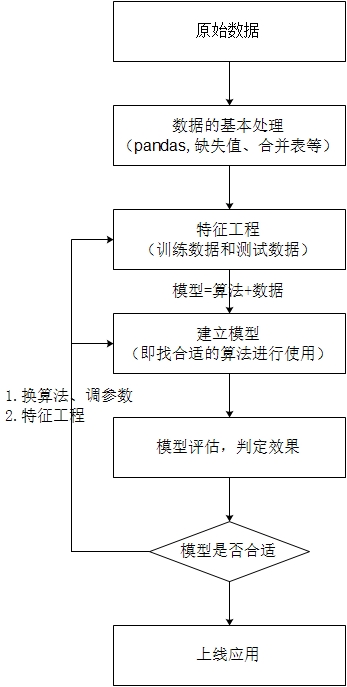
2. 机器学习算法分类
- 数据类型
- 离散型数据:由记录不同类别个体的数目所得到的数据,又称计数数据,所有这些数据全部都是整数,而且不能再细分,也不能进一步提高他们的精确度。
- 连续性数据:变量可以在某个范围内取任一数,即变量的取值可以是连续的,如:长度、时间、质量值等,这类整数通常是非整数,含有小数部分。
- 注:离散型是区间内不可分,连续型是区间内可分。
- 数据的类型将是机器学习模型不同、问题不同,进行处理的依据。
- 算法分类
- 监督学习(有特征值和目标值)
– 分类:K近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
– 回归:线性回归、岭回归
– 标注:隐马尔科夫模型(不重要) - 无监督学习(只有特征值)
– 聚类:k-means
- 分类算法对应-目标值是离散型数据
- 回归算法对应-目标值是连续型数据
3. 转换器与估计器
- 转换器是实现了特征工程的API,例如前几篇文章的示例中的fit_transform()等。
- 估计器是实现了算法的API,在sklearn中有:
- 用于分类的估计器:
– sklearn.neighbors :k-近邻算法
– sklearn.naive_bayes :贝叶斯
– sklearn.linear_model.LogisticRegression :逻辑回归
– sklearn.tree :决策树与随机森林 - 用于回归的估计器
– sklearn.linear_model.LinearRegression :线性回归
– sklearn.linear_model.Ridge :岭回归
以上是关于机器学习-4.开发流程算法基本认知的主要内容,如果未能解决你的问题,请参考以下文章