机器学习Sklearn的k近邻算法api初步使用
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习Sklearn的k近邻算法api初步使用相关的知识,希望对你有一定的参考价值。
目录
1 k近邻算法api初步使用
K近邻算法介绍:https://blog.csdn.net/ZGL_cyy/article/details/125583129
- 机器学习流程复习:
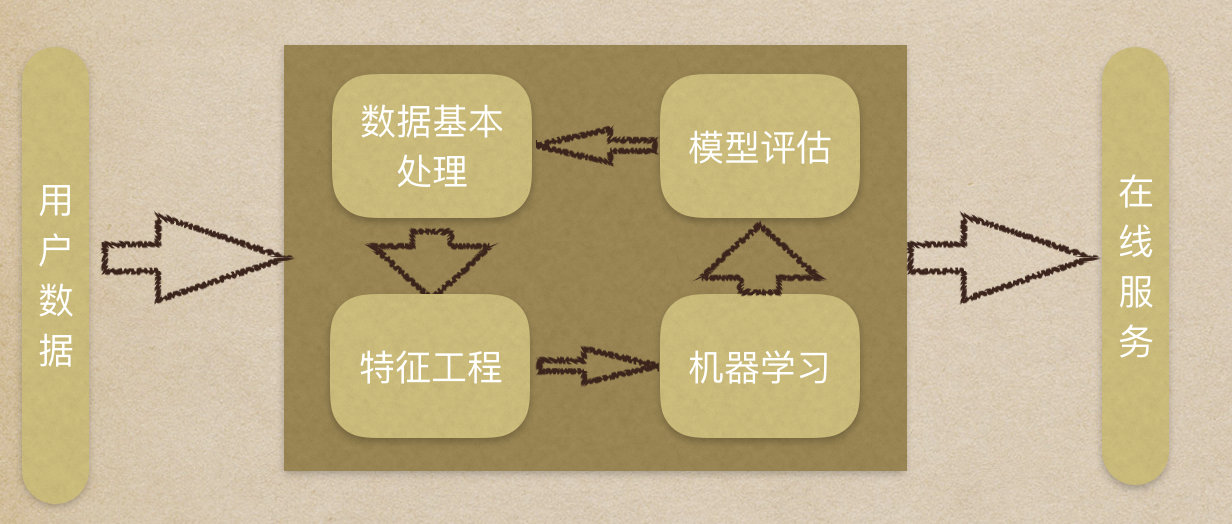
- 1.获取数据集
- 2.数据基本处理
- 3.特征工程
- 4.机器学习
- 5.模型评估
2 Scikit-learn工具介绍
机器学习Sklearn数据集:https://blog.csdn.net/ZGL_cyy/article/details/125469443

- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
- 目前稳定版本0.19.1
2.1 安装
pip3 install scikit-learn==0.19.1
安装好之后可以通过以下命令查看是否安装成功
import sklearn
- 注:安装scikit-learn需要Numpy, Scipy等库
2.2 Scikit-learn包含的内容

- 分类、聚类、回归
- 特征工程
- 模型选择、调优
3 K-近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
- 参数介绍:
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
4 案例
4.1 步骤分析
- 1.获取数据集
- 2.数据基本处理(该案例中省略)
- 3.特征工程(该案例中省略)
- 4.机器学习
- 5.模型评估(该案例中省略)
4.2 代码过程
- 步骤一:导入模块
from sklearn.neighbors import KNeighborsClassifier
- 步骤二:构造数据集
- 数据集格式一:
x = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
- 数据集格式二:
特征数也就是几维计算,x是数据,y是结果
x = [[39,0,31],[3,2,65],[2,3,55],[9,38,2],[8,34,17],[5,2,57],[21,17,5],[45,2,9]]
y = [0,1,2,2,2,2,1,1]
- 步骤三:机器学习 – 模型训练
# 实例化API
estimator = KNeighborsClassifier(n_neighbors=1)
# 使用fit方法进行训练
estimator.fit(x, y)
estimator.predict([[1]])
# 数据集格式二对应的测试数据
# estimator.predict([[23,3,17]])
-完整代码
from sklearn.neighbors import KNeighborsClassifier
# 1.构造数据
x = [[1], [2], [3], [4]]
y = [0, 0, 1, 1]
# 2.训练模型
# 2.1 实例化一个估计器对象
estimator = KNeighborsClassifier(n_neighbors=3)
# 2.2 调用fit方法,进行训练
estimator.fit(x, y)
# 3.数据预测
ret = estimator.predict([[2.51]])
print(ret)
# 可以这样理解, x是特征值, 是dataframe形式理解为二维的[[]],
# y表示的目标值, 可以表示为series, 表示为一维数组[]
ret1 = estimator.predict([[-1]])
print(ret1)
运行结果

5 小结
- sklearn的优势:
- 文档多,且规范
- 包含的算法多
- 实现起来容易
- knn中的api
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
以上是关于机器学习Sklearn的k近邻算法api初步使用的主要内容,如果未能解决你的问题,请参考以下文章