AndroidApp攻防之代码混淆
Posted 宾有为
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AndroidApp攻防之代码混淆相关的知识,希望对你有一定的参考价值。
目录
什么是混淆?
含义:
代码混淆(Obfuscation)是将计算机程序的源代码或机器代码,转换成功能上等价,但是难于阅读和理解的形式的行为。 — 维基百科
android代码混淆,又称Android混淆,是伴随着Android系统的流行而产生的一种AndroidAPP保护技术,用于保护APP不被破解和逆向分析。 — 百度百科
混淆优点:
1.优化字节码并删除未使用的指令
2.检测并删除未使用的类、字段、方法和属性,降低了Apk的体积。
3.将类、类成员、方法重命名为无意义的简短名称,增加了逆向成本。
混淆缺点:
1.被混淆的代码难于理解,因此调试也变得困难起来。开发人员通常需要保留原始的未混淆的代码用于调试(例:继承Activity、Fragment类)。
2.代码混淆并不能真正阻止反向工程,只能增大其难度。因此,对于对安全性要求很高的场合,仅仅使用代码混淆并不能保证源代码的安全(往往还需要对apk进行加固)。
混淆语法
输入/输出选项 — Input/Output Options
- -include 文件名
递归读取给定文件名中的配置选项。
- -basedirectory 目录名
指定这些配置参数或此配置文件中所有后续相对文件名的基本目录。
- -injars 类路径
指定要处理的应用程序的输入JAR(或WAR、EAR、ZIP或目录)。这些JAR中的类文件将被处理并写入输出JAR。默认情况下,将复制任何非类文件而不进行更改。请注意任何临时文件(如IDE创建的文件),尤其是直接从目录中读取输入文件时。可以过滤类路径中的条目,如过滤器部分所述。为了更好的可读性,可以使用多个injars选项指定类路径条目。
- -outjars 类路径
指定输出JAR(或WAR、EAR、ZIP或目录)的名称。前面-injars选项的处理输入将写入命名JAR。这允许您将输入jar组的内容收集到相应的输出jar组中。此外,可以过滤输出条目,如过滤器部分所述。然后,每个处理过的类文件或资源文件都会被写入第一个输出条目,并在输出jar组中使用匹配的过滤器。
必须避免让输出文件覆盖任何输入文件。为了更好的可读性,可以使用多个-outjars选项指定类路径条目。如果没有任何-outjars选项,就不会编写jar。
- -libraryjars 类路径
指定要处理的应用程序的库JAR(或WAR、EAR、ZIP或目录)。这些JAR中的文件不会包含在输出JAR中。指定的库JAR应至少包含由应用程序类文件扩展的类文件。只调用的库类文件不需要存在,尽管它们的存在可以改善优化步骤的结果。可以过滤类路径中的条目,如过滤器部分所述。为了更好的可读性,可以使用多个libraryjars选项指定类路径条目。
请注意,在查找库类时,不考虑为运行ProGuard设置的引导路径和类路径。这意味着您必须显式地指定代码将使用的运行时jar。尽管这看起来很麻烦,但它允许您处理针对不同运行时环境的应用程序。例如,只需指定适当的运行时jar,就可以处理J2SE应用程序和JME MIDlet。
- -skipnonpubliclibraryclasses
指定在读取库JAR时跳过非公共类,以加快处理速度并减少ProGuard的内存使用。默认情况下,ProGuard读取非公共和公共图书馆类。然而,如果非公共类不影响输入jar中的实际程序代码,它们通常是不相关的。忽略它们会加速ProGuard,而不会影响输出。不幸的是,一些库,包括最近的JSE运行时库,包含由公共库类扩展的非公共库类。这样就不能使用此选项。如果由于设置了此选项而找不到类,ProGuard将打印警告。
- -dontskipnonpubliclibraryclasses
指定不忽略非公共库类。从4.5版开始,这是默认设置。
- -dontskipnonpubliclibraryclassmembers
指定不忽略包可见库类成员(字段和方法)。默认情况下,ProGuard在解析库类时跳过这些类成员,因为程序类通常不会引用它们。然而,有时程序类与库类驻留在同一个包中,它们确实引用了它们的包可见类成员。在这些情况下,为了确保处理后的代码保持一致,实际读取类成员可能很有用。
- -keepdirectories [目录过滤]
指定要保留的目录结构,默认情况下会删除所有目录以减小jar的大小。
- -target 版本号
指定要在处理的类文件中设置的版本号。版本号可以是1.0、1.1、1.2、1.3、1.4、1.5(或仅5)、1.6(或仅6)或1.7(或仅7)中的一个。默认情况下,类文件的版本号保持不变。例如,您可能希望通过更改类文件的版本号并对其进行预验证,将其升级到Java 6。
- -forceprocessing
指定处理输入,即使输出似乎是最新的。最新性测试基于对指定输入、输出和配置文件或目录的日期戳的比较。
保留选项 — Keep Options
- -keep [,modifier,…] class_specification
指定要保留为代码入口点的类和类成员(字段和方法)。例如,为了保留应用程序,可以指定主类及其主方法。
- -keepclassmembers [,modifier,…] class_specification
指定要保留的类成员(如果它们的类也被保留)。例如,您可能希望保留实现可序列化接口的类的所有序列化字段和方法。
- -keepclasseswithmembers [,modifier,…] class_specification
指定要保留的类和类成员,条件是所有指定的类成员都存在。例如,您可能希望保留所有具有main方法的应用程序,而不必显式列出它们。
- -keepnames class_specification
指定要保留其名称的类和类成员(如果在收缩阶段未删除)。例如,您可能希望保留实现可序列化接口的类的所有类名,以便处理的代码与任何最初序列化的类保持兼容。完全不用的类仍然可以删除。仅适用于模糊处理。
- -keepclassmembernames class_specification
指定要保留其名称的类成员(如果在收缩阶段未删除)。例如,在处理JDK 1.2或更早版本编译的库时,您可能希望保留合成类$methods的名称,以便在处理使用已处理库的应用程序时,混淆器可以再次检测到它(尽管ProGuard本身不需要)。仅适用于模糊处理。
- -keepclasseswithmembernames class_specification
指定要保留其名称的类和类成员,条件是收缩阶段后所有指定的类成员都存在。例如,您可能希望保留所有本机方法名称及其类的名称,以便处理后的代码仍然可以与本机库代码链接。根本不使用的本机方法仍然可以删除。如果使用了类文件,但没有使用其本机方法,则其名称仍会被混淆。仅适用于模糊处理。
- -printseeds [filename]
指定详细列出由各种-keep选项匹配的类和类成员。列表将打印到标准输出或给定文件。该列表对于验证是否真的找到了预期的类成员非常有用,尤其是在使用通配符的情况下。例如,您可能希望列出所有应用程序或您保留的所有小程序。
缩减选项 — Shrinking Options
- -dontshrink
指定不收缩输入类文件。默认情况下,应用收缩;所有类和类成员都将被删除,但“各种保留”选项列出的类和类成员以及它们直接或间接依赖的类和类成员除外。在每个优化步骤之后也会应用一个收缩步骤,因为一些优化可能会删除更多类和类成员。
- -printusage [filename]
指定列出输入类文件的死代码。列表将打印到标准输出或给定文件。例如,可以列出应用程序中未使用的代码。仅适用于收缩时。
- -whyareyoukeeping class_specification
指定打印有关在收缩步骤中保留给定类和类成员的原因的详细信息。如果您想知道为什么输出中存在某个给定元素,这可能很有用。一般来说,可能有许多不同的原因。对于每个指定的类和类成员,此选项将最短的方法链打印到指定的种子或入口点。在当前的实现中,打印出来的最短链有时可能包含循环扣减——这些并不反映实际的收缩过程。如果指定了-verbose选项,则跟踪包括完整字段和方法签名。仅适用于收缩时。
优化选项 — Optimization Options
- -dontoptimize
指定不优化输入类文件。默认情况下,已启用优化;所有方法都在字节码级别进行了优化。
- -optimizations optimization_filter
在更细粒度的级别上指定要启用和禁用的优化。仅在优化时适用。
- -optimizationpasses n
指定要执行的优化过程数。默认情况下,只执行一次传递。多次通过可能会导致进一步的改进。如果优化通过后未发现任何改进,则优化结束。仅在优化时适用。
- -assumenosideeffects class_specification
指定没有任何副作用的方法(可能返回值除外)。在优化步骤中,ProGuard将删除对这些方法的调用,前提是它可以确定没有使用返回值。请注意,ProGuard将分析您的程序代码以自动找到此类方法。它不会分析库代码,因此此选项对库代码非常有用。例如,可以指定方法系统。currentTimeMillis(),以便删除对它的任何空闲调用。请注意,ProGuard将该选项应用于指定方法的整个层次结构。仅在优化时适用。一般来说,做出假设可能是危险的;你可以很容易地破解处理过的代码。只有当你知道自己在做什么时才使用这个选项!
- -allowaccessmodification
指定在处理过程中可以扩展类和类成员的访问修饰符。这可以改善优化步骤的结果。例如,当内联一个公共getter时,可能需要将访问的字段也公开。尽管Java的二进制兼容性规范在形式上并不要求这样做(cfr.Java语言规范,第二版,第13.4.6节),但有些虚拟机在处理代码时会遇到其他问题。仅适用于优化时(以及使用-repackageclasses选项进行模糊处理时)。
反提示:在处理要用作库的代码时,可能不应该使用此选项,因为在API中未设计为公共的类和类成员可能会变成公共的。
- -mergeinterfacesaggressively
指定可以合并接口,即使其实现类未实现所有接口方法。这可以通过减少类的总数来减少输出的大小。请注意,Java的二进制兼容性规范允许这样的构造(cfr.Java语言规范,第二版,第13.5.3节),即使Java语言中不允许这样的构造(cfr.Java语言规范,第二版,第8.1.4节)。仅在优化时适用。
计数器指示:设置此选项可能会降低某些JVM上已处理代码的性能,因为高级即时编译倾向于使用更少的实现类来支持更多的接口。更糟糕的是,一些JVM可能无法处理生成的代码。尤其是:Sun的JRE 1.3在一个类中遇到超过256个Miranda方法(没有实现的接口方法)时可能会抛出内部错误。
混淆选项 — Obfuscation Options
- -dontobfuscate
指定不混淆输入类的文件。默认情况下,应用模糊处理;类和类成员会收到新的短随机名称,不同的保留选项列出的名称除外。将删除对调试有用的内部属性,例如源文件名、变量名和行号。
- -printmapping [filename]
指定打印已重命名的类和类成员从旧名称到新名称的映射。映射将打印到标准输出或给定文件。例如,在后续的增量模糊处理中,或者如果您想再次理解模糊化的堆栈跟踪,则需要使用它。仅适用于模糊处理。
- -applymapping filename
指定重用在前一次ProGuard模糊处理运行中打印的给定名称映射。映射文件中列出的类和类成员将接收随它们一起指定的名称。未提及的类和类成员将收到新名称。映射可以引用输入类和库类。该选项可用于增量模糊处理,即处理现有代码段的附加组件或小补丁。在这种情况下,您应该考虑是否还需要选项–UnimuleCelsAsMeNeNeNess。只允许一个映射文件。仅适用于模糊处理。
- -obfuscationdictionary filename
指定一个文本文件,其中所有有效单词都用作模糊字段和方法名。默认情况下,“a”、“b”等短名称用作模糊名称。例如,使用模糊处理字典,可以指定保留关键字的列表,或使用外来字符的标识符。空格、标点符号、重复单词和#符号后的注释将被忽略。请注意,模糊处理词典很难改善模糊处理。像样的编译器可以自动替换它们,而这种效果可以通过用更简单的名称再次混淆而完全消除。最有用的应用程序是指定通常已经存在于类文件中的字符串(例如“Code”),从而稍微减小类文件的大小。仅适用于模糊处理。
- -classobfuscationdictionary filename
指定一个文本文件,其中所有有效单词都用作模糊的类名。模糊处理字典类似于选项之一——模糊处理字典。仅适用于模糊处理。
- -packageobfuscationdictionary filename
指定一个文本文件,其中所有有效单词都用作模糊的包名。模糊处理字典类似于选项之一——模糊处理字典。仅适用于模糊处理。
- -overloadaggressively
指定在模糊处理时应用主动重载。然后,多个字段和方法可以获得相同的名称,只要它们的参数和返回类型不同(不仅仅是它们的参数)。这个选项可以使处理后的代码更小(更难理解)。仅适用于模糊处理。
- -useuniqueclassmembernames
指定将相同的模糊名称分配给具有相同名称的类成员,并将不同的模糊名称分配给具有不同名称的类成员(对于每个给定的类成员签名)。如果没有该选项,更多的类成员可以映射到相同的短名称,如“a”、“b”等。因此,该选项略微增加了生成代码的大小,但它确保在后续增量模糊处理步骤中始终遵守保存的模糊处理名称映射。
- -dontusemixedcaseclassnames
指定在混淆时不生成大小写混合的类名。默认情况下,模糊的类名可以包含大写字符和小写字符的混合。这创造了完全可以接受和使用的罐子。只有在使用不区分大小写的归档系统(比如Windows)的平台上解包jar,解包工具才能让类似名称的类文件相互覆盖。解包后会自毁的代码!真正想在Windows上解压JAR的开发人员可以使用此选项关闭此行为。请注意,模糊的罐子会因此变得更大。仅适用于模糊处理。
- -keeppackagenames [package_filter]
指定不混淆给定的包名称。可选过滤器是一个以逗号分隔的包名列表。包名称可以包含?、*,和**通配符,前面可以加上!否定者。仅适用于模糊处理。
- -flattenpackagehierarchy [package_name]
指定通过将重命名的所有包移动到单个给定父包中来重新打包这些包。如果没有参数或使用空字符串(“”),包将被移动到根包中。此选项是进一步混淆包名称的一个示例。它可以使处理后的代码更小,更难理解。仅适用于模糊处理。
- -repackageclasses [package_name]
指定通过将重命名的所有类文件移动到单个给定包中来重新打包它们。如果没有参数或使用空字符串(“”),则包将被完全删除。此选项将覆盖-flattenpackagehierarchy选项。这是进一步混淆包名的另一个例子。它会使经过处理的代码变得更小,更难理解。它不推荐使用的名称是-defaultpackage。仅适用于模糊处理。
- -keepattributes [attribute_filter]
指定要保留的任何可选属性。可以使用一个或多个-keepattributes指令指定属性。可选过滤器是一个以逗号分隔的属性名称列表。属性名称可以包含?、*,和**通配符,前面可以加上!否定者。典型的可选属性有Exception、Signature、Disprecated、SourceFile、SourceDir、LineNumberTable、LocalVariableTable、LocalVariableTypeTable、Synthetic、EnclosingMethod、RuntimeVisibleAnnotations、RuntimeVisibleParameterAnnotations和AnnotationDefault。也可以指定InnerClasses属性名称,它引用该属性的源名称部分。例如,在处理库时,至少应该保留Exception、InnerClass和Signature属性。还应该保留SourceFile和LineNumberTable属性,以便生成有用的模糊堆栈跟踪。最后,如果代码依赖于注释,则可能需要保留注释。仅适用于模糊处理。
- -keepparameternames
指定保留保留的参数名称和方法类型。该选项实际上保留了调试属性LocalVariableTable和LocalVariableTypeTable的精简版本。它在处理库时非常有用。一些IDE可以使用这些信息来帮助使用该库的开发人员,例如工具提示或自动完成。仅适用于模糊处理。
- -renamesourcefileattribute [string]
指定要放入类文件的SourceFile属性(和SourceDir属性)中的常量字符串。请注意,属性必须首先存在,因此还必须使用-keepattributes指令显式保留它。例如,您可能希望处理后的库和应用程序生成有用的模糊堆栈跟踪。仅适用于模糊处理。
- -adaptclassstrings [class_filter]
指定与类名对应的字符串常量也应模糊处理。在没有过滤器的情况下,所有与类名对应的字符串常量都会被调整。使用过滤器时,只会调整与过滤器匹配的类中的字符串常量。例如,如果您的代码包含大量引用类的硬编码字符串,并且您不希望保留它们的名称,那么您可能希望使用此选项。主要适用于模糊处理,尽管相应的类也会自动保留在收缩步骤中。
- -adaptresourcefilenames [file_filter]
根据相应类文件(如果有)的模糊名称,指定要重命名的资源文件。如果没有筛选器,则会重命名与类文件对应的所有资源文件。使用过滤器时,只会重命名匹配的文件。例如,请参见处理资源文件。仅适用于模糊处理。
- -adaptresourcefilecontents [file_filter]
指定要更新其内容的资源文件。资源文件中提到的任何类名都会根据相应类(如果有)的模糊名称重命名。如果没有过滤器,所有资源文件的内容都会更新。使用过滤器,只更新匹配的文件。资源文件使用平台的默认字符集进行解析和写入。可以通过设置环境变量LANG或Java系统属性文件来更改此默认字符集。编码。有关示例,请参见处理资源文件。仅适用于模糊处理。
预验证选项 — Preverification Options
- -dontpreverify
指定不预先验证已处理的类文件。默认情况下,如果类文件的目标是Java Micro Edition或Java 6或更高版本,则会预先验证它们。对于Java Micro Edition,需要进行预验证,因此如果指定此选项,则需要对处理后的代码运行外部预验证程序。对于Java 6,不需要预先验证,但它提高了Java虚拟机中类加载的效率。
- -microedition
指定已处理的类文件针对Java Micro Edition。然后,前置验证程序将添加适当的StackMap属性,这些属性不同于Java Standard Edition的默认StackMapTable属性。例如,如果正在处理MIDlet,则需要此选项。
一般选择 — General Options
- -verbose
指定在处理过程中写出更多信息。如果程序以异常终止,此选项将打印出整个堆栈跟踪,而不仅仅是异常消息。
- -dontnote [class_filter]
指定不打印有关配置中潜在错误或遗漏的注释,例如类名中的拼写错误,或可能有用的缺少选项。可选的过滤器是一个正则表达式;ProGuard不会打印具有匹配名称的类的注释。
- -dontwarn [class_filter]
指定完全不对未解决的引用和其他重要问题发出警告。可选的过滤器是一个正则表达式;ProGuard不会打印关于具有匹配名称的类的警告。忽视警告可能很危险。例如,如果处理确实需要未解析的类或类成员,则处理后的代码将无法正常运行。
- -ignorewarnings
指定打印有关未解决的引用和其他重要问题的任何警告,但在任何情况下都要继续处理。忽视警告可能很危险。例如,如果处理确实需要未解析的类或类成员,则处理后的代码将无法正常运行。只有当你知道自己在做什么时才使用这个选项!
- -printconfiguration [filename]
指定写出已分析的整个配置,以及包含的文件和替换的变量。结构将打印到标准输出或给定文件。这有时对调试配置或将XML配置转换为更可读的格式很有用。
- -dump [filename]
指定在任何处理后写出类文件的内部结构。结构将打印到标准输出或给定文件。例如,您可能希望写出给定jar文件的内容,而根本不处理它。
常用的混淆语法
- 混淆前需要先在模块对应的
build.gradle开启混淆
buildTypes
release
// 是否开启混淆
minifyEnabled true
// proguard-rules.pro指当前模块的混淆文件
proguardFiles getDefaultProguardFile('proguard-android-optimize.txt'), 'proguard-rules.pro'
- 接着打开
proguard-rules.pro文件输入混淆语法,常用语法如下所示:
# 指定代码的压缩级别
-optimizationpasses 5
# # 忽略警告,避免打包时某些警告出现(慎用)
-ignorewarnings
# 混淆时不生成大小写混合的类名
-dontusemixedcaseclassnames
# 混淆第三方jar
-dontskipnonpubliclibraryclasses
# 不预先验证已处理的类文件
-dontpreverify
# 混淆运行出现异常时打印日志在控制台
-verbose
# 混淆时所采用的算法
-optimizations !code/simplification/arithmetic,!field/*,!class/merging/*
# 保持某个包的类不被混淆
-keep class com.umeng.** *;
# 保持自定义的类不被混淆
-keep class 类名
# 保留继承了哪些类的类不被混淆
-keep public class * extends android.app.Service
-keep public class * extends android.app.Activity
-keep public class * extends android.app.Application
-keep public class * extends android.preference.Preference
-keep public class * extends android.content.ContentProvider
-keep public class * extends android.content.BroadcastReceiver
-keep public class com.android.vending.licensing.ILicensingService
# 保留实现了Serializable接口方法的类不被混淆
-keepclassmembers class * implements java.io.Serializable *;
# 保持实现Parcelable接口方法的类不被混淆
-keepclassmembers class * implements android.os.Parcelable
# 保持自定义控件类不被混淆
-keepclasseswithmembers class *
public <init>(android.content.Context, android.util.AttributeSet);
# 保持 native 方法不被混淆
-keepclasseswithmembernames class *
native <methods>;
# 保持自定义控件类不被混淆
-keepclasseswithmembers class *
public <init>(android.content.Context, android.util.AttributeSet);
public <init>(android.content.Context, android.util.AttributeSet, int);
# 保持枚举 enum 类不被混淆
-keepclassmembers enum *
public static **[] values();
public static ** valueOf(java.lang.String);
混淆注意事项
- debug不建议开启混淆,会增加编译的时间。
- 使用WebView和调用的类和方法要屏蔽混淆。
- 混淆的文件名最好只包含字母、横线、小数点。
- 保持第三方jar包不被混淆,需要把keep class 提到dontwarn前面。
- jni的方法要屏蔽混淆,因为so库要求包名、类名、函数名完全一致。
- Activity、Fragment、Service、BroadcastReceiver、ContentProvider等需要测试的类为方便测试,通常不混淆。
- 对某些特殊的类或方法屏蔽混淆,可能会在布局文件中直接引用类名或方法名,包括自定义控件、布局中onClick属性指定的方法等。
混淆前后对比
大小对比
apk打包成功后,使用Android Studio的Analyze apk功能即可自动分析apk的大小,从图中可看出混淆前的apk classes.dex文件混淆后文件大小直接减半!

再看整个apk的体积,已由原先的8944KB瘦身成了3953KB。
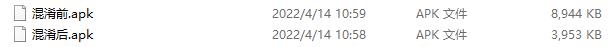
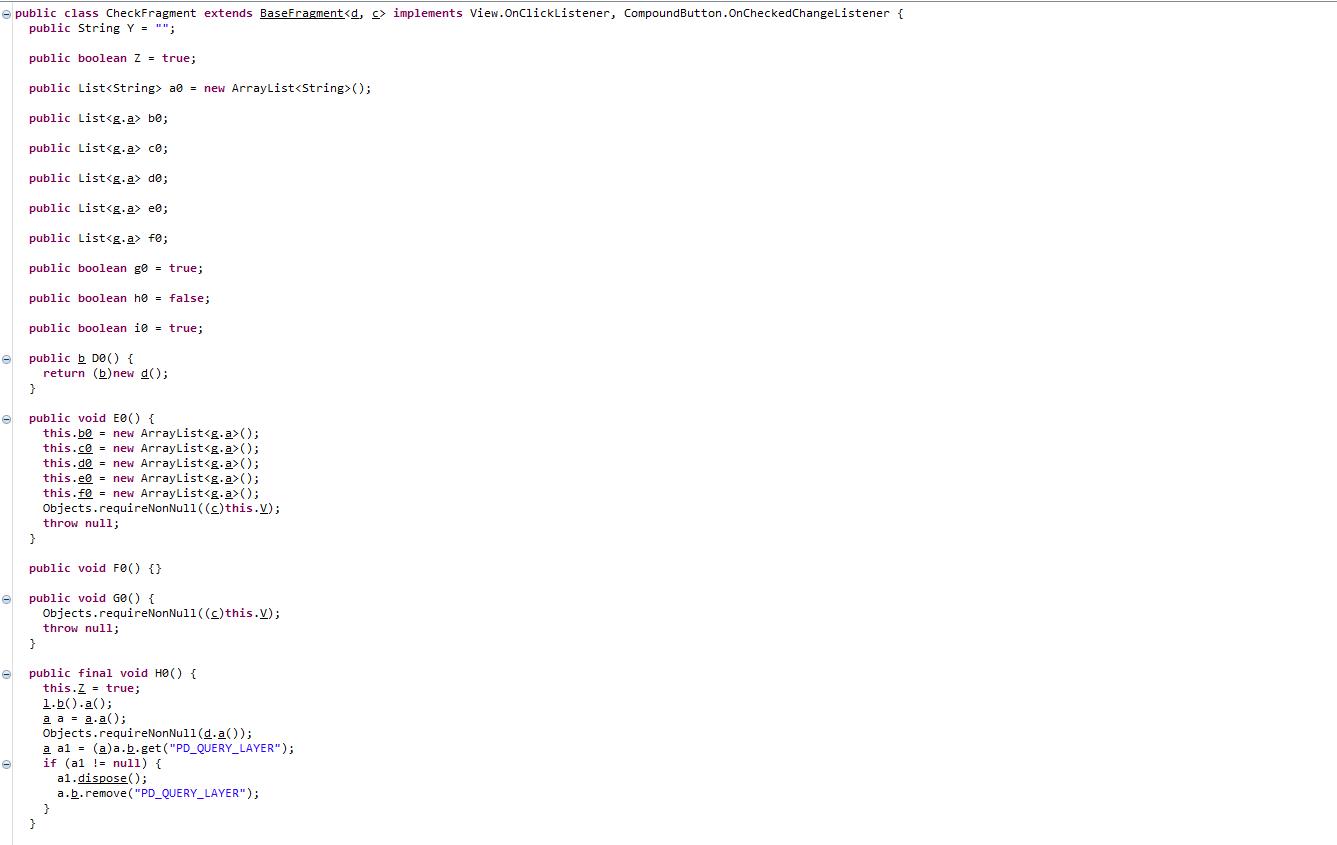
源码对比
代码混淆前CheckFragment.class代码

代码混淆后CheckFragment.class代码
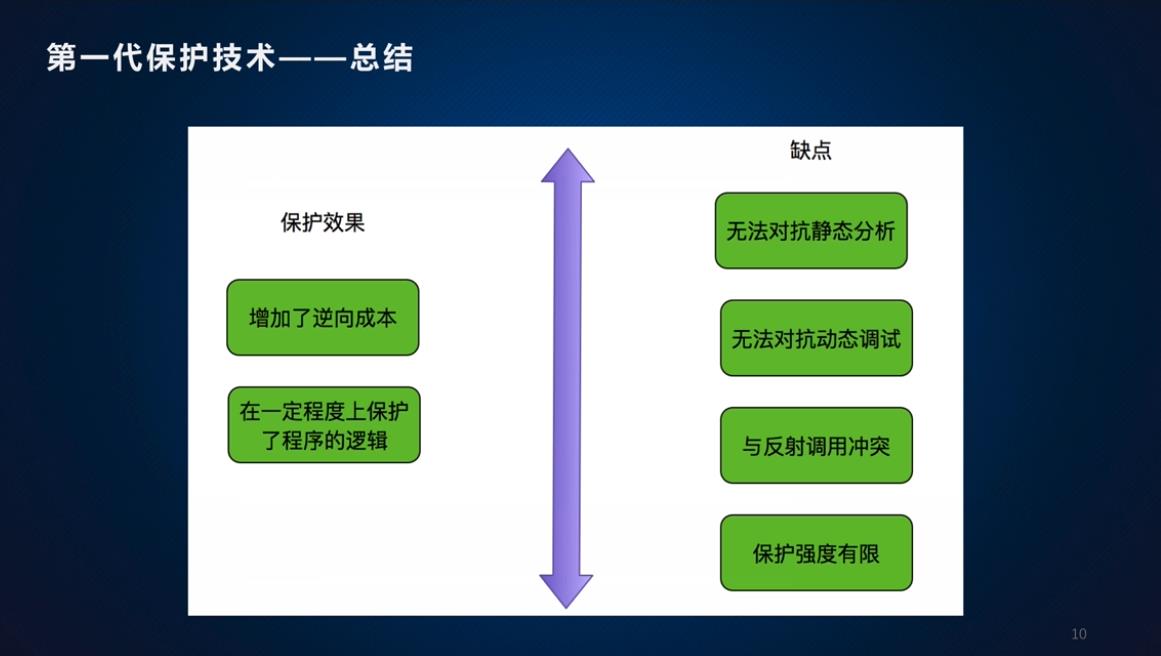
Android的安全保护技术

代码混淆保护
代码混淆保护技术,包含了名称混淆、字符串加密、反射替换(将代码的实现方式改为反射)、花指令(添加大量无用的代码)

优缺点:
Dex文件整体加密保护
Dex文件整体加密保护技术,是将dex文件进行加密,在app运行过程中对dex文件进行解密执行来达到保护dex文件的目的。

优缺点:

Dex函数抽取加密保护
Dex函数抽取加密保护技术,是加固时分析要保护的文件,对dex文件类中的方法抽取方法进行加密,在每个类中插入方法修复的代码,当类中的代码被调用时,会对类中的方法进行解密。
优缺点: 
混合加密保护
混合加密保护技术,即对dex文件进行整体加密保护,又对dex文件类中的方法进行加密保护。
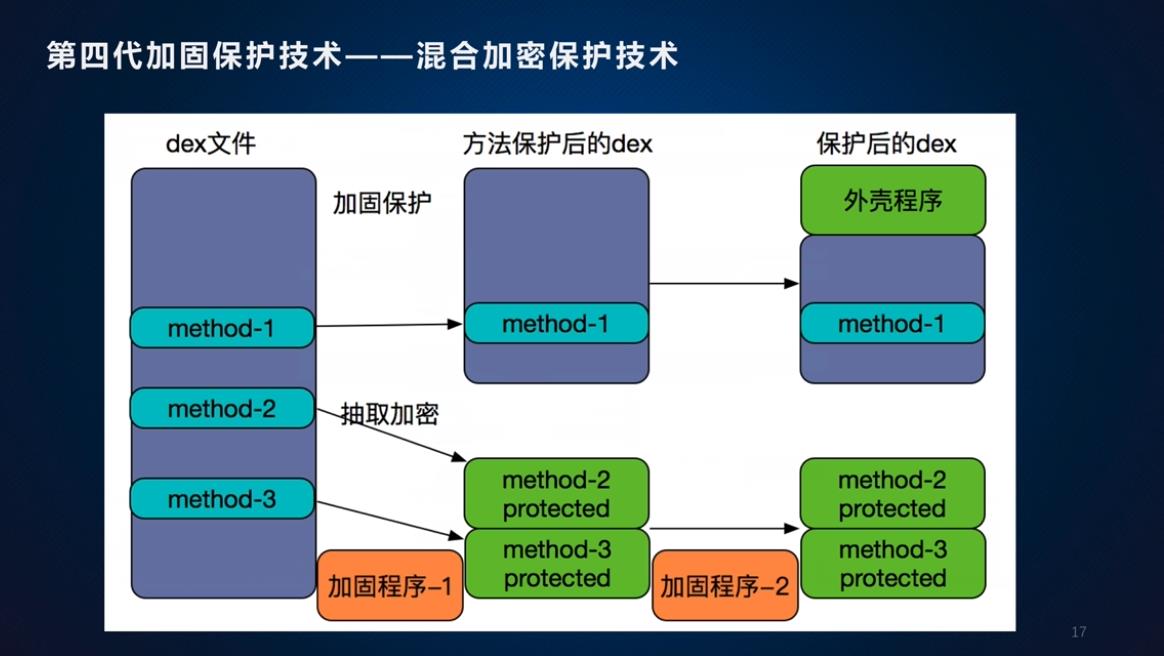
在程序运行过程中会执行外壳程序,会对dex文件进行解密执行,运行到需要解密的方法才会对方法进行修复。
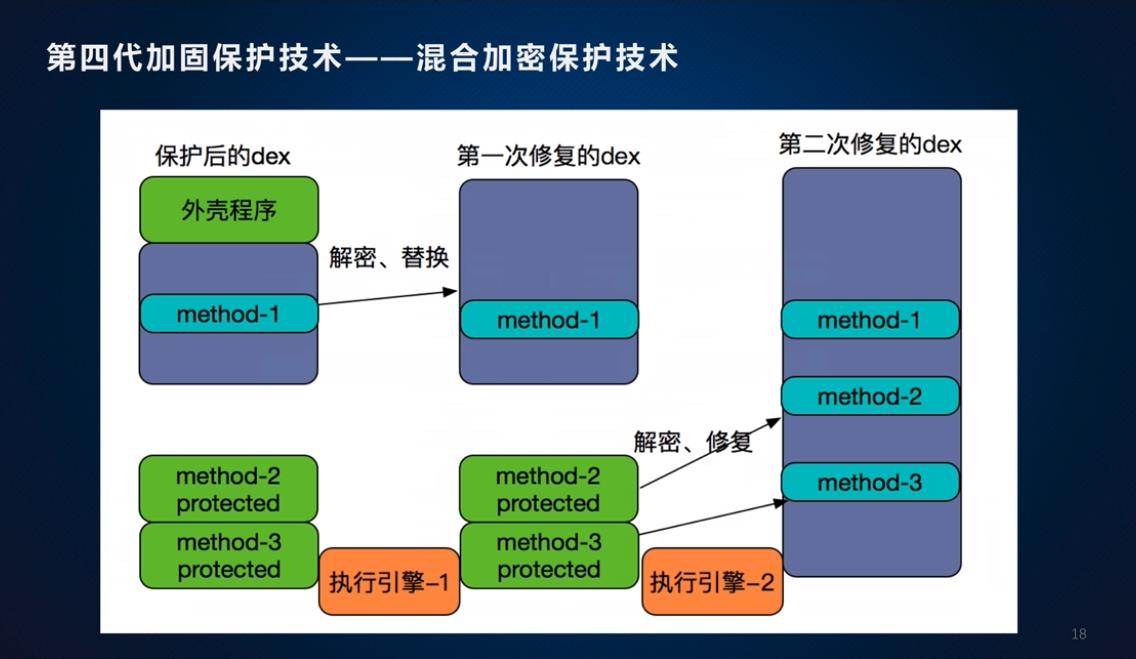
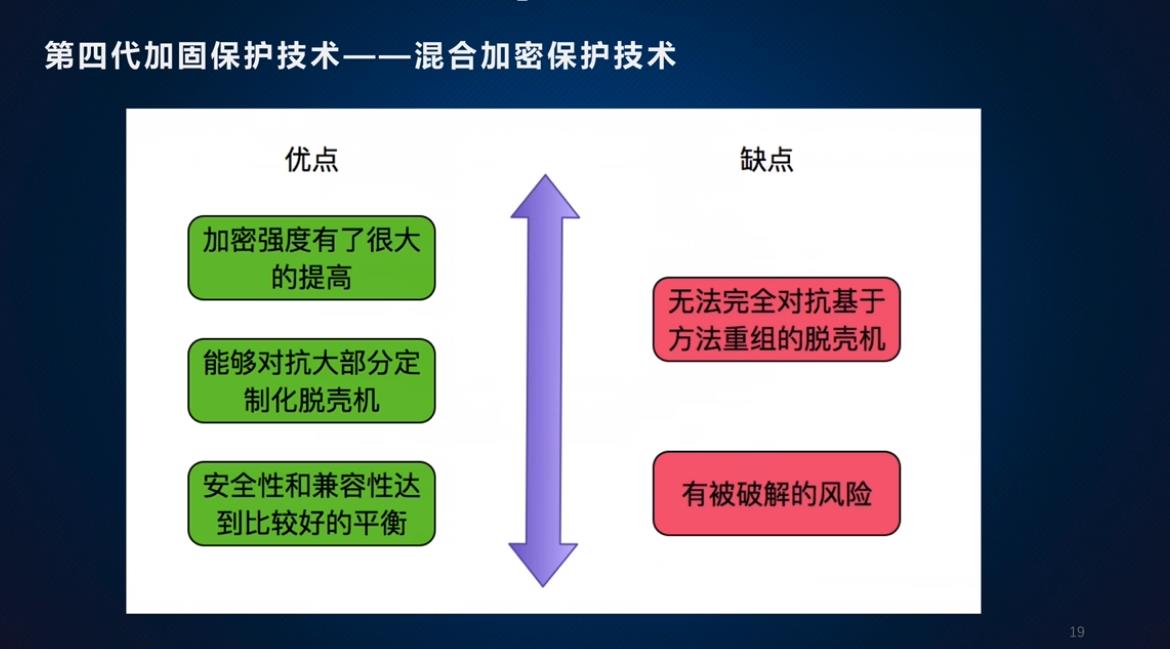
优缺点:
虚拟机保护
虚拟机保护技术,是将dex文件中正常的指令替换成自定义的虚拟,由自己附带的虚拟机对这些虚拟指令解释执行,并且自己附带的虚拟机执行的结果和原dex文件的代码在Android虚拟机执行结果完全一致。是业界公认的、安全强度最高的保护技术。

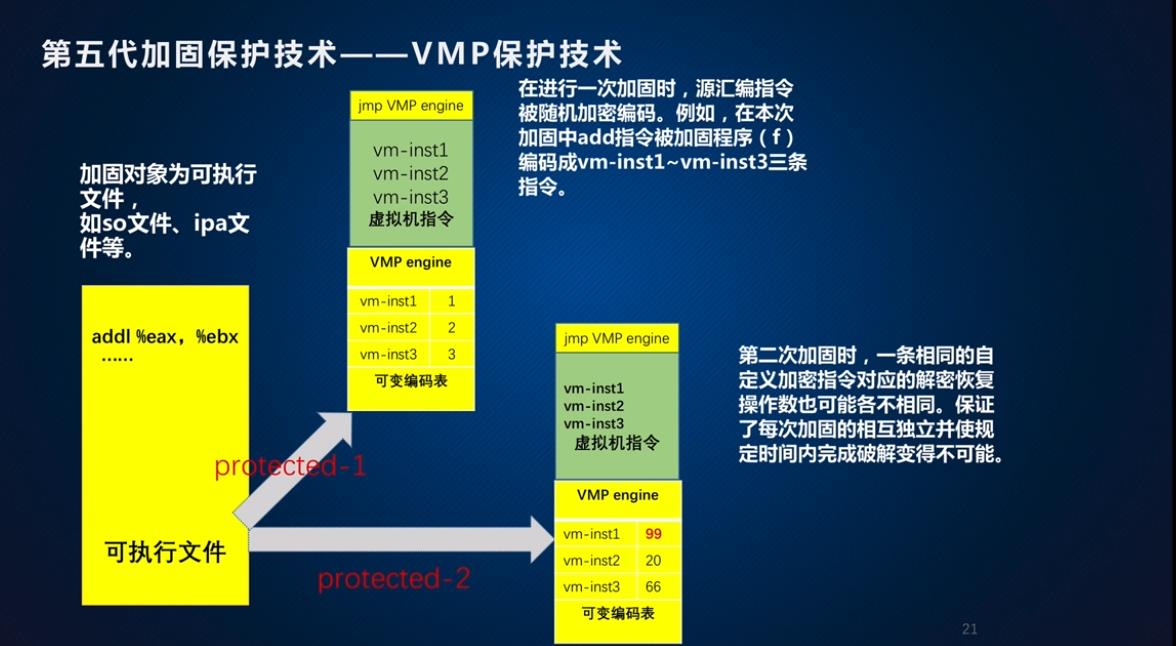
优缺点:

结束语
看完了五代加固保护技术,是否发现,混淆其实是最容易被攻破的防护手段,但凡哪位别有用心的人稍微耐心点,代码其实和没混淆也没多大关系。正所谓,术业有专攻。在App安全这一块可以交给专业人士负责,例如:360加固。但是也不要忘了混淆,apk体积优化可是少不了混淆的喔!
参考资料:
1.代码混淆
2.Android混淆
3.ProGuard官方文档
4.常用Android程序逆向与保护技术
以上是关于AndroidApp攻防之代码混淆的主要内容,如果未能解决你的问题,请参考以下文章