MMNet: Muscle Motion-guided Network for Micro-expression Recognition
Posted 猫头丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MMNet: Muscle Motion-guided Network for Micro-expression Recognition相关的知识,希望对你有一定的参考价值。
MMNet: Muscle Motion-guided Network for Micro-expression Recognition
哈喽,大家好呀,继续更!感觉自己的水平还是有限,最近想开始上手做一些事情,但感觉还是有点力不从心,不过这一周开始接触将Transformer应用在计算机视觉领域,觉得有点亲切,让我想到了大三去做实习的时候,做机器翻译时用到Transformer,当时也是愁的不行,实在是太复杂,太难懂了,不过现在看到Transformer却觉得非常亲切,就好像看到大学同学一样。嘿嘿。
话不多说,让我们开始读论文吧!
(悄悄说,因为本人的水平有限,只当是个参考,大家如果有不同的见解,欢迎评论哦!)


这篇文章是目前微表情识别(Micro-expression recognition)的SOTA。作者认为现有的一些模型很容易学习到与微表情识别无关的身份信息。而微表情识别的关键是学习面部肌肉运动的位置和运动模式。
作者提出使用一种双分支结构来处理上述两个关键因素,主分支引入持续注意力模块(CA)通过onset帧和apex帧的差异来学习肌肉运动模式,子分支设计了一个基于VIT的位置校准模块(OC)基于onset帧来生成面部位置嵌入。模型的大致结构如下图所示:
 MMNet的主分支只建模了起始帧和顶点帧之间的差异,这反映了面部的肌肉运动,使模型不受身份信息的影响。
MMNet的主分支只建模了起始帧和顶点帧之间的差异,这反映了面部的肌肉运动,使模型不受身份信息的影响。
 可以看到完整的MMNet模型的两个分支,主分支由4个CA模块构成,子分支由PC模块组成,接下来将分别介绍。
可以看到完整的MMNet模型的两个分支,主分支由4个CA模块构成,子分支由PC模块组成,接下来将分别介绍。
Continuous Attention Block
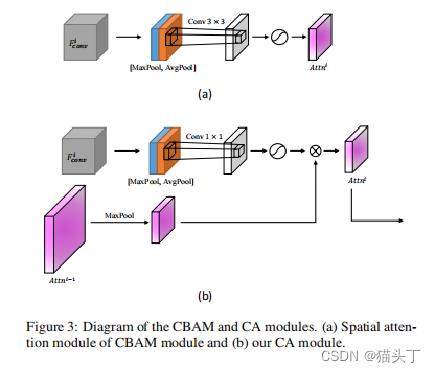 1、CA模块借鉴CBAM的思想,同时使用最大池化(max-pool)和平均池化(average-pool)
1、CA模块借鉴CBAM的思想,同时使用最大池化(max-pool)和平均池化(average-pool)
2、前一层的注意力图作为先验知识来生成当前层的注意力图,并使用较小的卷积核(1*1)来获得更多的局部注意力。
我们可以结合这个详细的图,和公式来更好地理解这个过程。

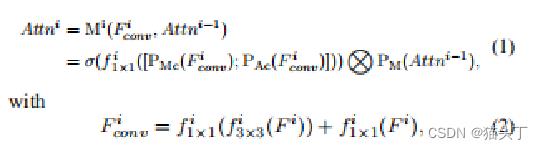 作者说,通过将注意力模块连接起来,可以逐渐稳定地关注到有细微运动的区域,并将注意力图进行了可视化。
作者说,通过将注意力模块连接起来,可以逐渐稳定地关注到有细微运动的区域,并将注意力图进行了可视化。

Position Calibration Module
 由于微表情数据集中不同的人的外观不同,由于瞳孔间距离不同,鼻子大小不同等原因,很难严格对齐所有的面孔。因此,相同的面部区域可能对应于图像的不同像素位置,这使得网络很难准确地了解细微的运动发生在哪里。
由于微表情数据集中不同的人的外观不同,由于瞳孔间距离不同,鼻子大小不同等原因,很难严格对齐所有的面孔。因此,相同的面部区域可能对应于图像的不同像素位置,这使得网络很难准确地了解细微的运动发生在哪里。
由于面部特征的相对位置实在物理上确定的(例如,鼻子通常位于两只眼睛的中间下方),对长距离依赖关系建模可以有效地帮助定位面部不同部位的位置,并生成稳健的位置嵌入。
因为只需要学习突出区域的位置(例如,眼睛、嘴和鼻子),而不是详细的有关受试者身份的纹理信息(例如,皱纹和肤色),因此利用低分辨率起始帧来学习面部位置嵌入。将onset帧缩放到14*14.
结果
接下来作者进行了一些消融实验来证明各个模块的有效性,并对微表情分类结果进行了一些比较。

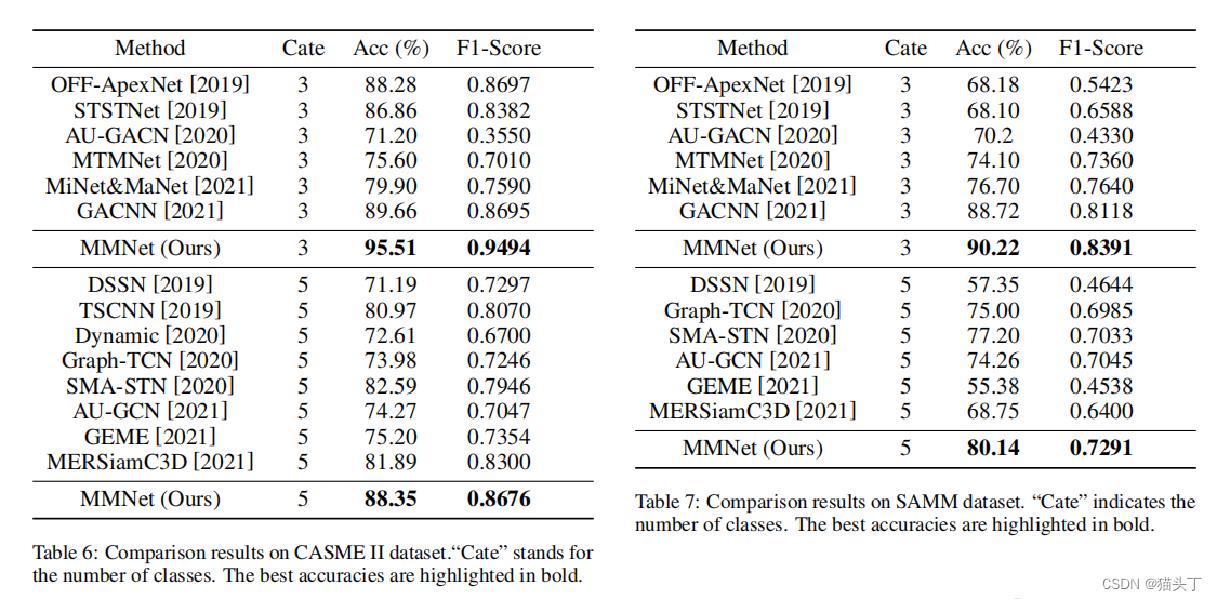
嘿嘿,分享结束!

以上是关于MMNet: Muscle Motion-guided Network for Micro-expression Recognition的主要内容,如果未能解决你的问题,请参考以下文章