大数据ClickHouse进阶:副本与分片
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据ClickHouse进阶:副本与分片相关的知识,希望对你有一定的参考价值。

文章目录
副本与分片
ClickHouse数据存储时支持副本和分片,副本指的就是一份数据可以在不同的节点上存储,这些节点上存储的每份数据相同,数据副本是增加数据存储冗余来防止数据丢失。分片指的是ClickHouse一张表的数据可以横向切分为多份,每份中的数据不相同且存储在不同的节点上,分片的目的主要是实现数据的水平切分,方便多线程和分布式查询数据。
这里以由3台ClickHouse节点组成的ClickHouse集群对应的几张图来描述ClickHouse中的副本与分片,方便大家理解:
- 表temp只有一个分片,1个副本(数据本身可看成1个副本)
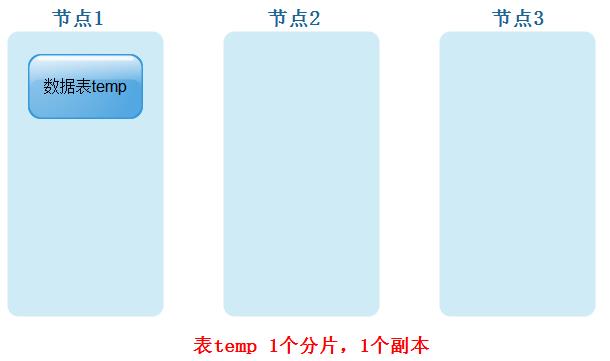
- 表temp只有一个分片,每个分片有1个副本
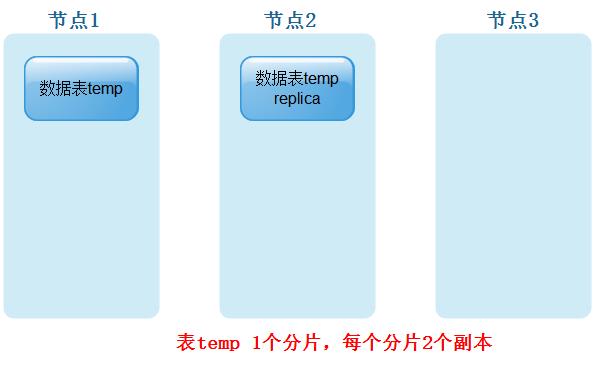
- 表temp有2个分片,每个分片有1个副本

一、数据副本
存储在ClickHouse中的数据想要有副本,创建表时需要在对应的表引擎前面加上“Replicated”前缀组成一种新的变种引擎,并且目前只有MergeTree系列表引擎才支持副本,如下图所示:

下面我们以ReplicatedMergeTree引擎来举例讲解ClickHouse中的数据副本。
创建副本表语法:
Engine = ReplicatedMergeTree('zk_path','replica_name')在上述创建语法中,有zk_path和replica_name两项配置,代表意思如下:
- zk_path:
在zookeeper中创建的数据表的路径,路径名称可以自定义,用户可以自己定义成希望的任何路径。ClickHouse提供了一些约定俗成的配置模板:/ClickHouse/tables/shard/table_name ,其中“/ClickHouse/tables”是约定俗成的路径固定前缀,表示存放数据表的根路径;“shard”表示分片编号,通常使用数值代替,例如:01,02,03,一张数据表可以有多个分片,而每个分片都拥有自己的副本;“table_name”表示数据表的名称,通常与物理表的名字相同。
- replica_name:
定义在zookeeper中创建的副本名称,该名称是区分不同副本实例的唯一标识,一种约定俗成的命名方式是使用所在服务器的域名称。
创建副本表举例,我们在node1节点进入ClickHouse,执行如下建表语句:
Create table person_info(
id UInt32,
name String,
age UInt32,
gender String,
loc String
) engine = ReplicatedMergeTree('/ClickHouse/tables/01/person_info','node1')
partition by loc
order by id;在node2节点进入ClickHouse,执行如下建表语句:
Create table person_info(
id UInt32,
name String,
age UInt32,
gender String,
loc String
) engine = ReplicatedMergeTree('/ClickHouse/tables/01/person_info','node2')
partition by loc
order by id;以上两张表创建完成之后,在zookeeper中会看到创建“/ClickHouse/tables/01/person_info”路径,对此路径下的部分重要目录解释如下:
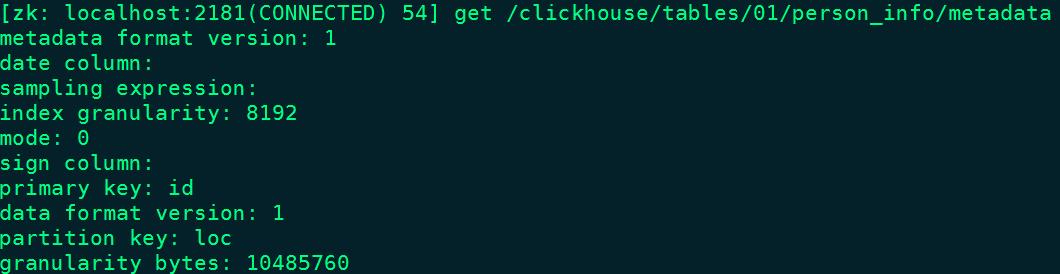
- /metadata:
保存元数据信息,包括主键、分区键、采样表达式。
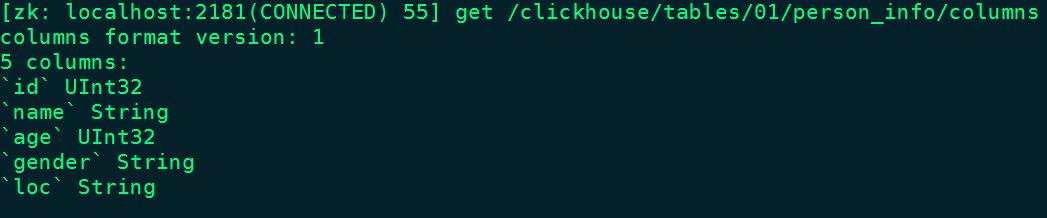
- /columns:
保存列字段信息,包括列名称和数据类型。
- /replicas:
保存副本名称,对应设置参数中的replica_name。


- /leader_election:
用于主副本的选举工作,主副本主要负责merge、Alter delte 、alter update操作。



在node1向表“person_info”中插入以下数据:
insert into person_info values (1,'zs',18,'m','beijing'),(2,'ls',19,'f','shanghai'),(3,'ww',20,'m','beijing'),(4,'ml',21,'m','shanghai')插入数据之后,我们在node1上进行查询:
select * from person_info; 
由于有副本作用,在node2节点上我们同样也可以查询到表person_info中的数据:
select * from person_info;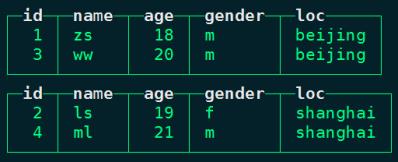
以上在node1节点或者node2节点上表“person_info”中插入数据时,都会通过zookeeper的监听,立即同步到另外节点,可以在node1,node2节点“/var/lib/ClickHouse/data/default/person_info”路径下发现相同的一份数据。


二、数据分片
通过数据副本我们可以降低数据丢失的风险,到现在为止每个副本上都有表全量数据,当业务量十分庞大的场景下,依靠副本并不能解决单表的新能瓶颈,我们可以对一张表水平分为多个分片,这些分片分别存储在不同的ClickHouse集群节点中。例如一个ClickHouse集群有3台节点,我们在创建表temp时可以分成3个分片,这3个分片内的数据不相同,分别存储在不同的ClickHouse节点上,当然为了保证数据的高可用也可以给每个分片设置副本。
特别注意:在ClickHouse中,每个节点只能配置在一个<shard>标签下的<replica>中,不能与其他的<shard>标签下的<replica>节点名称相同。例如:配置一个ClickHouse集群拥有3个分片,且每个分片有2个副本,那么metrika.xml配置文件配置如下:
<remote_servers>
<ClickHouse_cluster_3shards_2replicas>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node1</host>
<port>9000</port>
</replica>
<replica>
<host>node2</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node3</host>
<port>9000</port>
</replica>
<replica>
<host>node4</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node5</host>
<port>9000</port>
</replica>
<replica>
<host>node6</host>
<port>9000</port>
</replica>
</shard>
</ClickHouse_cluster_3shards_1replicas>
</remote_servers>以上完成配置拥有3个分片,2个副本的ClickHouse集群需要6台节点。
在介绍副本时,为了创建多张表我们需要分别登录到不同的ClickHouse节点,在各自的ClickHouse节点上执行create建表命令,创建的表名称都是一样的,这是因为Create、Drop、Rename、Alter等DDL语句并不支持分布式执行,而在分布式的ClickHouse集群中我们可以使用新的语法实现分布式DDL,其语法格式为:
CREATE/DROP/RENAME/ALTER TABLE xxx ON CLUSTER cluste_name其中以上“xxx”代表创建的表名称,“cluster_name”对应前面集群配置文件metrika.xml中的集群名称,根据配置文件,ClickHouse会根据集群的配置信息,找到每个节点执行DDL语句,“xxx”表也会在各个节点上被创建。
创建具有3分片和1副本的表“person_score”,建表语句如下:
Create table person_score on cluster ClickHouse_cluster_3shards_1replicas (
id UInt32,
name String,
age UInt32,
gender String,
score Decimal(9,2)
)engine = ReplicatedMergeTree('/ClickHouse/tables/shard/person_score','replica')
order by id;注意:
- 以上“ClickHouse_cluster_3shards_1replicas”是在“/etc/ClickHouse-server/config.d/metrika.xml”配置文件中配置的ClickHouse集群的名称
- shard与replica两个变量是在metrika.xml中<macros>宏变量标签中配置的对应值,这样当在ClickHouse集群中的某台节点执行以上建表语句时,ClickHouse会自动在各个节点创建此表,这里每台ClickHouse节点上的表person_socre是本地表。
可以在zookeeper中找到查看对应的分片信息:
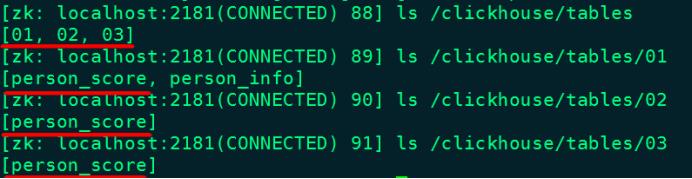
向表person_score中插入数据,在哪台ClickHouse节点向本地表person_score中插入数据,那么数据就存入当前本地表对应的分片中。
#在node1向node1本地表person_score中插入以下数据:
insert into person_score values (1,'zs',18,'m',100),(2,'ls',19,'f',200);
#在node1上查询本地表 person_score数据:
node1 :) select * from person_score; 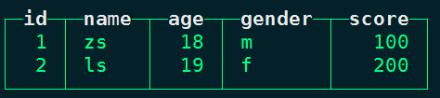
#在node2向node2本地表person_score中插入以下数据:
insert into person_score values (3,'ww',20,'m',300),(4,'ml',21,'m',400);
#在node2上查询本地表 person_score数据:
node2 :) select * from person_score;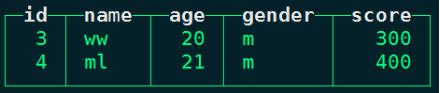
#在node3向node3本地表person_score中插入以下数据:
insert into person_score values (5,'ml',22,'f',500),(6,'tq',23,'f',600);
#在node3上查询本地表 person_score数据:
node3 :) select * from person_score;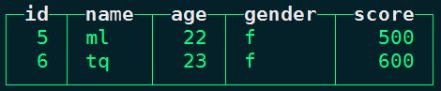
以上我们创建的person_score表在ClickHouse集群节点node1、node2、node3上都是本地表,插入数据时插入到了对应节点的分片上,查询时也只能查询对应节点上的分片数据,如果我们想要通过一张表将各个ClickHouse节点上的person_score表进行查询,这时就需要使用Distribute表引擎,所以在实际工作中ClickHouse的数据分片需要结合Distriubute表引擎一同使用。
Distriubute表引擎将会在下一篇介绍,敬请期待
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于大数据ClickHouse进阶:副本与分片的主要内容,如果未能解决你的问题,请参考以下文章
clickhouseclickhouse 副本与分片 分片详解
大数据ClickHouse进阶:Distributed引擎深入了解