ClickHouse的介绍(基本sql操作,以及数据库引擎表引擎分片副本explain优化物化视图等)
Posted 迷雾总会解
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse的介绍(基本sql操作,以及数据库引擎表引擎分片副本explain优化物化视图等)相关的知识,希望对你有一定的参考价值。
介绍和安装
ClickHouse是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),使用C++语言编写,主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。
- OLAP(On-Line Analytical Processing)翻译为联机分析处理,专注于分析处理,从对数据库操作来看,OLAP是对数据的查询;
- OLTP(on-line transaction processing)翻译为联机事务处理,专注于事务处理,从对数据库操作来看,OLTP主要是对数据的增删改。
特点
-
列式存储
以下面的表为例:

1)采用行式存储时,数据在磁盘上的组织结构为:
好处是想查某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
2)采用列式存储时,数据在磁盘上的组织结构为:
这时想查所有人的年龄只需把年龄那一列拿出来就可以了。
3)列式存储的好处:
- 对于列的聚合、计数、求和等统计操作原因优于行式存储;
- 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重;
- 由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于cache也有了更大的发挥空间
-
DBMS的功能:几乎覆盖了标准SQL的大部分语法,包括DDL和DML,以及配套的各种函数,用户管理及权限管理,数据的备份与恢复;
-
多样化引擎:ClickHouse和mysql类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。目前包括合并树、日志、接口和其他四大类20多种引擎;
-
高吞吐写入能力:ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度
-
数据分区与线程级并行
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity(索引粒度),然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时
所以,ClickHouse即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多cpu,就不利于同时并发多条查询。所以对于高qps的查询业务,ClickHouse并不是强项
安装
准备工作
-
确定防火墙处于关闭状态
-
CentOS取消打开文件数限制
sudo vim /etc/security/limits.conf在末尾加入:
* soft nofile 65536 * hard nofile 65536 * soft nproc 131072 * hard nproc 131072- 第一列是限制的用户和用户组
- soft软限制,hard硬限制
- nofile打开文件数,nproc用户进程数
sudo vim /etc/security/limits.d/20-nproc.conf在末尾加入:
* soft nofile 65536 * hard nofile 65536 * soft nproc 131072 * hard nproc 131072退出当前用户,重启登录,
ulimit -a查看打开文件数和用户进程数是否更改[root@aliyun ~]# ulimit -a core file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks, -f) unlimited pending signals (-i) 7284 max locked memory (kbytes, -l) 64 max memory size (kbytes, -m) unlimited open files (-n) 65536 pipe size (512 bytes, -p) 8 POSIX message queues (bytes, -q) 819200 real-time priority (-r) 0 stack size (kbytes, -s) 8192 cpu time (seconds, -t) unlimited max user processes (-u) 131072 virtual memory (kbytes, -v) unlimited file locks (-x) unlimited -
安装依赖
sudo yum install -y libtool sudo yum install -y *unixODBC* -
CentOS取消SELINUX(不知道为什么我修改后,就没网了)
vim /etc/selinux/config修改为:
SELINUX=disabled修改完重启服务器
单机安装
-
下载安装包
👉 安装包下载
需要以下四个rpm包:
clickhouse-client-21.7.3.14-2.noarch.rpm clickhouse-common-static-21.7.3.14-2.x86_64.rpm clickhouse-common-static-dbg-21.7.3.14-2.x86_64.rpm clickhouse-server-21.7.3.14-2.noarch.rpmmac下要下载arm的,注意!!!
也可以通过wget下载:
wget https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/clickhouse-client-21.7.3.14-2.noarch.rpm wget https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/clickhouse-common-static-21.7.3.14-2.x86_64.rpm wget https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/clickhouse-common-static-dbg-21.7.3.14-2.x86_64.rpm wget https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/clickhouse-server-21.7.3.14-2.noarch.rpm安装这4个rpm包:
sudo rpm -ivh *.rpm -
修改配置文件
cd /etc/clickhouse-server/ sudo chmod 777 config.xml sudo vim config.xml把
<listen_host>0.0.0.0</listen_host>的注释打开,这样的话才能让ClickHouse被除本机之外的服务器访问。这个配置文件中,ClickHouse一些默认路径配置:
- 数据文件路径:
<path>/var/lib/clickhouse/</path> - 日志文件路径:
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
- 数据文件路径:
-
启动Server
sudo systemctl start clickhouse-server 或者 sudo clickhouse start查看启动状态:
sudo systemctl status clickhouse-server 或者 sudo clickhouse status -
关闭开启自启
sudo systemctl disable clickhouse-server -
使用client连接server
clickhouse-client -m
在连接的过程中出现了两个错误:
-
错误一:
Code: 210. DB::NetException: Connection refused (localhost:9000). (NETWORK_ERROR)如果在配置文件中有
<listen_host>::</listen_host>,就改成<listen_host>0.0.0.0</listen_host>,因为::是IPv6的通配符,我部署clickhouse的机器不支持ipv6。 -
错误二:
Code: 516. DB::Exception: Received from localhost:9000. DB::Exception: default: Authentication failed: password is incorrect or there is no user with such name. (AUTHENTICATION_FAILED)在命令中带上
--password:clickhouse-client -m --password
数据类型
整形
固定长度的整型,包括有符号整型或无符号整型
整型范围 ( 2 n − 1 ∼ 2 n − 1 − 1 ) (2^n-1 \\ \\sim \\ 2^n-1-1) (2n−1 ∼ 2n−1−1):Int8、Int16、Int32、Int64
无符号整型范围 ( 0 ∼ 2 n − 1 ) (0 \\ \\sim \\ 2^n-1) (0 ∼ 2n−1):UInt8、UInt16、UInt32、UInt64
浮点数
Float32、Float64
浮点数计算精度缺失问题:
select 1.0-0.9
┌──────minus(1., 0.9)─┐
│ 0.09999999999999998 │
└─────────────────────┘
布尔型
没有单独的类型来存储布尔值。可以使用UInt8类型,取值限制为0或1。
Decimal型
Decimal32(s)相当于Decimal(9-s,s)
Decimal64(s)相当于Decimal(18-s,s)
Decimal128(s)相当于Decimal(38-s,s)
字符串
- String:字符串可以任意长度的。它可以包含任意的字节集,包含空字节;
- FixedString(N):固定长度N的字符串,N必须是严格的正自然数。当服务端读取长度小于N的字符串时候,通过在字符串末尾添加空字节来达到N字节长度。当服务端读取长度大于N的字符串时候,将返回错误消息。
枚举类型
包括Enum8和Enum16类型。Enum保存**’string’=integer**的对应关系
- Enum8用’string’=Int8来描述
- Enum16用’string’=Int16来描述
创建一个带有一个枚举Enum8(‘hello’ = 1, ‘world’ = 2)类型的列:
create table t_enum(
x Enum8('hello' = 1,'world' = 2)
)engine = TinyLog;
这个x列只能存储类型定义中列出的值:‘hello’或’world’:
inser tinto t_enum values ('hello'),('hello'),('world'),('world');
如果尝试保存任何其他值,ClickHouse抛出异常:
insert into t_enum values('a');
如果需要看到对应行的数值,则必须将Enum值转换为整数类型:
select cast(x,'Int8') from t_enum;
时间类型
目前ClickHouse有三种时间类型:
- Date接受年-月-日的字符串,比如:2019-12-16;
- Datetime接受年-月-日 时:分:秒的字符串,比如2019-12-16 20:50:10;
- Datetime64 接受年-月-日 时:分:秒.亚秒的字符串,比如2019-12-16 20:50:10.66。
日期类型用两个字节存储,表示从1970-01-01到当前的日期值
数组
Array(T):由T类型元素组成的数组
T可以是任意类型,包含数组类型。但不推荐使用多维数组,ClickHouse对多维数组的支持有限。例如,不能在MergeTree表中存储多维数组
创建数组方式:
-
使用array函数
select array(1, 2) as x, toTypeName(x);
-
使用方括号
select [1, 2] as x, toTypeName(x);
数据库引擎
数据库引擎和表引擎
- 数据库引擎默认是Ordinary,在这种数据库下面的表可以是任意类型引擎。
- 生产环境中常用的表引擎是MergeTree系列,也是官方主推的引擎。
- MergeTree是基础引擎,有主键索引、数据分区、数据副本、数据采样、删除和修改等功能,
- ReplacingMergeTree有了去重功能,
- SummingMergeTree有了汇总求和功能,
- AggregatingMergeTree有聚合功能,
- CollapsingMergeTree有折叠删除功能,
- VersionedCollapsingMergeTree有版本折叠功能,
- GraphiteMergeTree有压缩汇总功能。
- 在这些的基础上还可以叠加Replicated和Distributed。Integration系列用于集成外部的数据源,常用的有HADOOP,MySQL。
MaterializeMySQL
基本概述
MySQL 的用户群体很大,为了能够增强数据的实时性,很多解决方案会利用 binlog 将数据写入到 ClickHouse。为了能够监听 binlog 事件,我们需要用到类似 canal 这样的第三方中间件,这无疑增加了系统的复杂度。
ClickHouse 20.8.2.3 版本新增加了 MaterializeMySQL 的 database 引擎,该 database 能映 射 到 MySQL 中 的 某 个 database , 并 自 动 在 ClickHouse 中 创 建 对 应 的ReplacingMergeTree。ClickHouse 服务做为 MySQL 副本,读取 Binlog 并执行 DDL 和 DML 请求,实现了基于 MySQL Binlog 机制的业务数据库实时同步功能。
特点
-
MaterializeMySQL 同时支持全量和增量同步,在 database 创建之初会全量同步MySQL 中的表和数据,之后则会通过 binlog 进行增量同步;
-
MaterializeMySQL database 为其所创建的每张 ReplacingMergeTree 自动增加了_sign 和 _version 字段。
其中,_version 用作 ReplacingMergeTree 的 ver 版本参数,每当监听到 insert、update 和 delete 事件时,在 databse 内全局自增。而 _sign 则用于标记是否被删除,取值 1 或者 -1。
-
目前 MaterializeMySQL 支持如下几种 binlog 事件:
- MYSQL_WRITE_ROWS_EVENT:_sign = 1,_version ++;
- MYSQL_DELETE_ROWS_EVENT:_sign = -1,_version ++;
- MYSQL_UPDATE_ROWS_EVENT:新数据 _sign = 1;
- MYSQL_QUERY_EVENT: 支持 CREATE TABLE 、DROP TABLE 、RENAME TABLE 等。
使用细则
-
DDL 查询
MySQL DDL 查询被转换成相应的 ClickHouse DDL 查询(ALTER, CREATE, DROP, RENAME)。如果 ClickHouse 不能解析某些 DDL 查询,该查询将被忽略。
-
数据复制
MaterializeMySQL 不支持直接插入、删除和更新查询,而是将 DDL 语句进行相应转换:
- MySQL INSERT 查询被转换为 INSERT with _sign=1;
- MySQL DELETE 查询被转换为 INSERT with _sign=-1;
- MySQL UPDATE 查询被转换成 INSERT with _sign=1 和 INSERT with _sign=-1。
-
SELECT 查询
- 如果在 SELECT 查询中没有指定_version,则使用 FINAL 修饰符,返回_version 的最大值对应的数据,即最新版本的数据;
- 如果在 SELECT 查询中没有指定_sign,则默认使用 WHERE _sign=1,即返回未删除状态(_sign=1)的数据。
-
索引转换
- ClickHouse 数据库表会自动将 MySQL 主键和索引子句转换为ORDER BY 元组;
- ClickHouse 只有一个物理顺序,由 ORDER BY 子句决定。如果需要创建新的物理顺序,请使用物化视图。
案例实操
MySQL 开启 binlog 和 GTID 模式
确保 MySQL 开启了 binlog 功能,且格式为 ROW 打开/etc/my.cnf,在[mysqld]下添加:
server-id=1
log-bin=mysql-bin
binlog_format=ROW
开启 GTID 模式,如果如果 clickhouse 使用的是 20.8 prestable 之后发布的版本,那么 MySQL 还需要配置开启 GTID 模式, 这种方式在 mysql 主从模式下可以确保数据同步的一致性(主从切换时)。
gtid-mode=on
enforce-gtid-consistency=1 # 设置为主从强一致性
log-slave-updates=1 # 记录日志
GTID 是 MySQL 复制增强版,从 MySQL 5.6 版本开始支持,目前已经是 MySQL 主流复制模式。它为每个 event 分配一个全局唯一 ID 和序号,我们可以不用关心 MySQL 集群主从拓扑结构,直接告知 MySQL 这个 GTID 即可。
重启 MySQL:
sudo systemctl restart mysqld
准备 MySQL 表和数据
CREATE DATABASE testck;
CREATE TABLE `testck`.`t_organization` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`code` int NOT NULL,
`name` text DEFAULT NULL,
`updatetime` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY (`code`)
) ENGINE=InnoDB;
INSERT INTO testck.t_organization (code,name,updatetime) VALUES(1000,'Realinsight',NOW());
INSERT INTO testck.t_organization (code,name,updatetime) VALUES(1001, 'Realindex',NOW());
INSERT INTO testck.t_organization (code,name,updatetime) VALUES(1002,'EDT',NOW());
CREATE TABLE `testck`.`t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`code` int,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
INSERT INTO testck.t_user (code) VALUES(1);
开启 ClickHouse 物化引擎
set allow_experimental_database_materialize_mysql=1;
创建复制管道
ClickHouse 中创建MaterializeMySQL 数据库
CREATE DATABASE test_binlog ENGINE = MaterializeMySQL('hadoop1:3306','testck','root','000000');
其中 4 个参数分别是 MySQL 地址、databse、username 和 password。
查看 ClickHouse 的数据:
use test_binlog;
show tables;
select * from t_organization;
select * from t_user;
修改数据
在 MySQL 中修改数据:
update t_organization set name = CONCAT(name,'-v1') where id = 1
查看 clickhouse 日志可以看到 binlog 监听事件,查询clickhouse:
select * from t_organization;
删除数据
MySQL 删除数据:
DELETE FROM t_organization where id = 2;
ClicKHouse,日志有 DeleteRows 的 binlog 监听事件,查看数据:
select * from t_organization;
在刚才的查询中增加 _sign 和 _version 虚拟字段:
select *,_sign,_version from t_organization order by _sign desc,_version desc;
在查询时,对于已经被删除的数据,_sign=-1,ClickHouse 会自动重写 SQL,将 _sign =1 的数据过滤掉;
对于修改的数据,则自动重写 SQL,为其增加 FINAL 修饰符。
select * from t_organization
等同于
select * from t_organization final where _sign = 1
删除表
在 mysql 执行删除表:
drop table t_user;
此时在 clickhouse 处会同步删除对应表,如果查询会报错:
show tables;
select * from t_user;
DB::Exception: Table scene_mms.scene doesn't exist..
mysql 新建表,clickhouse 可以查询到:
CREATE TABLE `testck`.`t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`code` int,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
INSERT INTO testck.t_user (code) VALUES(1);
#ClickHouse 查询
show tables;
select * from t_user;
表引擎
表引擎的使用
表引擎决定了如何存储表的数据。包括:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据;
- 支持哪些查询以及如何支持;
- 并发数据访问;
- 索引的使用(如果存在);
- 是否可以执行多线程请求;
- 数据复制参数;
- 表引擎的使用方式就是必须显式在创建表时定义该表使用的引擎,以及引擎使用的相关参数。
引擎的名称大小写敏感。
TinyLog
以列文件的形式保存在磁盘上,不支持索引,没有并发控制。一般保存少量数据的小表,生产环境上作用有限。可以用于平时练习测试用。
Memory
内存引擎:数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过10G/s)。一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概1亿行)的场景
MergeTree(🌟)
ClickHouse中最强大的表引擎当属MergeTree(合并树)引擎及该系列(MergeTree)中的其他引擎,支持索引和分区,地位可以相当于innodb之于Mysql。
基本sql
(1)建表语句:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
- PARTITION BY:分区键,用于指定数据以何种标准进行分区。分区键可以是单个列字段、元组形式的多个列字段、列表达式。如果不声明分区键,则ClickHouse会生成一个名为all的分区。合理使用数据分区,可以有效减少查询时数据文件的扫描范围。
- ORDER BY 决定了每个分区中数据的排序规则;主键必须是order by字段的前缀字段;在ReplactingmergeTree中,order by相同的被认为是重复的数据;在SummingMergeTree中作为聚合的维度列;
- PRIMARY KEY 决定了一级索引(primary.idx),默认情况下,主键与排序键(ORDER BY)相同,所以通常使用ORDER BY代为指定主键。一般情况下,在单个数据片段内,数据与一级索引以相同的规则升序排序。与其他数据库不同,MergeTree主键允许存在重复数据;
- SAMPLE BY:抽样表达式,用于声明数据以何种标准进行采样。抽样表达式需要配合SAMPLE子查询使用;
- SETTINGS:index_granularity:索引粒度,默认值8192。也就是说,默认情况下每隔8192行数据才生成一条索引;
- SETTINGS:index_granularity_bytes:在19.11版本之前,ClickHouse只支持固定大小的索引间隔(index_granularity)。在新版本中增加了自适应间隔大小的特性,即根据每一批次写入数据的体量大小,动态划分间隔大小。而数据的体量大小,由index_granularity_bytes参数控制,默认10M;
- SETTINGS:enable_mixed_granularity_parts:设置是否开启自适应索引间隔的功能,默认开启。
例子:
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine = MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
(2)插入数据:
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');
查询数据:
- 根据日期分区,2020-06-01、2020-06-02共两个分区;
- 主键可重复;
- 分区内根据id和sku_id排序。
分区(可选)
分区的目的主要是降低扫描的范围,优化查询速度,如果不填,只会使用一个分区。分区后,面对涉及跨分区的查询统计,ClickHouse会以分区为单位并行处理。
文件结构
在前面安装时,就介绍过,配置文件中表明了默认的数据存储位置是/var/lib/clickhouse,因此结构如下:
里面有两个文件夹很重要:metadata和data。
(1)metadata保存了数据库的元数据,每个库的每个表都会记录表结构信息:
ATTACH TABLE _ UUID 'c51df0c7-bae7-4abb-b8a8-d2a5523cdb26'
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` DateTime
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
SETTINGS index_granularity = 8192
基本上和建表语句差不多。
(2)data保存了每个库的表数据:
20200601_1_1_0、20200602_2_2_0共两个分区目录。
分区目录命名格式:PartitionId_MinBlockNum_MaxBlockNum_Level,分表代表分区值、最小分区块编号、最大分区块编号、合并层级。
而每一个分区目录下都包含如下文件:
-rw-r-----. 1 clickhouse root 259 8月 29 03:02 checksums.txt
-rw-r-----. 1 clickhouse root 118 8月 29 03:02 columns.txt
-rw-r-----. 1 clickhouse root 1 8月 29 03:02 count.txt
-rw-r-----. 1 clickhouse root 189 8月 29 03:02 data.bin
-rw-r-----. 1 clickhouse root 144 8月 29 03:02 data.mrk3
-rw-r-----. 1 clickhouse root 10 8月 29 03:02 default_compression_codec.txt
-rw-r-----. 1 clickhouse root 8 8月 29 03:02 minmax_create_time.idx
-rw-r-----. 1 clickhouse root 4 8月 29 03:02 partition.dat
-rw-r-----. 1 clickhouse root 8 8月 29 03:02 primary.idx
- data.bin:数据文件;(其实每一个列都会有一个bin文件)
- data.mrk3:标记文件,标记文件在idx索引文件和bin数据文件之间起到了桥梁作用;(每一个列都会有一个mrk文件)
- count.txt:有几条数据;
- default_compression_codec.txt:默认压缩格式;
- columns.txt:列的信息;
- primary.idx:主键索引文件;
- partition.dat与minmax_[Column].idx:如果使用了分区键,则会额外生成这2个文件,均使用二进制存储。partition.dat保存当前分区下分区表达式最终生成的值;minmax索引用于记录当前分区下分区字段对应原始数据的最小值和最大值。以t_order_mt的20200601分区为例,partition.dat中的值为20200601,minmax索引中保存的值为2020-06-01 12:00:002020-06-01 13:00:00
分区命名
PartitionId:数据分区规则由分区ID决定,分区ID由partition by分区键决定。根据分区键字段类型,ID生成规则可分为:
七十六ClickHouse的表引擎以及SQL语法
上一篇文章我们介绍了一下ClickHouse的安装,这一篇我们主要来看一下它的表引擎已经SQL语法。关注专栏《破茧成蝶——大数据篇》,查看更多相关的内容~
目录
一、ClickHouse的数据类型
在介绍表引擎和SQL语法之前,我们先来看一下它的数据类型。常用的数据类型如下所示:
1、整型。固定长度的整型,包括有符号整型(-2n-1~2n-1-1)和无符号整型(0~2n-1)。
2、浮点型。建议尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型进行计算时可能引起四舍五入的误差。与标准SQL相比,ClickHouse 支持以下类别的浮点数:Inf-正无穷、-Inf-负无穷、NaN-非数字。
3、布尔类型。没有单独的类型来存储布尔值。可以使用UInt8类型,取值限制为0或1。
4、字符串。(1)String:字符串可以任意长度的。它可以包含任意的字节集,包含空字节。(2)FixedString(N):固定长度N的字符串,N必须是严格的正自然数。当服务端读取长度小于N的字符串时候,通过在字符串末尾添加空字节来达到N字节长度。当服务端读取长度大于N的字符串时候,将返回错误消息。与String相比,极少会使用FixedString,因为使用起来不是很方便。
5、枚举类型。包括Enum8和Enum16类型,Enum保存'string'=integer的对应关系,Enum8用'String'=Int8对描述,Enum16用'String'=Int16对描述。
6、数组。Array(T):由T类型元素组成的数组。T可以是任意类型,包含数组类型。但不推荐使用多维数组,ClickHouse对多维数组的支持有限。
7、元组。Tuple(T1, T2, ...):元组,其中每个元素都有单独的类型。
8、Date类型。日期类型,用两个字节存储,表示从1970-01-01 (无符号) 到当前的日期值。
此处仅列举出8中数据类型,更多数据类型可以参考官方文档。
二、ClickHouse的表引擎
表引擎(即表的类型)决定了:1、数据的存储方式和位置,写到哪里以及从哪里读取数据。2、支持哪些查询以及如何支持。3、并发数据访问。4、索引的使用(如果存在)。5、是否可以执行多线程请求。6、数据复制参数。
ClickHouse的表引擎有很多,下面只介绍其中几种,对其他引擎有兴趣的可以去查阅官方文档。
2.1 TinyLog
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中,写入时,数据将附加到文件末尾。该引擎没有并发控制,如果同时从表中读取和写入数据,则读取操作将抛出异常;如果同时写入多个查询中的表,则数据将被破坏。这种表引擎的典型用法是write-once:首先只写入一次数据,然后根据需要多次读取。此引擎适用于相对较小的表(建议最多1,000,000行)。如果有许多小表,则使用此表引擎是适合的,因为它比需要打开的文件更少。当拥有大量小表时,可能会导致性能低下。同时,它不支持索引。
下面我们来看一个简单的案例:创建一个TinyLog的表并插入数据。
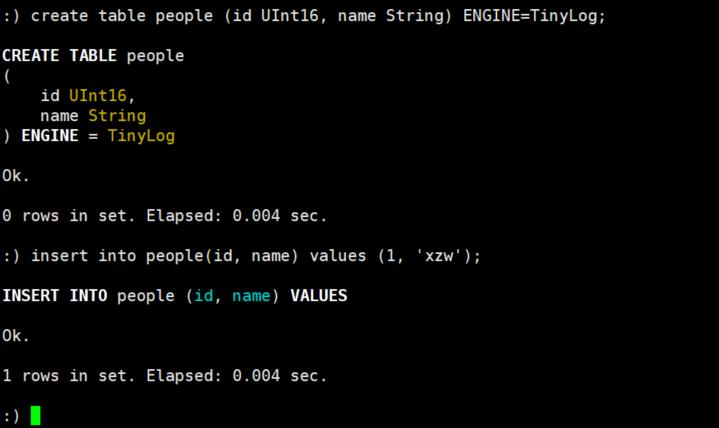
我们可以到保存数据的目录下进行查看:

id.bin和name.bin是压缩过的对应的列的数据,sizes.json中记录了每个*.bin文件的大小:

2.2 Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过10G/s)。
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概1亿行)的场景。
2.3 Merge
Merge引擎(不要跟MergeTree引擎混淆)本身不存储数据,但可用于同时从任意多个其他的表中读取数据。读是自动并行的,不支持写入。读取时,那些被真正读取到数据的表的索引(如果有的话)会被使用。
Merge引擎的参数:一个数据库名和一个用于匹配表名的正则表达式。
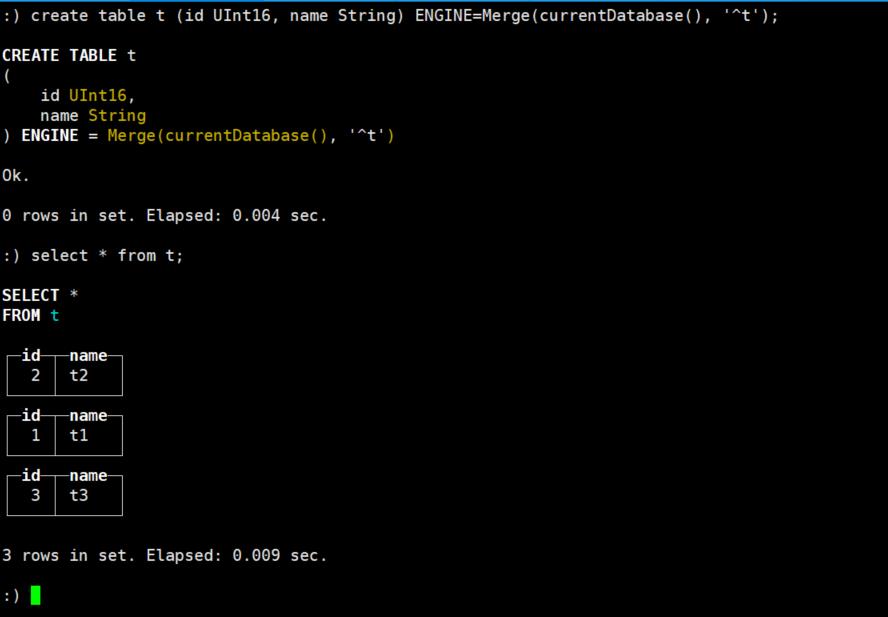
下面我们来看一个简单的案例:我们先建三个表,然后使用Merge引擎将其连接起来。
1、首先穿件三张表并插入数据
create table t1 (id UInt16, name String) ENGINE=TinyLog;
create table t2 (id UInt16, name String) ENGINE=TinyLog;
create table t3 (id UInt16, name String) ENGINE=TinyLog;
insert into t1(id, name) values (1, 't1');
insert into t2(id, name) values (2, 't2');
insert into t3(id, name) values (3, 't3');2、创建Merge引擎表并查询
2.4 MergeTree
ClickHouse中最强大的表引擎当属MergeTree(合并树)引擎及该系列(*MergeTree)中的其他引擎。MergeTree引擎系列的基本理念如下。当你有巨量数据要插入到表中,你要高效地一批批写入数据片段,并希望这些数据片段在后台按照一定规则合并。相比在插入时不断修改(重写)数据进存储,这种策略会高效很多。其语法格式如下:
ENGINE [=] MergeTree(date-column [, sampling_expression], (primary, key), index_granularity)参数释义:
1、date-column:类型为Date的列名。ClickHouse会自动依据这个列按月创建分区,分区名格式为 "YYYYMM"。
2、sampling_expression:采样表达式。
3、(primary, key):主键,类型为Tuple()。
4、index_granularity:索引粒度,即索引中相邻”标记”间的数据行数。设为8192可以适用大部分场景。
我们通过一个简单的案例来看一下:
1、首先新建people表并向表中插入几条数据,如下:
create table people (date Date, id UInt8, name String) ENGINE=MergeTree(date, (id, name), 8192);
insert into people values ('2021-05-01', 1, 'xzw');
insert into people values ('2021-06-01', 2, 'fq');
insert into people values ('2021-05-03', 3, 'yxy');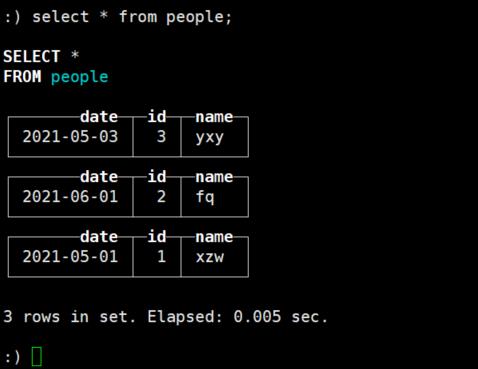
2、我们在对应的数据目录下可以看到如下内容:

其中,*.bin是按列保存数据的文件,*.mrk保存块偏移量,primary.idx保存主键索引。
2.5 ReplacingMergeTree
这个引擎是在MergeTree的基础上,添加了“处理重复数据”的功能,该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。因此,ReplacingMergeTree适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。其语法格式如下:
ENGINE [=] ReplacingMergeTree(date-column [, sampling_expression], (primary, key), index_granularity, [ver])可以看出他比MergeTree只多了一个ver,这个ver指代版本列,他和时间一起配置,区分哪条数据是最新的。
2.6 SummingMergeTree
该引擎继承自MergeTree。区别在于:当合并SummingMergeTree表的数据片段时,ClickHouse会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度,对于不可加的列,会取一个最先出现的值。其语法格式如下:
ENGINE [=] SummingMergeTree(date-column [, sampling_expression], (primary, key), index_granularity, [columns])其中,columns是指包含将要被汇总的列的列名的元组。
2.7 Distributed
分布式引擎,本身不存储数据, 但可以在多个服务器上进行分布式查询。 读是自动并行的。读取时,远程服务器表的索引(如果有的话)会被使用。其语法格式如下:
Distributed(cluster_name, database, table [, sharding_key])其中,cluster_name是指服务器配置文件中的集群名,在/etc/metrika.xml中配置的。sharding_key是指数据分片键。
三、ClickHouse的SQL语法
3.1 CREATE
1、CREATE DATABASE
CREATE DATABASE [IF NOT EXISTS] db_name2、CREATE TABLE
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = engine
3.2 INSERT INTO
INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...3.3 ALTER
ALTER只支持MergeTree系列,Merge和Distributed引擎的表,基本语法如下所示:
ALTER TABLE [db].name [ON CLUSTER cluster] ADD|DROP|MODIFY COLUMN ...3.4 查看表结构
DESCRIBE TABLE3.5 CHECK TABLE
检查表中的数据是否损坏,他会返回两种结果:0表示数据已损坏;1表示数据完整。该命令只支持Log、TinyLog和StripeLog引擎。
以上就是本文的所有内容,比较简单。你们在此过程中遇到了什么问题,欢迎留言,让我看看你们都遇到了哪些问题~
以上是关于ClickHouse的介绍(基本sql操作,以及数据库引擎表引擎分片副本explain优化物化视图等)的主要内容,如果未能解决你的问题,请参考以下文章