PySpark数据分析基础:pyspark.mllib.regression机器学习回归核心类详解+代码详解
Posted fanstuck
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PySpark数据分析基础:pyspark.mllib.regression机器学习回归核心类详解+代码详解相关的知识,希望对你有一定的参考价值。
目录
二、RidgeRegressionWithSGD随机梯度下降岭回归
前言
这段时间PySpark数据分析基础系列文章将持续讲述Pyspark.MLlib这一大块核心内容,更贴近我们的大数据分布式计算结合数据分析。这一部分内容是十分重要且比较难懂不易编程的部分,文章紧接此系列的上篇文章内容:PySpark数据分析基础:pyspark.mllib.regression机器学习回归核心类详解(一)+代码详解
上篇内容我们讲述了一些属于机器学习最基础的内容和相关原理,内容也由浅入深。接下来我们将重点了解每个回归的函数操作以及实现,回归的数学原理和实现方法大家可以订阅我的数学建模专栏详细了解每个回归的原理,这里仅作运用。
若将来想要从事数据挖掘和大数据分析的相关职业,不妨可以关注博主和订阅博主的一些专栏,我将承诺每篇文章将用心纂写长期维护,尽可能输出毕生所学结合如今先有案例项目和技术将每个知识点都讲明白清楚。
希望读者看完能够在评论区提出错误或者看法,博主会长期维护博客做及时更新。
一、RidgeRegressionModel岭回归
岭回归算是回归算法中最经典的算法之一了,原理不在此作介绍,以后会单独开篇文章专门写岭回归算法原理和运用,这里只作运用。
函数语法:
RidgeRegressionModel(weights: pyspark.mllib.linalg.Vector, intercept: float)参数说明:
- weight:每个特征计算的权重。
- intercept:模型的截距。
方法
该函数的方法和LinearRegressionWithSGD的方法是一样的,也有三个方法,分别是:
- load(sc, path):登陆一个RidgeRegressionModel模型。
- predict(x):预测给定向量或包含自变量值的向量RDD的因变量值。
- save(x):保存一个RidgeRegressionModel模型。
该示例缺少train。
二、RidgeRegressionWithSGD随机梯度下降岭回归
使用随机梯度下降训练具有L2正则化的岭回归模型。自版本2.0.0以来已弃用:使用pyspark.ml.regression且elasticNetParam=0.0的线性回归。对于使用GD的RidgeRegression,默认regParam为0.01,而对于线性回归,则为0.0。
以及tarin方法:
classmethod train(data: pyspark.rdd.RDD[pyspark.mllib.regression.LabeledPoint],
iterations: int = 100,
step: float = 1.0,
regParam: float = 0.01,
miniBatchFraction: float = 1.0,
initialWeights: Optional[VectorLike] = None,
intercept: bool = False,
validateData: bool = True,
convergenceTol: float = 0.001)
→ pyspark.mllib.regression.RidgeRegressionModel参数说明:
- data:接收类型为Pyspark.RDD。指定训练用到的数据集,可以是LabeledPoint的RDD。
- iterations:接收类型为int,指定迭代次数,默认为100。
- step:接收类型为float,SGD中使用的阶跃参数,默认为1.0。
- regParam:接受类型为float,正则化参数。默认为0.01
- miniBatchFraction:接收类型为float,用于每次SGD迭代的数据部分,默认为1.0.
- initialWeights:接收类型为pyspark.mllib.linalg.Vector,指定初始权重。
- regType:接收类型为str,用于训练模型的正则化子类型。
- 使用l1正则化:“l1”
- 使用l2正则化:“l2”
- 若为None则表示无正则化(默认)
- intercept:接收类型为bool,指示是否使用训练数据的增强表示(即是否激活偏差特征)。(默认值:False)
- validateData:接收类型为bool,指示算法是否应在训练前验证数据。(默认值:True)
- convergenceTol:接收类型为float,决定迭代终止的条件。(默认值:0.001)
实例运用
from pyspark.mllib.linalg import SparseVector
from pyspark.mllib.regression import RidgeRegressionWithSGD
from pyspark.mllib.regression import LabeledPoint
data = [
LabeledPoint(0.0, [0.0]),
LabeledPoint(1.0, [1.0]),
LabeledPoint(3.0, [2.0]),
LabeledPoint(2.0, [3.0])
]
lrm = RidgeRegressionWithSGD.train(sc.parallelize(data), iterations=10)
lrm.predict([10.0])
import os, tempfile
path = tempfile.mkdtemp()
lrm.save(sc, path)
sameModel = RidgeRegressionModel.load(sc, path)
sameModel.predict(np.array([0.0])) 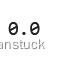
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
以上是关于PySpark数据分析基础:pyspark.mllib.regression机器学习回归核心类详解+代码详解的主要内容,如果未能解决你的问题,请参考以下文章
PySpark数据分析基础:pyspark.mllib.regression机器学习回归核心类详解+代码详解
PySpark数据分析基础:pyspark.mllib.regression机器学习回归核心类详解+代码详解