前端智能化实践——可微编程
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端智能化实践——可微编程相关的知识,希望对你有一定的参考价值。

研究者表示,由于广泛的科学计算和机器学习领域在底层结构上都需要线性代数的支持,因此有可能以可微编程的形式,创造一种新的编程思想。下面,我们就一起进入这个全新的领域。
什么是可微编程
通过动画、动效增加 UI 表现力,作为前端或多或少都做过。这里以弹性阻尼动画的函数为例:
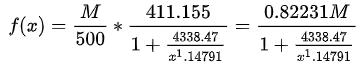
函数在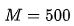 时是效果最好的。最终,实现成 javascript 代码:
时是效果最好的。最终,实现成 javascript 代码:
function damping(x, max)
let y = Math.abs(x);
// 下面的参数都是来源于公式用数值拟合的结果
y = 0.82231 * max / (1 + 4338.47 / Math.pow(y, 1.14791));
return Math.round(x < 0 ? -y : y);

图 1 Julia Computing 团队发表的论文(摘自论文:https://arxiv.org/pdf/1907.07587.pdf)
如图 1 所示,2019 年 Julia Computing 团队发表论文《A Differentiable Programming System to Bridge Machine Learning and Scientific Computing》表示他们构建了一种可微编程系统,它能将自动微分内嵌于 Julia 语言,从而将其作为 Julia 语言的第一公民。如果将可微编程系统视为编程语言第一公民,那么不论是机器学习还是其它科学计算都将方便不少。Y Combinator Research 研究者 Michael Nielsen 对此非常兴奋,非常赞同 Andrej Karpathy 的观点。Karpathy 说:「我们正向前迈出了一步,与原来对程序有完整的定义不同,我们现在只是写一个大致的解决问题的框架,这样的框架会通过权重把解决过程参数化。如果我们有一个好的评估标准,那么最优化算法就能帮我们找到更好的解(参数)。」
这里 Karpathy 说的就是传统编程和可微编程的区别,可微编程会通过梯度下降等最优化方法自动搜索最优解。但这里有个问题,程序需要梯度才能向着最优前进,因此程序的很多部分都要求是可微的。鉴于这一点,很多人也就将机器学习(ML)称呼为可微编程了。
但是可微编程只能用于机器学习吗?它能不能扩展到其它领域,甚至成为编程语言的基本特性?答案是可以的,这就是 Julia 团队及 MIT 等其他研究机构正在尝试的。近年来,机器学习模型越来越精妙,展现出了很多科学计算的特性,侧面凸显了机器学习框架的强大能力。研究者表示,由于广泛的科学计算和机器学习领域在底层结构上都需要线性代数的支持,因此有可能以可微编程的形式,创造一种新的编程思想。下面,我们就一起进入这个全新的领域。
▐ 可微编程和自动微分的关系
在开始可微编程之前,我想先简单回顾一下之前计算弹性阻尼的例子。你会发现
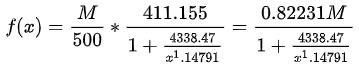
函数在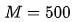 这个公式是用参数拟合曲线借助“数值解”来推导近似函数,其实是在用数值微分的方法。真正的弹性阻尼公式应该是
这个公式是用参数拟合曲线借助“数值解”来推导近似函数,其实是在用数值微分的方法。真正的弹性阻尼公式应该是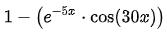 ,前面 H5 弹性阻尼实现的例子中,就是用数值来拟合图 2 弹性阻尼函数图像的一部分来实现弹性效果。
,前面 H5 弹性阻尼实现的例子中,就是用数值来拟合图 2 弹性阻尼函数图像的一部分来实现弹性效果。
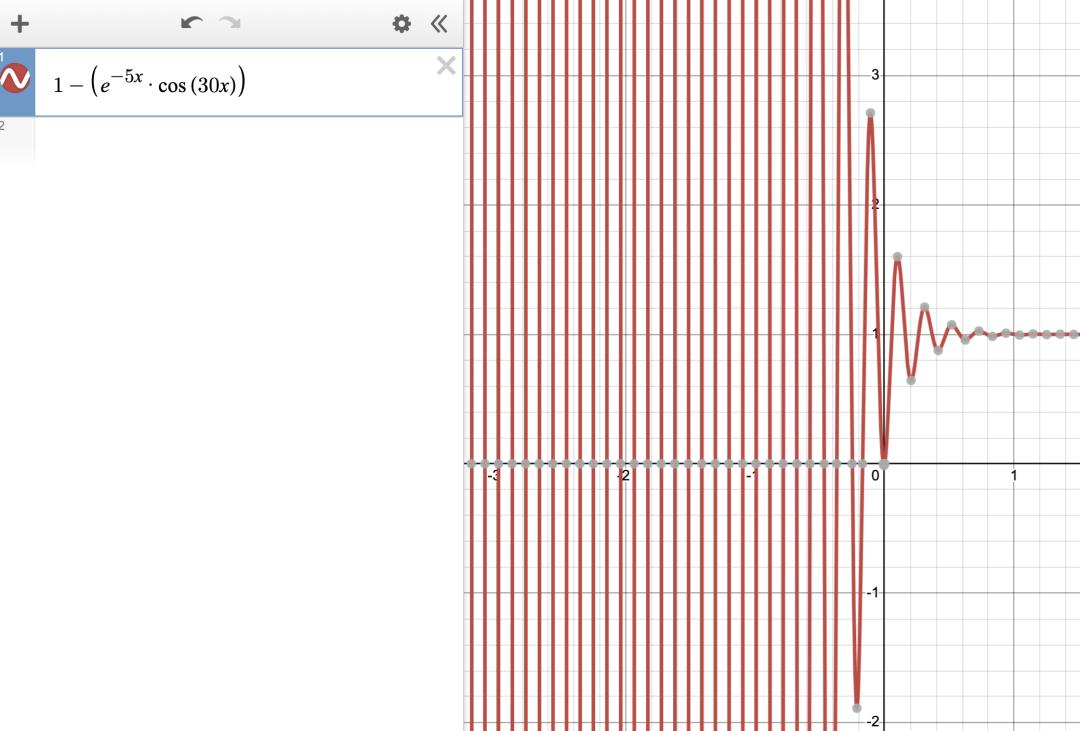
图 2 弹性阻尼函数(图片用工具:https://www.desmos.com/calculator?lang=zh-CN产生)
数值微分法:
只要 h 取很小的数值,比如0.0001,那么我们可以很方便求解导数,并且可以对用户隐藏求解过程,用户只要给出目标函数和要求解的梯度的变量,程序可以自动给出相应的梯度,这也是某种意义上的“自动微分”。而我们在 H5 弹性阻尼函数的求解过程中,使用的正式这种“自动微分”技术。数值微分法的弊端在于计算量大,由于是做拟合相当于我们要把公式
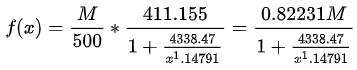
函数在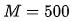 的参数全部拟合出来,才能够在函数:
的参数全部拟合出来,才能够在函数:
y = 0.82231 * max / (1 + 4338.47 / Math.pow(y, 1.14791));
中正确设置参数。
符号微分(Symbolic Differentiation)属符号计算的范畴,其计算结果是导函数的表达式。符号计算用于求解数学中的公式解(也称解析解)。和前文数值解不同的是,通过符号位分得到的是解的表达式而非具体的数值。根据基本函数的求导公式以及四则运算、复合函数的求导法则,符号微分算法可以得到任意可微函数的导数表达式。
以函数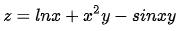 为例,根据求导公式通过符号计算得到对
为例,根据求导公式通过符号计算得到对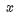 的偏导数为:
的偏导数为:
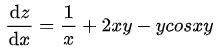
然后将自变量的值代入导数公式,得到任意点处的导数值。符号微分计算出的表达式需要用字符串或其他数据结构存储,如表达式树。数学软件如 Mathematica,Maple,matlab 中实现了这种技术,python 语言的符号计算库也提供了这类算法。
对于深层复合函数,如机器学习中神经网络的映射函数,符号微分算法得到的导数计算公式将会非常冗长。这种冗长的情况,我们称为表达式膨胀(expression swell)。对于机器学习中的应用,不需要得到导数的表达式,而只需计算函数在某一点处的导数值,从而以参数的形式更新神经元的权重。因此,符号微分在计算冗余且成本高昂。例如:对于公式  如果采用符号微分算法,当n=1,2,3,4时的 ln 及其导数如图 3 所示。
如果采用符号微分算法,当n=1,2,3,4时的 ln 及其导数如图 3 所示。

图 3 符号微分的膨胀问题
自动微分不同于数值微分和符号位分,它是介于符号微分和数值微分之间的一种方法。数值微分一开始就代入数值近似求解,而符号微分直接对表达式进行推导,最后才代入自变量的值得到最终解。自动微分则是将符号微分应用于最基本的运算(或称原子操作),如常数,幂函数,指数函数,对数函数,三角函数等基本函数,代入自变量的值得到其导数值,作为中间结果进行保留。然后,再根据这些基本运算单元的求导结果计算出整个函数的导数值。
自动微分的灵活强,可实现完全向用户隐藏求导过程,由于它只对基本函数或常数运用符号微分法则,因此可以灵活地结合编程语言的循环、分支等结构,根据链式法则,借助于计算图计算出任意复杂函数的导数值。由于存在上述优点,该方法在现代深度学习库中得到广泛使用。Julia 的论文实现的 zygote 工具进行的可微编程,研究人员定义了一个损失函数,将点光源作为输入在图像上产生光照,如图 4 所示和参考图像进行对比。通过可微编程的方式自动计算和提取梯度,并用于更新点光源的位置:
julia> guess = PointLight(Vec3(1.0), 20000.0, Vec3(1.0, 2.0, -7.0))
julia> function loss_function(light)
rendered_color = raytrace(origin, direction, scene, light, eye_pos)
rendered_img = process_image(rendered_color, screen_size.w,
screen_size.h)
return mean((rendered_img .- reference_img).^2)
end
julia> gs = gradient(x -> loss_function(x, image), guess)
图 4 生成图片和点光源的关系
可微编程实现智能应用程序
在 Julia 之后 Swift 也推出了自己的可微编程,对,你没听错,就是 Apple 应用开发推荐编程语言 Swift。在 Swift 的可微编程提案中,研究人员提出了“智能应用程序”的概念。智能应用程序很智能:它们使用机器学习技术来增强用户体验。智能应用程序可以借助可微编程的强大能力,对应用的行为做出预测、提供建议并了解用户偏好,根据用户偏好智能调整应用的行为。
智能应用的核心是可微编程,自动微分可用于通过梯度下降系统地优化(即找到“好”值)参数。通过传统编程思想的算法优化,这些参数通常很难处理,要么是类似数值微分和符号微分中那样参数太多,要么是难以和应用的行为做关联。例如,我们要开发一个智能播放器,它尝试根据播放器内容类型和播放器的用户偏好自动调整播放速度。
enum PodcastCategory
case comedy
case news
...
enum PodcastSection
case advertisement
case introduction
case body
case conclusion
struct PodcastState
let category: PodcastCategory
let section: PodcastSection
struct PodcastSpeedModel
var minSpeed, maxSpeed: Float
var categoryMultipliers: [PodcastCategory: Float]
var sectionMultipliers: [PodcastSection: Float]
/// Returns a podcast speed multiplier prediction for the given podcast category
/// and section.
func prediction(for state: PodcastState) -> Float
let speed = categoryMultipliers[state.category] * sectionMultipliers[state.section]
if speed < minSpeed return minSpeed
if speed > maxSpeed return maxSpeed
return speed
此播放器的播放速度参数为:minSpeed、maxSpeed、 categoryMultipliers和sectionMultipliers。根据我们的经验来判断的话,什么是好的参数?不同的用户可能会有不同的答案,无法根据用户偏好设定不同的参数值。
智能应用程序可以借助可微编程来确定个性化的参数值,如下:
让用户手动设置速度,并在用户改变速度时记录观察结果的参数值。
在收集到足够的观察值后,搜索参数值,使模型预测的速度接近用户的首选速度。如果找到这样的值,播放器会产生预测并自动设置速度。
“梯度下降”是执行这种搜索的算法,而支持可微编程的语言可以很容易地实现梯度下降。这是一些说明梯度下降的伪代码:
// 首先,我们需要一个梯度下降的目标函数来最小化,这里使用平均绝对误差:
struct Observation
var podcastState: PodcastState
var userSpeed: Float
func meanError(for model: PodcastSpeedModel, _ observations: [Observation]) -> Float
var error: Float = 0
for observation in observations
error += abs(model.prediction(for: observation.podcastState) - observation.userSpeed)
return error / Float(observations.count)
// 接下来,我们实现梯度下降算法。
var model = PodcastModel()
let observations = storage.observations()
for _ in 0..<1000
// The language differentiates `meanError` to get a "gradient", which is a value indicating
// how to change `model` in order to decrease the value of `meanError`.
let gradient = gradient(at: model) meanError(for: $0, observations)
// Change `model` in the direction that decreased the value of `meanError`.
model -= 0.01 * gradient
至此,我们就使用可微编程的能力实现了智能应用的关键部分,这个应用会随着用户实际使用过程越来越智能、越来越懂用户的偏好,从而自动帮助用户设置播放速度。
除了用可微编程来实现前文中播放速度智能化控制外,动画参数的变化率、使用物理方程在游戏引擎中的可微函数建模、游戏中的 NPC 用可微编程实现和玩家之间智能的互动、流体和其他物理过程的模拟技术基于用导数定义的方程的近似解等等。机器人和机械工程中使用的自动控制算法也依赖于对关节和其他物理系统的行为进行建模,可微编程可以轻松得到这些模型函数的导数。只要你愿意,你几乎可以在所有编程场景里用可微编程的思想来智能化解决问题。
用工具方程拟合
完整的代码可以从:https://github.com/JunreyCen/blog/issues/8这里找到,JunreyCen 在这里详细的介绍了他研究和实现弹性阻尼动画的过程。为了解决计算动画变化速率参数的问题,他使用了 4PL:
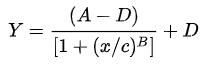
进行函数拟合。用到的是一个网站提供的工具,这个网站的网址是:http://www.qinms.com/webapp/curvefit/cf.aspx。您可以在这里通过把 JunreyCen 采集的,ios 动画数据输入来获得 4PL 里 A、B、C、D 四个参数的具体值。
train_x = (0,500,1000,1500,2500,6000,8000,10000,12000)
train_y = (0,90,160,210,260,347.5,357.5,367.5,377.5)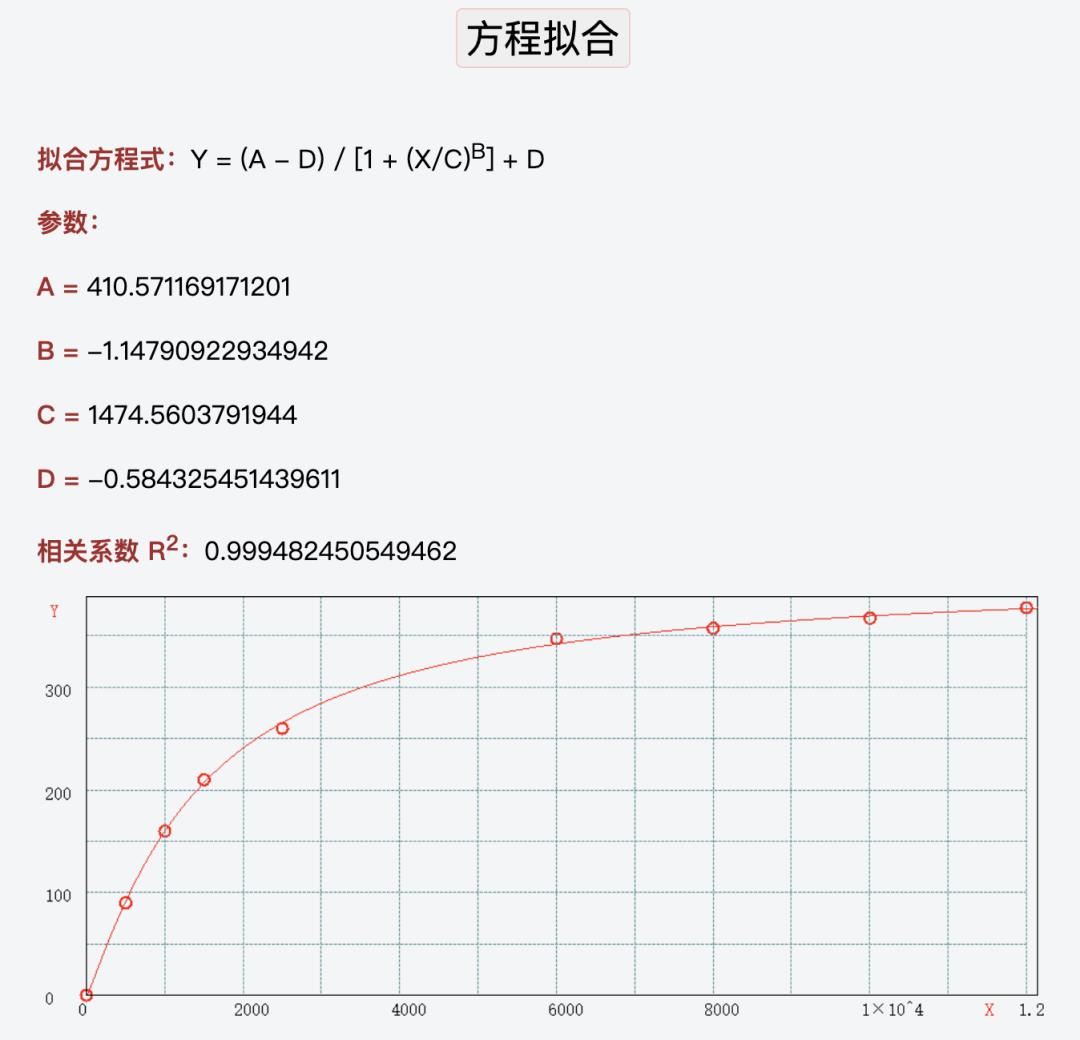
图 5 函数拟合工具(引自:http://www.qinms.com/webapp/curvefit/cf.aspx)
有了 A、B、C、D 四个参数以及 4PL 公式:
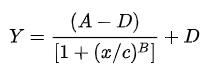
您就可以得到之前 JavaScript 代码里的弹性阻尼算法,从而实现 iOS 一样的弹性阻尼效果。到这里,您可能会想:能够做弹性动画挺酷的但还有什么用呢?其实,只要稍作抽象我们就能把这个方法提炼成处理动画的通用方法。例如设计师在 AfterEffect 里制作了一段儿动画,您只需要在动画的关键帧上采集一系列的数据,然后用函数拟合的方法找到对应的参数和函数,再将参数和函数融入到程序算法中,就能够通过它们来控制动画效果了。
多项式拟合
这种全新的动画编程方式和可微编程有什么关系呢?其实,用一个 3rd-party 的工具我们既不知道它是如何工作的,也不方便集成到工程项目中去,因此,你可以用可微编程快速实现一个自己的函数拟合算法。由于之前围绕 TensorFlow 的自动微分介绍可微编程,这里我就介绍一下如何用可微编程实现多项式拟合。
多项式拟合利用定理:任意函数在较小范围内,都可以用多项式任意逼近。因此,在实际工程实践中,如果不知道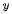 值与
值与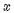 值的数学关系无法通过数学公式设计程序算法,则可以用多项式拟合的回归分析方法,强行进行拟合逼近答案。那么如何逼近呢?对于只有一个特征值
值的数学关系无法通过数学公式设计程序算法,则可以用多项式拟合的回归分析方法,强行进行拟合逼近答案。那么如何逼近呢?对于只有一个特征值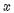 的问题,前辈们发明了一种聪明的办法,就是把特征值的高次方作为另外的特征值,加入到回归分析中,用公式描述:
的问题,前辈们发明了一种聪明的办法,就是把特征值的高次方作为另外的特征值,加入到回归分析中,用公式描述:
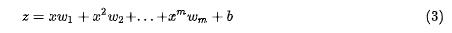
上式中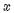 是原有的唯一特征值,
是原有的唯一特征值,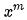 是利用
是利用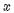 的
的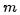 次方作为额外的特征值,这样就把特征值的数量从 1 个变为
次方作为额外的特征值,这样就把特征值的数量从 1 个变为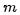 个。换一种表达形式,令:
个。换一种表达形式,令:
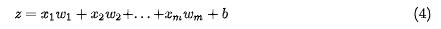
随着多项式项数增加,算法的运算复杂度也会随之增加,而实际操作下来,对拟合弹性阻尼函数时,会发现三次多项式即可达到很好的效果,公式 $$z = x w_1 + x^2 w_2 + x^3 w_3 + b $$ 是仅使用前三项的多项式拟合。多项式次数并不是越高越好,对不同的问题有特定限制,需要在实践中摸索。
讲完理论部分,下面就让我们用可微编程在 TensorFlow 里实操一遍。环境准备和之前一样:
# 安装 MiniConda 创建环境:并更新:pip install -U pip
conda install -c apple tensorflow-deps
pip uninstall tensorflow-macos
pip uninstall tensorflow-metal
# 进入工作目录启动 Jupyter Notebook 进行实验
jupyter notebook在 Notebook 里准备 TensorFlow 环境:
import tensorflow as tf
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
输出:
Version: 2.8.0
Eager mode: True
GPU is available可以看到,我使用的 TensorFlow 是 2.8.0 版本,由于笔记本里 M1 Pro 有性能强劲的 GPU,在 GPU is available 加持下,训练速度非常快。
准备数据:
train_x = [0,500,1000,1500,2500,6000,8000,10000,12000]
train_y = [0,90,160,210,260,347.5,357.5,367.5,377.5]开始可微编程:
optimizer = tf.keras.optimizers.Adam(0.1)
t_x = tf.constant(train_x,dtype=tf.float32)
t_y = tf.constant(train_y,dtype=tf.float32)
wa = tf.Variable(0.,dtype = tf.float32,name='wa')
wb = tf.Variable(0.,dtype = tf.float32,name='wb')
wc = tf.Variable(0.,dtype = tf.float32,name='wc')
wd = tf.Variable(0.,dtype = tf.float32,name='wd')
variables = [wa,wb,wc,wd]
for e in range(num):
with tf.GradientTape() as tape:
#预测函数
y_pred = tf.multiply(wa,t_x)+tf.multiply(w2,tf.pow(t_x,2))+tf.multiply(wb,tf.pow(t_x,2))+tf.multiply(wc,tf.pow(t_x,2))+wd
#损失函数
loss=tf.reduce_sum(tf.math.pow(y_pred-t_y,2))
#计算梯度
grads=tape.gradient(loss, variables)
#更新参数
optimizer.apply_gradients(grads_and_vars=zip(grads,variables))
if e % 100 == 0:
print("step: %i, loss: %f, a:%f, b:%f, c:%f, d:%f" % (e,loss,wa.numpy(),wb.numpy(),wc.numpy(),wd.numpy()))在上面的代码里有几个关键的部分需要注意:optimizer、wa,wb,wc,wd、loss、grads、apply_gradients 这五个部分。optimizer 是优化器,常用的有 SGD 和 Adam ,前者是梯度下降后者则可以理解为加强版,对于本示例只有 9 条数据这种样本比较少的情况有奇效。因为 Adam 对每个参数使用相同的学习率,并随着学习的进行而独立地适应。此外,Adam 是基于动量的算法,利用了梯度的历史信息。基于这些特征,我选择了 Adam 而非 SGD。其次,需要关注的是用 tf.Variable(0.,dtype = tf.float32,name='wa') 来声明我们要训练的参数 wa,wb,wc,wd,这部分在前面介绍自动微分的时候说过。loss 损失函数则是用拟合结果对比实际结果的方差来定义的,也叫平均方差损失。梯度部分则利用 TensorFlow 自动微分梯度带计算方法 tape.gradient(loss, variables) 来进行计算。最后,apply_gradients 把我们计算好的梯度 grads 应用到参数上去进行下一轮的拟合。我们重复这个过程 10000 次,不断的优化参数来逼近实际数据:
step: 0, loss: 4.712249, a:0.100003, b:0.100003, c:0.100003, d:0.100003
step: 100, loss: 0.164529, a:1.204850, b:-0.219918, c:-0.219918, d:0.294863
step: 200, loss: 0.082497, a:1.994068, b:-0.615929, c:-0.615929, d:0.209093
step: 300, loss: 0.073271, a:2.291683, b:-0.766129, c:-0.766129, d:0.176420
...
step: 9700, loss: 0.072893, a:2.371203, b:-0.804242, c:-0.804242, d:0.169179
step: 9800, loss: 0.072850, a:2.369858, b:-0.805587, c:-0.805587, d:0.167835
step: 9900, loss: 0.072853, a:2.369503, b:-0.805943, c:-0.805943, d:0.167479
训练好之后,把结果打印出来看看实际效果:
plt.scatter(t_x,t_y,c='r')
y_predict = tf.multiply(wa,t_x)+tf.multiply(w2,tf.pow(t_x,2))+tf.multiply(wb,tf.pow(t_x,2))+tf.multiply(wc,tf.pow(t_x,2))+wd
print(y_predict)
plt.plot(t_x,y_predict,c='b')
plt.show()
# 输出:
tf.Tensor(
[0.16805027 0.2640069 0.3543707 0.4391417 0.59190494 0.95040166
1.0322142 1.0245409 0.92738193], shape=(9,), dtype=float32)由于训练数据和预测的数据都做了归一化,需要处理一下才能看到真实结果:
print(*(y_predict.numpy())*377.5)
# 输出:
63.43898 99.66261 133.77495 165.77599 223.4441 358.77664 389.66086 386.7642 350.08667
# 真实数据:
train_y = [0,90,160,210,260,347.5,357.5,367.5,377.5]从图 6 中可以看到,我们已经借助多项式拟合和可微编程成功“逼近”了真实数据,图中红点代表真实数据,蓝色线条是根据预测结果绘制。
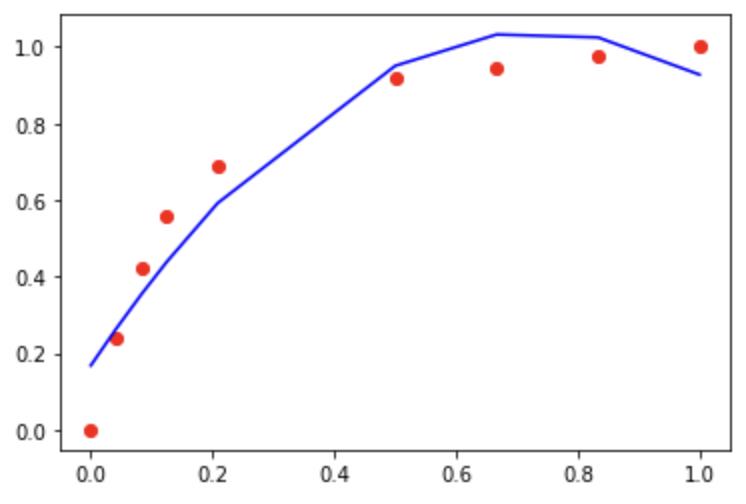
图 6 多项式拟合效果图
scipy用
curve_fit拟合4PL
由于数据量太小,使用多项式拟合的时候,大概在第三轮之后 loss 的变化就不大了,可见多项式拟合对我们要解决的弹性阻尼函数问题并非最优解。在经过了一番研究,我找到 python 的科学计算工具包 scipy ,在 optimizer 里有一个 curve_fit 工具效果很好,能够把我们的 4PL 公式
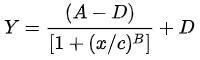
很好的拟合出来:
from scipy import stats
import scipy.optimize as optimization
xdata = t_x
ydata = t_y
def fourPL(x, A, B, C, D):
return ((A-D)/(1.0+((x/C)**(B))) + D)
guess = [0, -0.3, 0.7, 1]
params, params_covariance = optimization.curve_fit(fourPL, xdata, ydata, guess)#, maxfev=1)
x_min, x_max = np.amin(xdata), np.amax(xdata)
xs = np.linspace(x_min, x_max, 1000)
plt.scatter(xdata, ydata)
plt.plot(xs, fourPL(xs, *params))
plt.show()如图 7 所示函数拟合的效果很好,可见,用 scipy 提供的新方法 optimization.curve_fit() 进行可微编程和使用 TensorFlow 区别不大,也是针对函数里的参数进行训练,返回 params 代表训练后的参数。
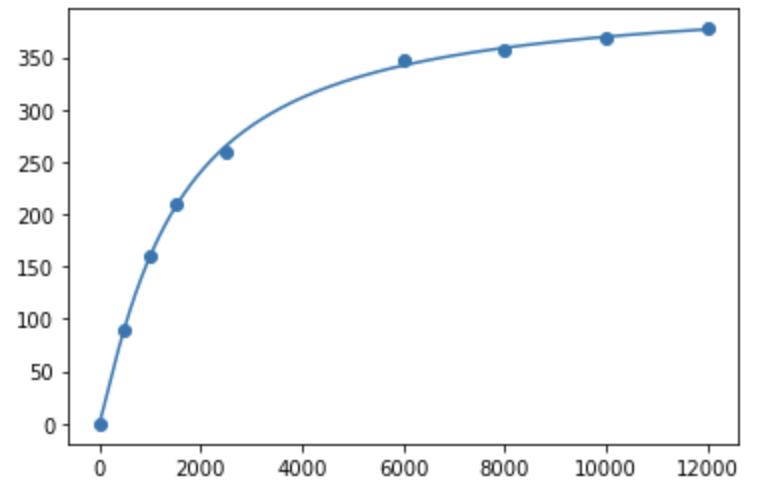
图 7 用 Scipy 里的 curve_fit 进行拟合的效果
我们打印一下用 scipy 训练后的参数:
print(*params)
# 输出:# 使用工具得到的参数:
A = 410.517236432893 A = 405.250160538176
B = 1.1531891657236022 B = -1.17885294211307
C = 1481.6957597831604 C = 1414.70383142617
D = -0.16796047781164916 D = -0.516583385175963您会发现和图 5 函数拟合工具得到的参数还是很接近的。回到阻尼函数
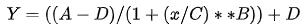
代入我们拟合的参数:A=410.517236432893、B=1.1531891657236022、C=1481.6957597831604、D=-0.16796047781164916,舍去 D 四舍五入简化表达式:
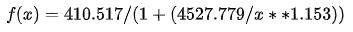
代入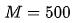 限制条件:$f(x) = (M * (410.517 / 500)) / (1+(4527.779/x**1.153)) $ 得到:
限制条件:$f(x) = (M * (410.517 / 500)) / (1+(4527.779/x**1.153)) $ 得到:
y = 0.821 * max / (1 + 4527.779 / Math.pow(y, 1.153));
对比 3rd-party 工具产出的参数:
y = 0.82231 * max / (1 + 4338.47 / Math.pow(y, 1.14791));
最终,程序算法上的差异很小。我使用:https://github.com/JunreyCen/blog/issues/8的代码进行实际运行测试,两者实际表现上差异不大,效果都挺好的。您在使用示例的时候要注意一下,对:
<script src="https://cdn.jsdelivr.net/npm/vue"></script>
做个小修改:
<script src="http://static.runoob.com/assets/vue/1.0.11/vue.min.js"></script>
即可。
神经网络的拟合
虽然,到这里似乎已经完成了可微编程解决弹性阻尼函数拟合的问题,并找到了程序的算法解决方案,但是,回到智能化编程思想里,我脑海里浮现一个问题:图计算和神经网络能否解决这个问题呢?带着这个问题,我又定义了一个图计算的神经网络:
model = tf.keras.Sequential()
# 添加层
# 注:input_dim(输入神经元个数)只需要在输入层重视设置,后面的网络可以自动推断出该层的对应输入
model.add(tf.keras.layers.Dense(units=10, input_dim=1, activation='selu'))
model.add(tf.keras.layers.Dense(units=10, input_dim=1, activation='selu'))
model.add(tf.keras.layers.Dense(units=10, input_dim=1, activation='selu'))
model.add(tf.keras.layers.Dense(units=10, input_dim=1, activation='selu'))
model.add(tf.keras.layers.Dense(units=10, input_dim=1, activation='selu'))
model.add(tf.keras.layers.Dense(units=10, input_dim=1, activation='selu'))
model.add(tf.keras.layers.Dense(units=10, input_dim=1, activation='selu'))
model.add(tf.keras.layers.Dense(units=10, input_dim=1, activation='selu'))
model.add(tf.keras.layers.Dense(units=10, input_dim=1, activation='selu'))
model.add(tf.keras.layers.Dense(units=10, input_dim=1, activation='selu'))
# 神经元个数 输入神经元个数 激活函数
model.add(tf.keras.layers.Dense(units=1, activation='selu'))
# 输出神经元个数
# 2 设置优化器和损失函数
model.compile(optimizer='adam', loss='mse')
# 优化器 损失函数(均方误差)
# 3 训练
history = model.fit(t_x, t_y,epochs=2000)
# 4 预测
y_pred = model.predict(t_x)这里我用 TensorFlow 的 keras API 定义了十个 Dense 层,每层有十个神经元、一个输入维度和 selu 非线性激活函数,再定义了一个神经元同样激活函数的 Dense 层作为输出。这个定义是通过实验发现过多或过少的神经元都无法提升训练效果,太多的层也无法更好的优化准确率。模型的优化器如前面的示例也是 adam,损失函数也是平均方差损失函数 mse。训练过程:
1/1 [==============================] - 1s 573ms/step - loss: 74593.5156
Epoch 2/2000
1/1 [==============================] - 0s 38ms/step - loss: 74222.5469
Epoch 3/2000
1/1 [==============================] - 0s 31ms/step - loss: 74039.7734
...
Epoch 1994/2000
1/1 [==============================] - 0s 26ms/step - loss: 0.3370
Epoch 1995/2000
1/1 [==============================] - 0s 25ms/step - loss: 0.3370
Epoch 1996/2000
1/1 [==============================] - 0s 24ms/step - loss: 0.3370
Epoch 1997/2000
1/1 [==============================] - 0s 26ms/step - loss: 0.3370
Epoch 1998/2000
1/1 [==============================] - 0s 24ms/step - loss: 0.3370
Epoch 1999/2000
1/1 [==============================] - 0s 25ms/step - loss: 0.3369
Epoch 2000/2000
1/1 [==============================] - 0s 24ms/step - loss: 0.3369
可以看到,整个神经网络的训练过程持续稳定的提升,一直到近 2000 个 Epoch 的时候 loss 损失还在继续下降,可见继续训练还能进一步提升拟合效果,更好的逼近真实数据。按照管理,我们画个图来观察一下效果:
# 5 画图
plt.scatter(xdata, ydata)
plt.plot(t_x, y_pred, 'r-', lw=5)
plt.show()如图 8 所示,训练好的神经网络预测结果和真实数据对比几乎是一致的,但是,对比之前 4PL 和多项式的函数拟合,整体效果并不像函数的曲线一样平滑,整体呈现过拟合的状态。
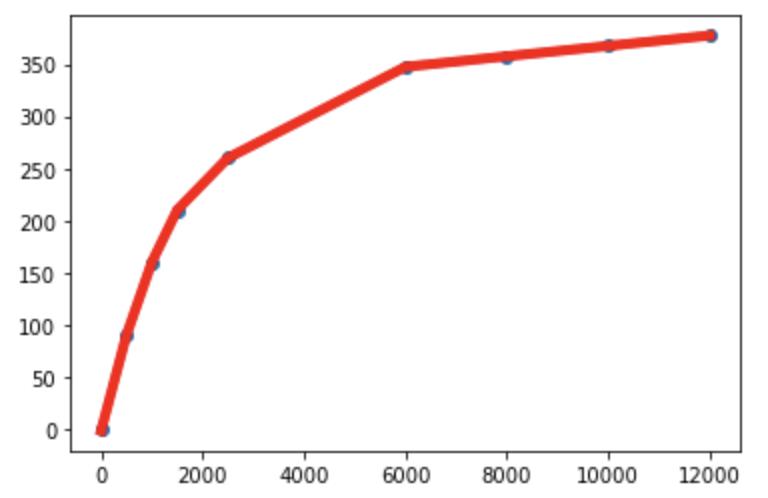
图 8 神经网络拟合效果
我们对比原始数据:
print(t_x.reshape(-1, 1)) print(model.predict(t_x.reshape(-1, 1)))
# 输出:预测输出:
[[ 0.]
[ 500.]
[ 1000.]
[ 1500.]
[ 2500.]
[ 6000.]
[ 8000.]
[10000.]
[12000.]]
print(t_y.reshape(-1,1))
# 输出:
[[ 0. ] [-1.7345996]
[ 90. ] [90.01992]
[160. ] [159.91837]
[210. ] [210.06012]
[260. ] [260.01797]
[347.5] [347.43182]
[357.5] [357.57867]
[367.5] [367.53287]
[377.5]] [377.4857]可以看到,对比真实数据神经网络预测的结果是非常精确的,误差比使用多项式拟合的效果好非常多。
至此,我们使用了 4PL、多项式以及神经网络三种可微编程的方法,对弹性阻尼函数进行拟合,逼近真实数据的效果虽然有一定差异,但总体都拟合的比较好。同神经网络的方法不同,4PL 和多项式拟合可以直接提供公式和参数,我们可以方便的将其应用在程序的算法中。而对于神经网络,则需要把神经网络在浏览器里跑起来,下面就介绍一下这个过程。
浏览器执行示例
为了能够把神经网络在浏览器里跑起来,并让 JavaScript 可以调用,首先需要将神经网络存储成文件。
model.save('saved_model/w4model')存储到目录后会得到两个文件:keras_metadata.pb 和 saved_model.pb 以及两个目录:assets 和 variables 。这里使用的是 TensorFlow 的 tf_saved_model,下面转换模型给 TensorFlow.js 在浏览器使用的时候会用到这个参数。
为了能够让模型在浏览器运行,先安装 pip install tensorflowjs 用 tensorflowjs_converter 命令行转换工具进行模型的转换:
tensorflowjs_converter --input_format=tf_saved_model \\
--output_node_names="w4model" \\
--saved_model_tags=serve ./saved_model/w4model ./web_model这里 --input_format 参数 tf_saved_model 对应之前模型存储使用的方法,要注意不同方法保存的文件格式和结构的不同相互不兼容。--output_node_names 是模型的名称,--saved_model_tags 中 tag 是用来区别不同的 MetaGraphDef,这是在加载模型所需要的参数其默认值是 serve。
通过 tensorflowjs_converter 进行模型转换后,我们在 web_model 文件夹里会看到 group1-shard1of1.bin 以及 model.json 两个文件。这两个文件中,以 .json 后缀结尾的文件是模型定义文件,以 .bin 后缀结尾的文件是模型的权重文件。您可以把模型定义文件看做 4PL 和多项式的函数,把模型权重文件看做函数的参数。
通过 npm 初始化一个 node.js 项目,然后在 package.json 配置文件里加入:
"dependencies":
"@tensorflow/tfjs": "^3.18.0",
"@tensorflow/tfjs-converter": "^3.18.0"
,这里的 @tensorflow/tfjs 是 TensorFlow.js 提供的运行时依赖,而 @tensorflow/tfjs-converter 则是加载我们转换的模型所需要的依赖。接下来,在 EntryPoint 的 JavaScript 程序文件里加入:
import * as tf from "@tensorflow/tfjs";
import loadGraphModel from "@tensorflow/tfjs-converter";将依赖引入到程序文件中,这里要注意 loadGraphModel 是我们从 @tensorflow/tfjs-converter 依赖中导入的,虽然 @tensorflow/tfjs 提供 tf.loadGraphModel() 方法加载模型,但是这个方法只适用于 TensorFlow.js 中保存的模型,我们通过 Python 里 model.save() 方法保存,并用 Converter 转换的模型,必须用 tfjs-converter 依赖包中提供的 loadGraphModel 方法进行加载。
接着是程序完整的代码:
import * as tf from "@tensorflow/tfjs";
import loadGraphModel from "@tensorflow/tfjs-converter";
window.onload = async () =>
const resultElement = document.getElementById("result");
const MODEL_URL = "model.json";
console.time("Loading of model");
const model = await loadGraphModel(MODEL_URL);
console.timeEnd("Loading of model");
const test_data = tf.tensor([
[0.0],
[500.0],
[1000.0],
[1500.0],
[2500.0],
[6000.0],
[8000.0],
[10000.0],
[12000.0],
]);
tf.print(test_data);
console.time("Loading of model");
let outputs = model.execute(test_data);
console.timeEnd("execute:");
tf.print(outputs);
resultElement.innerText = outputs.toString();
;这里需要注意的是,由于我们的模型在预测时使用的是张量作为输入,因此,需要用 tf.tensor() 方法来返回经过包装的张量作为模型的输入。运行程序后,我们可以从浏览器开发者工具的控制台看到打印的调试信息:
[Violation] 'load' handler took 340ms
index.js:12 Loading of model: 67.19482421875 ms
print.ts:34 Tensor
[[0 ],
[500 ],
[1000 ],
[1500 ],
[2500 ],
[6000 ],
[8000 ],
[10000],
[12000]]
index.js:28 execute: 257.47607421875 ms
print.ts:34 Tensor
[[-1.7345995 ],
[90.0198822 ],
[159.9183655],
[210.0600586],
[260.0179443],
[347.4320068],
[357.5788269],
[367.5332947],
[377.4856262]]这里加载模型花费了 67ms,执行预测花费了 257ms,还是蛮长的。我们在
import * as tf from "@tensorflow/tfjs";
import loadGraphModel from "@tensorflow/tfjs-converter";
window.onload = async () =>
// 新加入 webgl 硬件加速能力
tf.setBackend("webgl");
console.log(tf.getBackend());
// 打印当前后端信息
const resultElement = document.getElementById("result");
const MODEL_URL = "model.json";我们会看到控制台输出 webgl 代表 TensorFlow.js 成功启用了 WebGL 的加速能力,在其加速之下,我们在预测的时候速度会从 257ms 大幅度提升到 131ms,多次预测时间由于权重和计算图已经加载到显存中速度会更快,达到 78ms 左右。当然,对于动画来说这种耗时还是有点多,您可以回顾本书端智能的部分,使用相关的工具和方法对模型进行压缩和优化,只需要在模型输出的时候选择 TensorFlow.js,或者用 TensorFlow 提供的工具把优化后的模型转成 TensorFlow.js 的模型即可复用这个示例中的代码。
最后,让我们再次回到弹性阻尼函数在 JavaScript 里的定义:
damping(x, max)
let y = Math.abs(x);
y = 0.821 * max / (1 + 4527.779 / Math.pow(y, 1.153));
return Math.round(x < 0 ? -y : y);
,把这里的 y 变成模型预测的结果:y = model.execute(tf.tensor([[x],])); 即可用模型来拟合弹性阻尼函数并返回计算结果。
您可能会问:既然我有 4PL、多项式拟合等方法,为什么要用神经网络呢?是的,如果您要解决的问题简单到足以用函数拟合的方式解决,同时,您也知道应该用 4PL 还是多项式异或是其它函数进行拟合来逼近真实情况。满足这两个前提条件,当然可以用函数拟合的方式直接找到对应的函数和参数来解决问题。但是,现实中我们要解决的问题往往会更加的复杂,比如我们想做个语音输入交互能力,就需要对语音进行音频信号解析、分析、处理、语义识别、转文本等等过程,每个环节中要解决的问题都无法简单用一个函数和单变量多参数方式去描述和拟合变量间的关系。因此,我们可以把复杂的问题用神经网络去拟合,让神经网络通过神经元、Edge、权重、参数等以自动微分的能力去寻找答案。
最后,需要指出的是拟合毕竟是一种近似,无法揭示问题本质是什么?这就是大家经常质疑机器学习可解释性的根源所在。试想一下,如果我们程序的弹性阻尼算法是根据物理学定义的公式去编写的,那这个算法就具备了可解释性。具备了可解释性,我就能够揭示每个变量的意义以及变量之间的关系,从而使程序和算法具备更精确、细致的处理能力。而函数拟合或神经网络拟合的可微编程中,机器学习到了什么?我们很难给出答案,只能通过反复实验来推定函数或神经网络能够根据输入估计出正确的输出。因此,我们不能遇到问题就一股脑的使用可微编程去解决,在解释性方面有强诉求的场景中,尽量还是要从问题本身出发找出解决的途径。
团队介绍
我们是阿里巴巴-大淘宝技术-导购和营销产品(原频道与D2C智能团队),也是阿里经济体前端委员会智能化方向的核心团队,隶属于大淘宝技术(大淘宝技术,一支致力于成为全球最懂商业的技术创新团队,旗下包含淘宝技术、天猫技术等团队和业务,是一支是具有商业和技术双重基因的螺旋体)。
我们在 「杭州阿里巴巴西溪园区」 办公,
我们的定位是「用诗人的浪漫和科学家的严谨打造最懂 AI 的 smart and international 的前端团队」,
我们的使命是「前端智能让业务创新更高效」。
✿ 拓展阅读


作者|甄子(甄焱鲲)
编辑|橙子君

以上是关于前端智能化实践——可微编程的主要内容,如果未能解决你的问题,请参考以下文章