阿里前端智能化技术探索和未来思考
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里前端智能化技术探索和未来思考相关的知识,希望对你有一定的参考价值。

未来十年,智能化将不断渗入各领域,改变我们的生活和工作。本文将会分享阿里前端智能化技术的技术实践,探索未来UI智能化的发展方向。
最近看到一个研判:过去十年是智能化蓬勃发展的十年,但未来十年会是智能化渗入各领域不断改变我们生活和工作的十年。对此深以为然。
随着对神经网络加速的专用处理器成为硬件标配、DSP越来越多地从专业领域进入消费电子领域、CPU厂商收购FPGA公司、4nm工艺和3D堆叠工艺以及单周期多指令发射等处理器运算能力的机制提升让PPA不断突破极限,即将把围绕智能化的技术变革推向高潮。
作为立足于改变前端技术工程体系的一群阿里前端,我们期待走在最前沿。从谷歌 TensorFlow团队的合作,到顶会论文的发表、技术雷达收录,再到多项成果在集团乃至行业大范围推广和落地取得成果,阿里前端智能化小组始终在坚定前行。在这篇文章中,我们将从阿里前端智能化整体技术大图中挑选一些有实质突破的部分,分享我们的研究、实践过程。期待和更多前端同行一起参与到前端智能化方向的探索,把这个方向建设的更丰满、更实在、更普惠。
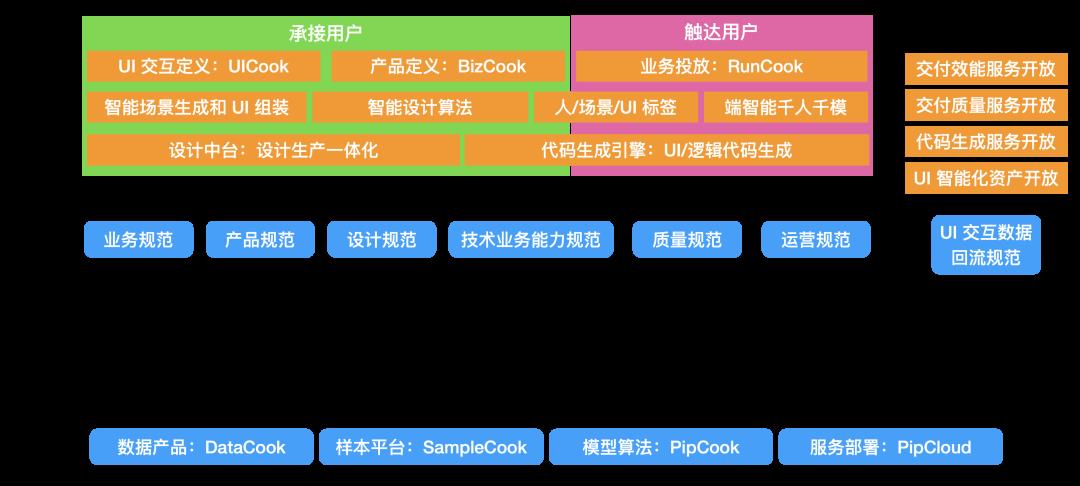
阿里前端智能化技术大图
文章框架(注:内容较多,可直接滑到感兴趣的部分阅读)
前端智能化技术基座:数据和算法技术工程能力是升级的基础
端智能:通过对端智能的介绍,帮助大家把数据能力和算法能力真正应用到前端技术场景
前端智能化技术应用
未来UI 智能化的发展趋势
前端智能化技术基座篇
2021~2022 年是PipCook项目明显变化的一年,在这之前,PipCook更多的是做一个JS社区易用的深度学习的工程框架,很多时候忽略了和业务的结合,也忽略了数据本身的价值。今年,PipCook重点依托于cloud云平台打通业务数据链路,赋能前端数据能力,同时基于datacook提供的分析建模能力深度剖析业务数据,在围绕消费者体验问题上紧扣业务,建立起数据指导迭代的链路,为业务提供价值。
▐ PipCook-Cloud 增强前端数据分析和智能化算法能力
在传统产研结构中:产品经理、设计师、运营、商务、服务端、客户端、前端、测试、BI 等诸多角色中,前端一直是职能角色间接参与业务,对业务的发展无直接影响。但是要为业务提供增长,前端作为将价值输送给用户的桥梁,必须要体系化且深入本质的理解商家与消费者的关系,在平台视角、生态视角之上叠加用户视角,建立起用户运营技术赋能的途径和手段,并将之与商家运营和平台运营、生态运营有机结合在一起。
在这种要求下,数据分析和基于数据的建模能力将会至关重要,我们希望可以通过Pipcook-Cloud这个项目增强前端数据分析和智能化算法能力,逐渐将技术产出、用户使用行为数据以及业务指标三者关联在一起。通过三者关联的指标,逐步系统化和逻辑严谨的描绘出一副从业务目标到产品设计再到技术交付和用户体验的完整图画,在这张图画上指标驱动和数据支撑让用户运营能力有了技术支撑,让产品交付价值有了用户体验指标度量,让前端在业务全生命周期中有了完整的用户价值和情感连接的桥梁。
而目前我们的大数据开发主要是围绕着DataWorks相关工具进行的,开发语言以ODPS SQL为主,同时也可以开发基于Python和 Java的UDF (用户自定义函数)。对于一些数据模型的开发需求,可能也会基于PAI平台进行。当前基于ODPS SQL、Python和Java的开发方式对于前端同学成本有点儿高,原因主要有两个,一方面是有一定的入门门槛,包括语言门槛,处理逻辑编排的门槛,以及对于数据本身理解的门槛,另一方面前端缺乏对于常见的业务数据分析经验(端上用户行为动线分析,人群分成行为分析,前端性能分析,用户点击热力图分析等等)的沉淀,导致很难直接复用一些常见的前端场景的数据分析能力。
同时,目前的报表和数据可视化工具主要面向的人群为BI、运营和数据PD,通过可视化配置数据源和拖拽图表组件的方式搭建报表。对于前端同学来说,一方面,这种方式缺乏灵活性,只能使用准备好的图表组件和能力,很难拓展和自定义跟适合自己业务的报表,而前端恰恰在可视化能力上有天然优势,另一方面,也很难通过模板等方式向用户提供我们沉淀的前端数据分析场景的可视化报表。
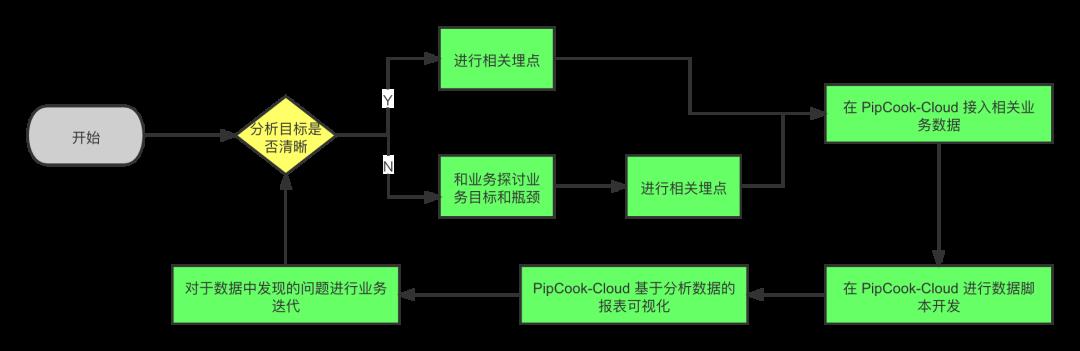
基于以上原因,PipCook-Cloud聚焦于前端数据能力和用户体验和用户增长分析能力,在今年主要解决了以下几个方面的问题:
让前端同学理解数据开发可以做什么,可以为业务带来哪些价值
想要前端同学可以入门数据开发,第一步需要先让前端同学明白数据开发可以做哪些事情,同时,能发现业务数据分析确实可以为业务带来价值,这样一来用户才有了入门和使用PipCook-Cloud的动力。
让前端同学清晰明确的编排自己数据开发的全流程,以完成开发目的
就如同在编程一个系统的时候,需要先对系统有一个设计,可以借助于流程图,ER图等工具来完成系统设计,同样地,在编写一个数据开发链路的时候,我们也需要先有一个设计,清楚的表达和编排出整个数据流。
让前端同学在编写数据处理的逻辑的时候,可以低门槛无成本的实现
一般大数据系统开发的语言都是SQL和Java,如果可以实现基于JS的数据处理系统,那么对于前端同学实现自己的处理逻辑的门槛将会大大降低。
让前端同学在需要一些必要的机器学习模型能力的时候,可以快速完成
在有些场景下,并不能通过确定性的逻辑实现自己的数据分析任务,有的时候需要借助于模型能力挖掘出数据中的模式。
让前端同学基于数据可以轻松开发出业务报表,以阐述自己的结论,帮助业务理解
数据分析的最后一步就是产出结论,很多时候需要业务报表和图表的方式来清楚的阐述数据分析的结论和后续action。
我们在1.0,一直努力将PipCook变成:让前端工程师也能开发靠谱的机器学习应用;而在2.0,我们对此做了稍微的变化:让前端工程师都能开发靠谱的机器学习应用。
在过去一年,我们继续深耕于PipCook提供的深度学习的CI/CD能力,提供模型训练和数据分析的可持续集成和交付,PipCook 1.0的版本让Web开发者能够以比较低的门槛开始深度学习之路。而在实践的过程中,我们也发现了一些问题,比如安装 PipCook比较困难,安装时长长,初次启动训练时PipCook会安装插件也会耗费大量时间,另一方面,也有配置难、不易上手等问题,基于这些问题的解决,我们推出了 PipCook 2.0,目前这块也已经开源 [08]。
▐ DataCook 提升数据分析和处理能力
如果说PipCook-Cloud打通了前端和业务数据的桥梁,通过平台化产品化的方式提供了数据加工和数据开发的工程能力,那么DataCook则是在底层供给PipCook平台的燃料。DataCook提供了JS生态下面向前端的数据科学和机器学习工具库,帮助前端同学轻松运用分析建模能力剖析自己的业务数据,产出具有价值的分析成果。
目前DataCook已经涵盖了包括数据预处理,数据统计分析,机器学习,可视化和跨平台流程部署等多项能力,提供了诸如线性回归,逻辑回归,决策树,PCA等多个模型,方便在各种场景下的建模分析,DataCook目前也已经开源 [09]。

端智能篇
去年,淘系开始发力消费者体验。基于个性化消费场景,构建探索性货品供给、智能化信息表达,是端智能发力的机会。端智能立足于实时性、隐私保护性的基础上提供智能化能力,让前端能够用这些技术手段不断优化消费体验。
过去三年,我们和Google的TensorFlow.js团队在推动前端智能化在端智能应用方向上达成战略合作。前端技术标准组织W3C也密集推出WebCL(见《OpenCL 2.0 异构计算》第三版)、WebGL、WebGPU、WebNN、WASM等前端端智能加速技术,尤其是2022年推出的Web Neural Network API,针对神经网络、张量和图计算加速。摘自:https://www.w3.org/TR/webnn/
比起客户端,前端算力并未被彻底释放。从CPU上来说,虽然WASM的支持率已经高于很多javascript的新特性了,但是SIMD指令的支持率仍然较低。WASM虽然比起JavaScript有优势,但是跟JavaScript+WebGL比起来,因为完全发挥不出CPU的优势,造成运算资源的浪费。WebGL仍然是十几年前的技术,跟OpenGL ES是同一个年代的技术,不支持GPGPU的操作。虽然有 WebGL2支持计算管线,但是因为苹果不支持这部分功能,导致无法使用。而 WebGPU可以从caniuse网站上看到,桌面上浏览器在2018-2020年都已经开始支持WebGPU,移动版浏览器也在跟进。
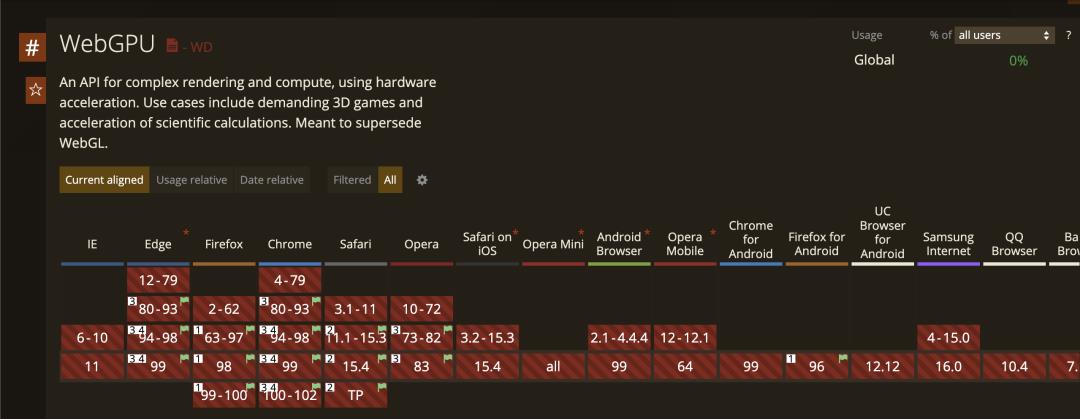
所以我们2021年选定了两个方向来优化我们的端上引擎:WASM+Rust+SIMD和WebGPU。TensorFlow.js虽然没有使用Rust,但是也在使用WASM+SIMD。
▐ WASM + RUST + SIMD
摆脱了Javascript,使用native语言编写WASM,首先的问题就是选择哪个语言。在2021年,Rust在Nightly版本实验性支持了SIMD,成为我们目前最好的选择。
▐ WebGL/WebGPU
下面我们用一个实际例子看看如何在浏览中,借助TensorFlow.js的技术生态把算法模型在纯W3C标准下跑起来,并且通过WebGL对模型预测进行加速。为了能够把神经网络在浏览器里跑起来,并让JavaScript可以调用,首先需要将神经网络存储成文件。
model.save('saved_model/w4model')存储到目录后会得到两个文件:keras_metadata.pb和saved_model.pb以及两个目录:assets和variables。这里使用的是TensorFlow的tf_saved_model,下面转换模型给TensorFlow.js在浏览器使用的时候会用到这个参数。
为了能够让模型在浏览器运行,先安装pip install tensorflowjs用 tensorflowjs_converter命令行转换工具进行模型的转换:
tensorflowjs_converter --input_format=tf_saved_model \\
--output_node_names="w4model" \\
--saved_model_tags=serve ./saved_model/w4model ./web_model这里--input_format参数tf_saved_model对应之前模型存储使用的方法,要注意不同方法保存的文件格式和结构的不同相互不兼容。--output_node_names是模型的名称,--saved_model_tags中tag是用来区别不同的MetaGraphDef,这是在加载模型所需要的参数其默认值是serve。
通过tensorflowjs_converter进行模型转换后,我们在web_model文件夹里会看到group1-shard1of1.bin以及model.json两个文件。这两个文件中,以.json后缀结尾的文件是模型定义文件,以.bin后缀结尾的文件是模型的权重文件。您可以把模型定义文件看做4PL和多项式的函数,把模型权重文件看做函数的参数。
通过npm初始化一个node.js项目,然后在package.json配置文件里加入:
"dependencies":
"@tensorflow/tfjs": "^3.18.0",
"@tensorflow/tfjs-converter": "^3.18.0"
,这里的@tensorflow/tfjs是TensorFlow.js提供的运行时依赖,而@tensorflow/tfjs-converter则是加载我们转换的模型所需要的依赖。接下来,在EntryPoint的JavaScript程序文件里加入:
import * as tf from "@tensorflow/tfjs";
import loadGraphModel from "@tensorflow/tfjs-converter";将依赖引入到程序文件中,这里要注意loadGraphModel是我们从@tensorflow/tfjs-converter依赖中导入的,虽然@tensorflow/tfjs提供 tf.loadGraphModel()方法加载模型,但是这个方法只适用于TensorFlow.js中保存的模型,我们通过Python里model.save()方法保存,并用Converter转换的模型,必须用tfjs-converter依赖包中提供的loadGraphModel方法进行加载。
接着是程序完整的代码:
import * as tf from "@tensorflow/tfjs";
import loadGraphModel from "@tensorflow/tfjs-converter";
window.onload = async () =>
const resultElement = document.getElementById("result");
const MODEL_URL = "model.json";
•
console.time("Loading of model");
const model = await loadGraphModel(MODEL_URL);
console.timeEnd("Loading of model");
•
const test_data = tf.tensor([
[0.0],
[500.0],
[1000.0],
[1500.0],
[2500.0],
[6000.0],
[8000.0],
[10000.0],
[12000.0],
]);
tf.print(test_data);
console.time("Loading of model");
let outputs = model.execute(test_data);
console.timeEnd("execute:");
tf.print(outputs);
resultElement.innerText = outputs.toString();
;这里需要注意的是,由于我们的模型在预测时使用的是张量作为输入,因此,需要用tf.tensor()方法来返回经过包装的张量作为模型的输入。运行程序后,我们可以从浏览器开发者工具的控制台看到打印的调试信息:
[Violation] 'load' handler took 340ms
index.js:12 Loading of model: 67.19482421875 ms
print.ts:34 Tensor
[[0 ],
[500 ],
[1000 ],
[1500 ],
[2500 ],
[6000 ],
[8000 ],
[10000],
[12000]]
index.js:28 execute: 257.47607421875 ms
print.ts:34 Tensor
[[-1.7345995 ],
[90.0198822 ],
[159.9183655],
[210.0600586],
[260.0179443],
[347.4320068],
[357.5788269],
[367.5332947],
[377.4856262]]这里加载模型花费了 67ms,执行预测花费了 257ms,还是蛮长的。
import * as tf from "@tensorflow/tfjs";
import loadGraphModel from "@tensorflow/tfjs-converter";
window.onload = async () =>
// 新加入 webgl 硬件加速能力
tf.setBackend("webgl");
console.log(tf.getBackend());
// 打印当前后端信息
const resultElement = document.getElementById("result");
const MODEL_URL = "model.json";我们会看到控制台输出webgl代表TensorFlow.js成功启用了WebGL的加速能力,在其加速之下,我们在预测的时候速度会从257ms大幅度提升到131ms,多次预测时间由于权重和计算图已经加载到显存中速度会更快,达到78ms左右。
放眼未来,不管多困难,我们会继续推进基于WASM+SIMD/WebGPU引擎的落地、投入支持WebXR尤其是AR。其实,AR本质上是个机器学习问题。改名Meta的Facebook公司正在训练比GPT-3还大的模型,用于理解AR情况下的文本、图像和语音。模型训练出来了,如何在手机上落地进行推理,将是对前端智能化的重大考验,也是我们研究和储备技术的重要方向。
前端智能化技术应用篇
▐ 应用1:代码推荐-sophon
2019年,学术界以深度学习为代表的机器智能技术在不断突破,在工程界又有TabNine, aiXCoder在内的优秀的代码推荐服务涌现,但开始它们还都依赖于云端服务,对于代码安全不太友好,所以我们基于智能化的实践和探索做了一版前端代码推荐插件Sophon Code IntelliSense [10],期望通过代码补全代码的方式提升前端同学的研发效率。整个2021年,我们在C2C方向继续艰难爬坡。除了在深入优化模型,今年还花了很大气力完善整个工程基建、代码智能相关知识宣传和跟踪业界最新动态。
代码数据资产管理
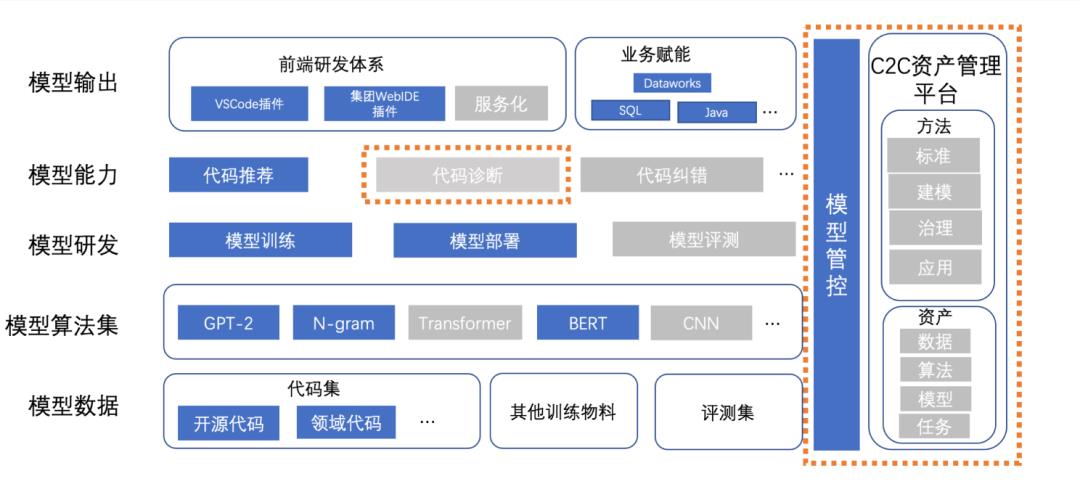
除了在代码推荐能力的持续优化之外,另一个重点是代码智能领域资产管理的建设。所有优秀的深度模型都离不开一份准确、标准的数据集,而一份这样的数据集在提供“评估基准”的同时,无疑会推动算法模型的持续优化。作为阿里大数据和AI平台的研发,我们知道应该怎样去获取数据、处理数据和管理数据,因此主动接过了代码智能相关的数据资产管理平台的建设工作。经过一年的探索和实践,已经针对数据集管理形成了一套基本成熟的方案。具体如下:
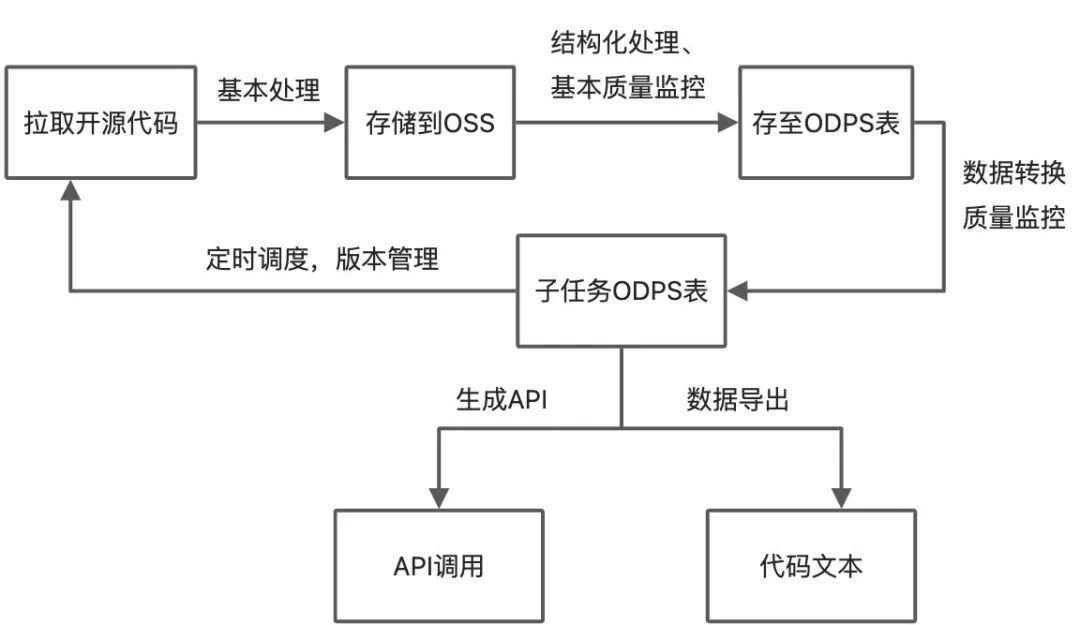
基于Git OpenAPI实现开源代码的获取,这里经常获取star数大于100的仓库代码,并经过处理(剔除非前端代码、删除测试代码、代码分块)之后代码文件上传到OSS上进行保存。
使用脚本获取OSS代码文件,进行结构化处理之后导入到ODPS表,同时会为ODPS表设置基本的DQC质量监控来保证数据的可用性。
新建SQL任务,从ODPS底表处理数据之后倒入到子任务的ODPS表,各子表有各个子任务对应的不同监控规则。
定时循环以上流程,按时间形成对应的版本进行存储、管理。
基于ODPS表数据,可生成对应的数据服务API提供使用方直接使用,或直接数据导出为文本文件方便模型读取。
以上方案构建了一套自动化的代码数据集管理方案,基于此方案可以很方便的实现代码智能相关的数据集资产管理。
今年,我们同时在代码智能领域进行了持续的探索,以目前业界整体发展看,我们判断整个代码智能推荐领域依然在未来一段时间内会长期处于缓慢上升的阶段,我们还是会基于不断产生的数据去优化模型。其次持续跟进整个资产管理平台的建设,期望帮助更多的团队去构建自己的代码推荐等服务,真正去提升前端的研发效率和质量。
▐ 应用2:设计稿生成代码-imgcook
imgcook是一个设计稿智能生成代码平台,能够将设计稿(Sketch、Figma、PSD、图片)一键生成可维护的前端代码(html、React、Vue、小程序、Flutter等)。imgcook也已经经历了4年的发展,当前已有33400+位用户在imgcook平台中上传了96200+个页面,累计生成了7007万+行代码,imgcook的D2C能力作为基础服务,被集团内部超10个BU和部门调用, 帮助前端开发者提升编码效率。

在这几年中,imgcook经历了几个大的发展阶段,有产品能力的不断增强、有智能化技术应用的持续探索、也有一些走过的曲折和弯路。3.0升级完善技术体系,并为天马模块研发提供一站式研发方案。同时,在前端智能化方向上深耕,在D2C各个技术分层探索智能化落地方案,提升智能化程度,部分模型实现了闭环迭代,解决D2C中代码语义化等问题。
这个阶段以D2C一站式研发和D2C智能化能力分层能力提升为主线,这里有个结合了一站式研发链路和智能化识别应用的演示流程:
imgcook 3.0 产品演示
3.0阶段在D2C各个技术分层都有探索新的智能化方案,包括图层解析阶段、物料识别阶段、布局识别阶段和逻辑生成阶段等,关于D2C的智能化能力提升方案和落地情况,可以查看AI助力90.4%双11模块代码生成 [11] 系列文章。
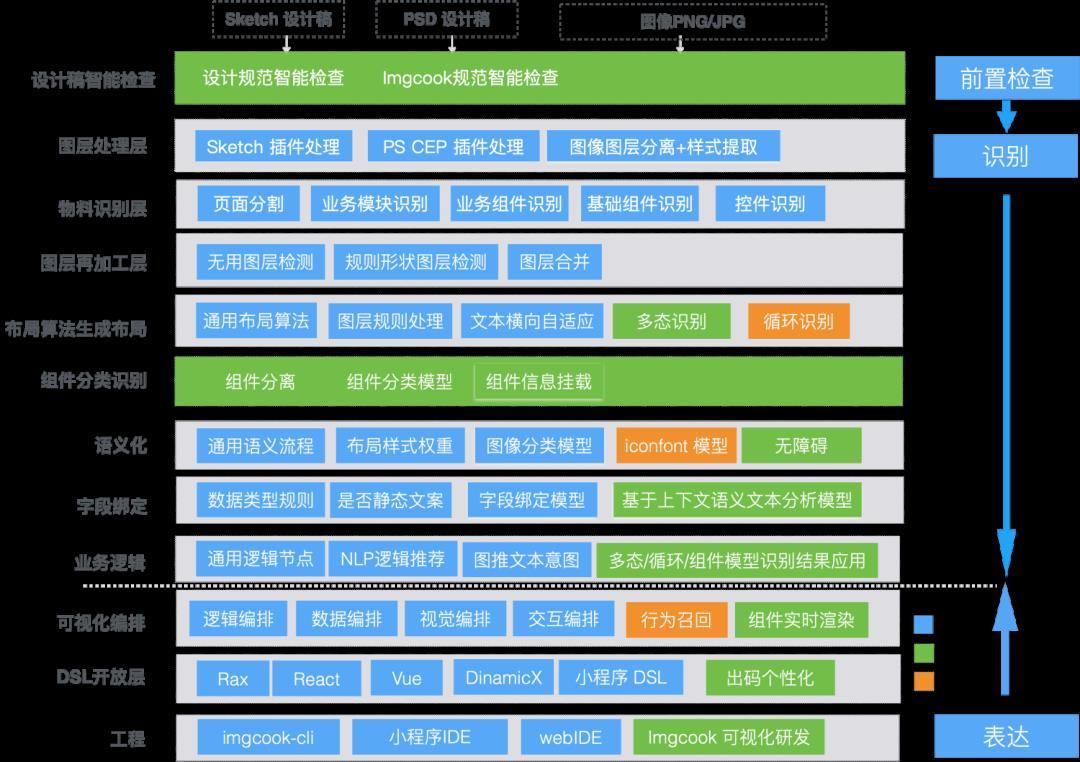
imgcook 3.0 技术框架
在从1.0到3.0的发展过程中,imgcook产品化能力、开放能力、营销链路研发解决方案、智能化方向的探索和落地在持续迭代,但依然有用户反馈:设计稿不规范、生成的代码结构不合理、样式冗余等。这背后的核心问题是什么?D2C核心流程只有3步,图层解析、布局分析、DSL转换生成代码。
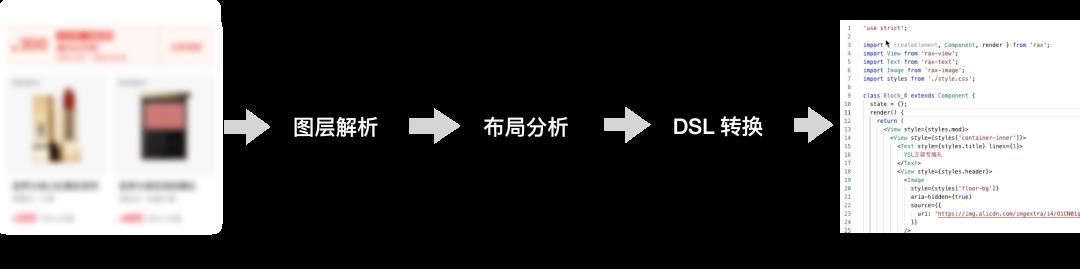
图层解析,Design to JSON,提取 Sketch、Figma、PSD、图片等类型设计稿中的元素信息,转换为没有层级结构的、绝对定位的JSON描述,主要包括:
节点类型,Div、Image、Text
样式信息,opacity、color、background、fontSize、border 等
布局分析,JSON to JSON,将没有层级结构的、绝对定位的JSON描述经过布局分析转换成有层级结构、相对定位的JSON描述,主要包括:
父子节点包含关系,DOM层级结构
兄弟节点间距,padding、margin等
布局样式,display、position等
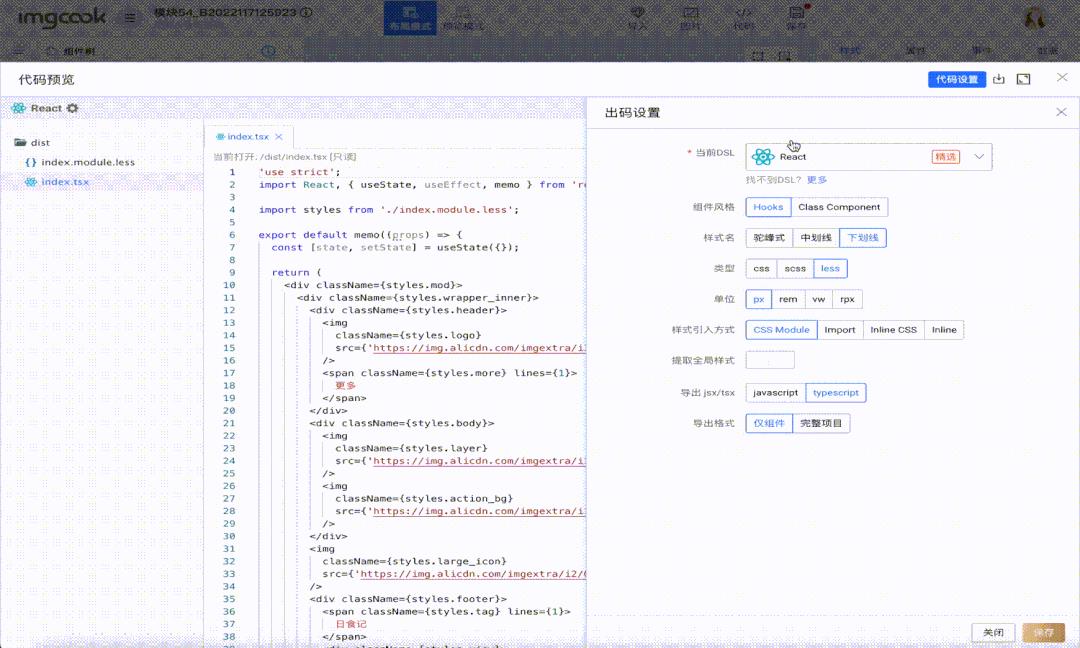
DSL 转换,JSON to Code,将具有符合代码结构和语义的JSON描述转换成前端代码,主要包括:
DSL 类型,React、Vue、android、小程序等
CSS 类型,less、css、scss 等
样式引入方式,内联样式、CSS 类名等
样式单位,px、rem、vw、rpx
作为imgcook用户,最关心的是结果,是生成代码的布局嵌套结构和布局样式,如果生成的布局结构不可用,随之业务逻辑生成以及其他智能识别语义增强等能力都不可用,配套的研发链路做的再完善也用不上。如果说在imgcook中投入的人力是100%,放在布局嵌套结构和布局样式的投入至少要80%。
在使用imgcook生成代码时,可能会得到不如预期的代码,出现一些细节问题,例如:
可以用CSS实现的直线、阴影、渐变等,在生成的代码中却用图片代替,导致产生大量不必要的图片资源等。
生成的布局出现过多不必要的绝对定位、没有合理使用Flex布局等。
生成的代码样式冗余、不符合自身项目的代码风格等。
这些都是用户最关心的问题,出现在代码生成过程中的各种细节里。所以过去一年里,我们把精力聚焦在核心能力以及用户体验上,从设计稿中的样式解析开始,清理了从Sketch to CSS的所有问题,在布局算法层将内部各层进行了解耦, 并加入了“宽高设定策略”, “flex布局”, “同层成组”等功能, 同时添加了“纠错层”来解决设计稿带来的部分噪音问题。另外提升了现有已比较成熟的模型的识别准确率,应用到设计稿解析和布局分析过程中。
代码准确率提升
图层解析:从设计稿中解析出样式
图层解析(Design to JSON)的工作是提取 Sketch、Figma、PSD、图片等类型设计稿中的元素信息,转换为没有层级结构的、绝对定位的 JSON 描述,主要包括:
节点类型,Div、Image、Text
样式信息,opacity、color、background、fontSize、border 等
但是 Sketch 中的样式描述与 CSS 中的样式描述是有很多差异的,另外,因为设计师仅关注视觉设计效果,设计方法和操作不受限制,会出现一些“不规范”的图层。需要梳理出每种情况的差异并解析出来。
例如设计师用Sketch来设计高保真的UI页面,需要使用Sketch中的一系列工具来完成,例如在工具栏( 图示区域2 )中添加 形状、图像、文本等不同类型的图层,在 Inspector 面板( 图示区域3 )中为图层添加样式。
这些各式各样的操作所设计的图层,要想转换成CSS样式,需要将Sketch的所有设计操作梳理出来并解析成CSS,但凡有缺失和解析错误,生成的代码就会有一些细节上的问题。
Sketch 设计面板
我们树立了Sketch中的设计样式与Web中CSS样式的差异和解析办法,以及一些还没有办法将设计稿解析出来的场景。
Sketch 中各种设计操作的测试用例
布局分析:生成布局树和布局样式
布局分析(JSON to JSON)的工作是将没有层级结构的、绝对定位的JSON描述经过布局分析转换成有层级结构、相对定位的JSON描述,主要包括:
父子节点包含关系,DOM层级结构
兄弟节点间距,padding、margin 等
布局样式,display、position 等
新版的布局算法主要解决了这几大问题:
设计不规范带来的布局噪音问题
部分设计稿中包含没有颜色的冗余节点, 高度或宽度为0的节点, 这些节点统一被称作“无表现元素”
flex 布局问题
空白区域都是用margin来填充,但有些场景用space-between或padding更合理
文本宽高设定问题
代码生成:DSL转换生成代码
DSL转换(JSON to Code)的工作是将具有符合代码结构和语义的JSON描述转换成前端代码,主要包括:
DSL类型,React、Vue、Android、小程序等
CSS类型,less、css、scss 等
样式引入方式,内联样式、CSS类名等
样式单位,px、rem、vw、rpx
在老版本的官方DSL中,仅支持各种DSL类型的转换,并没有CSS类型、样式引入方式、样式单位以及公共样式的生成。
▐ 智能化能力提升
在前面 3.0 阶段进行了大量的智能化方案探索后,已经沉淀了几个较为成熟的方案,和在D2C的链路中产生了实际应用价值的模型,过去一年主要是通过迭代闭环链路优化训练样本来提升模型的识别准确度。
文本/图片的语义深度学习模型识别能力增强,用于完善或提升背景图/碎图合并和代码语义化。
引入机器学习算法识别设计稿中的空白区域是“活动”(“FreeSpace”)的, 或是“静止”(“Margin/Padding”)的,用于布局样式生成,目前Beta版本内测中, 体验地址:https://www.imgcook.com/editor#/?from=flexboxLayout
▐ 产品体验优化
imgcook的产品能力比较健全完善,涉及的面比较广,例如:
设计稿解析方面包含:Sketch插件、PSD插件、Figma插件、Sketch文件上传解析、PSD文件上传解析、图片文件上传解析
协作管理方面包含:工作站团队/项目/页面管理、团队配置
开发者服务包含:自定义组件库、自定义编辑器、自定义画布、自定义DSL、自定义Plugin、自定义模型、自定义业务逻辑库、API接口服务开放
工程效率方面包含:imgcook命令行工具、VS CODE imgcook插件
官方维护的 10+ DSL包含:React、Rax、Vue、HTML5、微信小程序等
其他方面如:广场案例、编辑器
功能模块较多,蕴藏着的使用体验问题也比较多,例如Sketch插件中融合了代码导出与设计资源管理能力导致前端用户反馈多数界面用不着、仅支持Github登录对设计师不友好且登录速度慢、首次使用需要手动创建团队项目导致代码生成链路断层、模块很多时检索麻烦、以及生成代码时自适应、公共样式抽离等多样化需求。
在过去的一年中,从用户角度,将使用频率较高的功能模块进行了全面的体验优化,核心包括以下这些方面:
Sketch插件全新升级,交互体验和解析准确度都得到了很大提升;
支持多样化出码设置,例如可以选择类名风格、不同转换样式单位、样式引入方式、公共样式提取等;
编辑器体验全新升级,界面更清晰,交互更流畅,同时支持批量下载图片资源;
支持钉钉登录和第三方账号解绑;
首页更有效的信息表达;
工作站更方便有效的管理界面,支持设置常用团队,按我收藏的和我创建的筛选项目和模块等;
展示一些用户
▐ imgcook的业务应用:智能UI
商品的个性化推荐为业务带来了非常显著的增量,但是随着海量商品的上线,商品的数据化信息激增,个性化的商品推荐依旧有非常多的商品表达信息需要用户进行决策,一定程度上“过多的决策”会带来用户的流失。
所以非常需要通过智能UI(UI的个性化)来缩短用户的“购物决策时间”,在有限的空间中为用户展示他最关心的内容,为业务带来更多的增长可能。目前我们的UI个性化策略是:(通过识别用户的特征标签,划分出不同身份画像,设计不同的UI,个性化展示给用户)
通过将UI卡片拆解为“布局”和“物料”的概念,我们可以灵活的进行UI自由组装。再通过为不同的信息设计不同的UI样式,突出卡片中的信息,从而“引导”用户注意到他最关心的内容,为用户提供更好的UI体验。
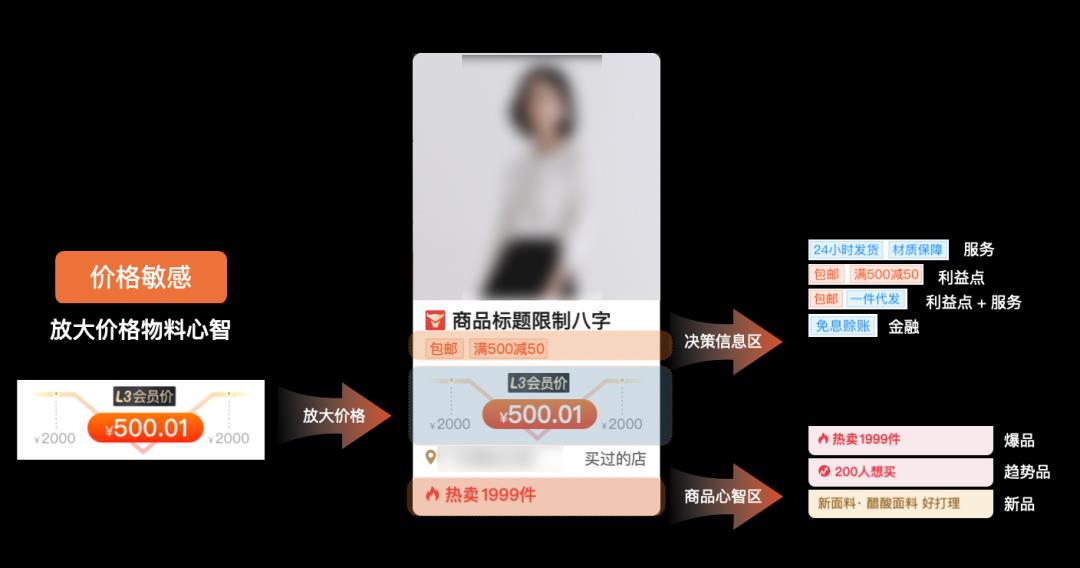
通过将UI设计拆解成元子化的模块,我们能够很灵活组装推品卡片,调整物料和布局,能够生成几十种甚至几百种UI组合方案。再通过结合算法的UI推荐能力,将我们的用户和UI进行精准匹配,从而提高卡片点击率。
智能UI在2021年表现依旧十分突出,在1688,淘系,猫超均得到了非常不错的业务效能提升。未来智能UI 将会覆盖更多的导购场景,通过智能UI的个性化UI表达,从技术侧为业务提效。对于智能UI我们有很宏伟的目标,希望通过整体的对接链路升级和产品化能力建设,将智能UI成为阿里内部“全网UI表达策略”,缩短用户筛选信息的决策时间,提高找货效率。
面向未来我们会继续在业务接入及效果提升、迭代升级技术能力两个方向努力:
业务效果提升:
商品素材物料全面接入:全量整合猫超商品素材物料并基于不同场景接入差异化素材
算法粒度能力升级:基于类目、人、商品维度算法深度挖掘
全链路能力升级。提高接入效率&进一步保证链路稳定性,将智能UI打造成技术基础能力
结合鲸幂后台能力&猫超定制能力进行智能UI产品化接入能力迁移
链路接入环境隔离&异常监控能力全面保障
新一年已经开始,imgcook将继续在三个方向发力:
业务赋能:深入结合阿里业务场景,无缝融入阿里研发流程形成各个业务自己的研发解决方案,帮助提高业务交付效率。
研发提效:聚焦代码生成可用性,对标内部专业前端对代码的可维护性要求,生成高可用代码。
夯实基础:沉淀高质量数据集,提升深度学习模型准确率,辅助提升生成代码可用性。
憧憬未来:UI智能化
2019年8月 ,我曾去过美国山景城Google总部,这次经历让我对智能UI有了一些全新的理解和认识,不仅仅是 UI 样式和信息表达的智能化,要穿透UI和信息去感知和理解用户的意图,用智能化手段协助用户实现其意图从而做到真正的AI User Interface。把用户和数字世界以及通过数字世界和物理世界穿越时空的连接,实际上用户操作的对象会从应用程序变成现实世界的服务。
服务业与工业、农业不同,它所提供的产品就是服务,这种服务具有无形性、非储存性、同时性和主动性。服务业的这“四性”特征,决定了服务业必须把标准化作为前提和基础。如果没有有效的服务标准,服务行为就无法数字化,服务行为无法数字化就难以用互联网技术为其构建声明式的操作界面,没有声明式的操作界面就会造成技术研发和对接成本高难以规模化,难以规模化就无法为用户提供充分的选择来帮助用户实现其意图。
如果深入考察这个问题,你会发现因为没有标准而引发的问题不仅仅在服务业,内容的标准化产生了RSS订阅能力,应用程序调用的标准化产生了唤端能力,ios还在应用程序的互操作性上制定标准,用Siri完成对应用背后提供的服务进行操作,比如阅读微信消息、打开健康码等。所以,实现UI智能化的前提是有脱离用户的服务操作能力和程序操作能力等,而这些能力就需要有标准来支持以提供规范的开放性降低研发和接入成本,从而实现规模化以实现用户意图。
针对习惯性的交互行为优化用户高频操作,大体上应用程序有两个技术路线,一种是自动化,另一种是智能化。自动化可以追溯到Windows上的批处理、Fireworks和 Photoshop提供的自动化以及Excel和游戏中的宏命令,由用户借助应用程序开放的能力编排触发条件、流程和输入输出。移动端上类似的自动化能力比如在抖音和B站进行视频一键下载等,尤其是借助Safari浏览器对应用程序分享、在浏览器中打开等能力巧妙实现一些繁琐却高频的用户操作。另一种是智能化技术路线,对比服务端计算,端上计算有隐私保护的巨大优势,可以更好地识别和理解用户行为,从而了解用户的习惯。通过各种实时数据进行训练把其中的模式抽象为“场景”,再根据用户在特定场景下的行为,就能够精确判断用户的习惯性高频操作并简化之。
你可能会想到一个问题:即便是基于端智能简化用户的习惯性高频操作,其本质上和自动化没有太大区别?是的,端智能只是智能生成并推荐了自动化操作而已,虽然有智能的成分,还是那句话:蜡烛怎么改进也无法变成灯泡。基于端智能简化用户习惯性高频操作的技术基础是什么?还是自动化和依赖于应用程序有限开放的功能,遇到一些“自我”的APP迫使用户必须打开应用使用其功能,自动化就显得束手无策了。我认为未来应该思考如何才能用一个数字化和智能化的助手替代用户做一些繁琐的事情,从而让用户使用终端的时候更加高效。
在一个结构性复杂的系统中,复杂度不会消失只会转移,因此,在面对结构性复杂的系统问题时,要想办法把复杂度转移到合理可控的区域。对于用户使用移动终端来说,一样是结构性复杂的。从移动操作系统到移动应用,由于商业和市场考量只能围绕通用性做妥协,而不会针对个体做深度的个性化,这样体验虽然能极致化但成本太高。比如在拱墅区爆发疫情的期间,我每天都要打开今日头条、点击抗疫tab、滑动到杭州疫情并点击,然后查找杭州疫情的动态,每天早晚各一次并期待着有好消息让我解除居家吃方便面的苦日子。在这个动态变化的世界中围绕动态变化的我们,习惯性的高频操作也是不断变化的,如果助手APP能够像秘书一样理解世界、理解我、理解我面对的问题,就能够在我面对这种结构性复杂的局面时提供真正有效的协助。
助手APP的效用和其理解的能力成正比,理解和端智能的能力成正比,端智能的能力和模型算法的能力及其训练使用的用户数据量成正比,可用的用户数据量和对用户隐私保护的能力成正比,模型算法能力和端上算力成正比,所以最终影响助手APP效用的关键是隐私保护和端上算力。
有了隐私和算力的保障,应该怎样去构建一个助手APP去协助用户?可以参考马斯洛需求层次结构:生理、安全、社交需要、尊重和自我实现。简单做个类比,今天获取信息已经像吃饭、睡觉一样成为生理需求的一部分,而安全则是在信息获取中的特殊和紧急部分。因此,做好生理和安全的简单需求是做好助手APP并提供有效协助的第一步。有了生理和安全的有效协助,我们的助手APP就会获取协助对象的信任,这一点非常重要。有了信任的基础,助手APP在必要时提醒用户给家人打个电话联络一下感情,才不会让其觉得突兀,反而会让用户愈发觉得助手APP是有温度和感情的,而不是个冷冰冰的Robot。从熟人社交(如家人)开始分界,随着愈发向陌生人社交、尊重和自我实现迈进,用户本地和个人的信息愈发显得不足,助手APP需要更多外部的信息输入和对外部常识、知识的理解,才能够有效协助用户解决这些高层次复杂需求。不管怎么说,有了信任的基础,用户就会像给词典应用或输入法添加词库一样自然地接受给助手APP添加外部信息和尝试、知识。(这些外部数据的透明和安全依然非常重要)
当然,解决用户高层次复杂需求时,外部输入只是一部分,另一部分是助手APP会逐渐人格化。一旦我们能够设计开发出像能干的私人秘书一般的助手APP,用户的终端设备也会因为交互的改变而发生巨大的变化。为什么交互会改变?因为用户不必再和冷冰冰的机器和UI打交道了。用户会和自己的“私人秘书”助手APP进行交互,而助手APP又是人格化的,所以用户可以用更加自然的语言甚至眼神来跟助手APP交流。此外,由于助手APP本质上是应用程序,所以其跟数字世界打交道的方式会更加直接和高效,不存在把二进制数据用协议解析成文本、图片、音频、视频等等,直接用二进制进行交互。由于直接和高效的交互,用户终端设备的计算消耗会下降,除了不需要对数据进行解析处理外,省去了渲染UI 、听取用户输入、处理用户输入、响应输出等过程,这对于用户终端设备的小型化和可穿戴是极大的利好。
综上所述,UI智能化会朝着没有UI的方向演进,应用会向着服务化和二进制输入输出演进,移动操作系统会进化为只有一个APP —— 用户的私人智能体,其它APP被服务化并和该智能体进行二进制交互,而用户则会回归自然、社会和生活。未来,大家可能只佩戴眼镜或耳机就可以完成今天手机上的大部分功能。作为实现用户交互的我们,前端工程师在智能化能力建设和储备上不断提升,在新的技术变革到来时,我们就是构建UI智能化的主力军。
团队介绍
我们是阿里巴巴-大淘宝技术-导购和营销产品(原频道与D2C智能团队),也是阿里经济体前端委员会智能化方向的核心团队,隶属于大淘宝技术(大淘宝技术,一支致力于成为全球最懂商业的技术创新团队,旗下包含淘宝技术、天猫技术等团队和业务,是一支是具有商业和技术双重基因的螺旋体)。
我们在 「杭州阿里巴巴西溪园区」 办公,
我们的定位是「用诗人的浪漫和科学家的严谨打造最懂 AI 的 smart and international 的前端团队」,
我们的使命是「前端智能让业务创新更高效」。
✿ 拓展阅读


作者|霸天、欣余、灝阳、苏川、继风、闻梦、缺月、妙净、甄子
编辑|橙子君

以上是关于阿里前端智能化技术探索和未来思考的主要内容,如果未能解决你的问题,请参考以下文章